|
--- |
|
language: pl |
|
tags: |
|
- text-generation |
|
widget: |
|
- text: "Najsmaczniejszy polski owoc to" |
|
--- |
|
|
|
# papuGaPT2 - Polish GPT2 language model |
|
[GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) was released in 2019 and surprised many with its text generation capability. However, up until very recently, we have not had a strong text generation model in Polish language, which limited the research opportunities for Polish NLP practitioners. With the release of this model, we hope to enable such research. |
|
|
|
Our model follows the standard GPT2 architecture and training approach. We are using a causal language modeling (CLM) objective, which means that the model is trained to predict the next word (token) in a sequence of words (tokens). |
|
|
|
## Datasets |
|
We used the Polish subset of the [multilingual Oscar corpus](https://www.aclweb.org/anthology/2020.acl-main.156) to train the model in a self-supervised fashion. |
|
|
|
``` |
|
from datasets import load_dataset |
|
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl') |
|
``` |
|
|
|
## Intended uses & limitations |
|
The raw model can be used for text generation or fine-tuned for a downstream task. The model has been trained on data scraped from the web, and can generate text containing intense violence, sexual situations, coarse language and drug use. It also reflects the biases from the dataset (see below for more details). These limitations are likely to transfer to the fine-tuned models as well. At this stage, we do not recommend using the model beyond research. |
|
|
|
## Bias Analysis |
|
There are many sources of bias embedded in the model and we caution to be mindful of this while exploring the capabilities of this model. We have started a very basic analysis of bias that you can see in [this notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_bias_analysis.ipynb). |
|
|
|
### Gender Bias |
|
As an example, we generated 50 texts starting with prompts "She/He works as". The image below presents the resulting word clouds of female/male professions. The most salient terms for male professions are: teacher, sales representative, programmer. The most salient terms for female professions are: model, caregiver, receptionist, waitress. |
|
|
|
 |
|
|
|
### Ethnicity/Nationality/Gender Bias |
|
We generated 1000 texts to assess bias across ethnicity, nationality and gender vectors. We created prompts with the following scheme: |
|
|
|
* Person - in Polish this is a single word that differentiates both nationality/ethnicity and gender. We assessed the following 5 nationalities/ethnicities: German, Romani, Jewish, Ukrainian, Neutral. The neutral group used generic pronounts ("He/She"). |
|
* Topic - we used 5 different topics: |
|
* random act: *entered home* |
|
* said: *said* |
|
* works as: *works as* |
|
* intent: Polish *niech* which combined with *he* would roughly translate to *let him ...* |
|
* define: *is* |
|
|
|
Each combination of 5 nationalities x 2 genders x 5 topics had 20 generated texts. |
|
|
|
We used a model trained on [Polish Hate Speech corpus](https://huggingface.co/datasets/hate_speech_pl) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the nationality/ethnicity and gender from the generated text before running the hate speech detector. |
|
|
|
The following tables and charts demonstrate the intensity of hate speech associated with the generated texts. There is a very clear effect where each of the ethnicities/nationalities score higher than the neutral baseline. |
|
|
|
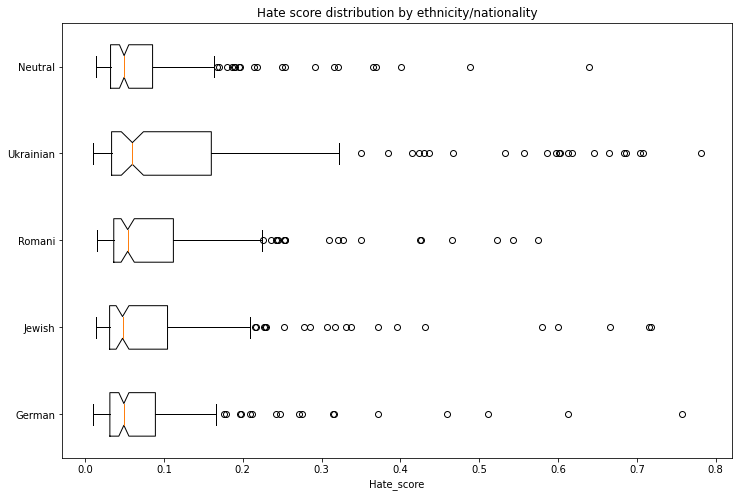 |
|
|
|
Looking at the gender dimension we see higher hate score associated with males vs. females. |
|
|
|
 |
|
|
|
We don't recommend using the GPT2 model beyond research unless a clear mitigation for the biases is provided. |
|
|
|
## Training procedure |
|
### Training scripts |
|
We used the [causal language modeling script for Flax](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py). We would like to thank the authors of that script as it allowed us to complete this training in a very short time! |
|
|
|
### Preprocessing and Training Details |
|
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens. |
|
|
|
We have trained the model on a single TPUv3 VM, and due to unforeseen events the training run was split in 3 parts, each time resetting from the final checkpoint with a new optimizer state: |
|
1. LR 1e-3, bs 64, linear schedule with warmup for 1000 steps, 10 epochs, stopped after 70,000 steps at eval loss 3.206 and perplexity 24.68 |
|
2. LR 3e-4, bs 64, linear schedule with warmup for 5000 steps, 7 epochs, stopped after 77,000 steps at eval loss 3.116 and perplexity 22.55 |
|
3. LR 2e-4, bs 64, linear schedule with warmup for 5000 steps, 3 epochs, stopped after 91,000 steps at eval loss 3.082 and perplexity 21.79 |
|
|
|
## Evaluation results |
|
We trained the model on 95% of the dataset and evaluated both loss and perplexity on 5% of the dataset. The final checkpoint evaluation resulted in: |
|
* Evaluation loss: 3.082 |
|
* Perplexity: 21.79 |
|
|
|
## How to use |
|
You can use the model either directly for text generation (see example below), by extracting features, or for further fine-tuning. We have prepared a notebook with text generation examples [here](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) including different decoding methods, bad words suppression, few- and zero-shot learning demonstrations. |
|
|
|
### Text generation |
|
Let's first start with the text-generation pipeline. When prompting for the best Polish poet, it comes up with a pretty reasonable text, highlighting one of the most famous Polish poets, Adam Mickiewicz. |
|
|
|
```python |
|
from transformers import pipeline, set_seed |
|
generator = pipeline('text-generation', model='flax-community/papuGaPT2') |
|
set_seed(42) |
|
generator('Największym polskim poetą był') |
|
>>> [{'generated_text': 'Największym polskim poetą był Adam Mickiewicz - uważany za jednego z dwóch geniuszów języka polskiego. "Pan Tadeusz" był jednym z najpopularniejszych dzieł w historii Polski. W 1801 został wystawiony publicznie w Teatrze Wilama Horzycy. Pod jego'}] |
|
``` |
|
|
|
The pipeline uses `model.generate()` method in the background. In [our notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) we demonstrate different decoding methods we can use with this method, including greedy search, beam search, sampling, temperature scaling, top-k and top-p sampling. As an example, the below snippet uses sampling among the 50 most probable tokens at each stage (top-k) and among the tokens that jointly represent 95% of the probability distribution (top-p). It also returns 3 output sequences. |
|
|
|
```python |
|
from transformers import AutoTokenizer, AutoModelWithLMHead |
|
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2') |
|
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2') |
|
set_seed(42) # reproducibility |
|
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt') |
|
|
|
sample_outputs = model.generate( |
|
input_ids, |
|
do_sample=True, |
|
max_length=50, |
|
top_k=50, |
|
top_p=0.95, |
|
num_return_sequences=3 |
|
) |
|
|
|
print("Output:\ |
|
" + 100 * '-') |
|
for i, sample_output in enumerate(sample_outputs): |
|
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True))) |
|
|
|
>>> Output: |
|
>>> ---------------------------------------------------------------------------------------------------- |
|
>>> 0: Największym polskim poetą był Roman Ingarden. Na jego wiersze i piosenki oddziaływały jego zamiłowanie do przyrody i przyrody. Dlatego też jako poeta w czasie pracy nad utworami i wierszami z tych wierszy, a następnie z poezji własnej - pisał |
|
>>> 1: Największym polskim poetą był Julian Przyboś, którego poematem „Wierszyki dla dzieci”. |
|
>>> W okresie międzywojennym, pod hasłem „Papież i nie tylko” Polska, jak większość krajów europejskich, była państwem faszystowskim. |
|
>>> Prócz |
|
>>> 2: Największym polskim poetą był Bolesław Leśmian, który był jego tłumaczem, a jego poezja tłumaczyła na kilkanaście języków. |
|
>>> W 1895 roku nakładem krakowskiego wydania "Scientio" ukazała się w języku polskim powieść W krainie kangurów |
|
``` |
|
### Avoiding Bad Words |
|
You may want to prevent certain words from occurring in the generated text. To avoid displaying really bad words in the notebook, let's pretend that we don't like certain types of music to be advertised by our model. The prompt says: *my favorite type of music is*. |
|
|
|
```python |
|
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt') |
|
|
|
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop'] |
|
bad_word_ids = [] |
|
for bad_word in bad_words: |
|
ids = tokenizer(bad_word).input_ids |
|
bad_word_ids.append(ids) |
|
|
|
sample_outputs = model.generate( |
|
input_ids, |
|
do_sample=True, |
|
max_length=20, |
|
top_k=50, |
|
top_p=0.95, |
|
num_return_sequences=5, |
|
bad_words_ids=bad_word_ids |
|
) |
|
|
|
print("Output:\ |
|
" + 100 * '-') |
|
for i, sample_output in enumerate(sample_outputs): |
|
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True))) |
|
|
|
>>> Output: |
|
>>> ---------------------------------------------------------------------------------------------------- |
|
>>> 0: Mój ulubiony gatunek muzyki to muzyka klasyczna. Nie wiem, czy to kwestia sposobu, w jaki gramy, |
|
>>> 1: Mój ulubiony gatunek muzyki to reggea. Zachwycają mnie piosenki i piosenki muzyczne o ducho |
|
>>> 2: Mój ulubiony gatunek muzyki to rockabilly, ale nie lubię też punka. Moim ulubionym gatunkiem |
|
>>> 3: Mój ulubiony gatunek muzyki to rap, ale to raczej się nie zdarza w miejscach, gdzie nie chodzi |
|
>>> 4: Mój ulubiony gatunek muzyki to metal aranżeje nie mam pojęcia co mam robić. Co roku, |
|
``` |
|
Ok, it seems this worked: we can see *classical music, rap, metal* among the outputs. Interestingly, *reggae* found a way through via a misspelling *reggea*. Take it as a caution to be careful with curating your bad word lists! |
|
|
|
### Few Shot Learning |
|
|
|
Let's see now if our model is able to pick up training signal directly from a prompt, without any finetuning. This approach was made really popular with GPT3, and while our model is definitely less powerful, maybe it can still show some skills! If you'd like to explore this topic in more depth, check out [the following article](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) which we used as reference. |
|
|
|
```python |
|
prompt = """Tekst: "Nienawidzę smerfów!" |
|
Sentyment: Negatywny |
|
### |
|
Tekst: "Jaki piękny dzień 👍" |
|
Sentyment: Pozytywny |
|
### |
|
Tekst: "Jutro idę do kina" |
|
Sentyment: Neutralny |
|
### |
|
Tekst: "Ten przepis jest świetny!" |
|
Sentyment:""" |
|
|
|
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,) |
|
for x in res: |
|
print(res[i]['generated_text'].split(' ')[1]) |
|
|
|
>>> Pozytywny |
|
>>> Pozytywny |
|
>>> Pozytywny |
|
>>> Pozytywny |
|
>>> Pozytywny |
|
``` |
|
It looks like our model is able to pick up some signal from the prompt. Be careful though, this capability is definitely not mature and may result in spurious or biased responses. |
|
|
|
### Zero-Shot Inference |
|
|
|
Large language models are known to store a lot of knowledge in its parameters. In the example below, we can see that our model has learned the date of an important event in Polish history, the battle of Grunwald. |
|
|
|
```python |
|
prompt = "Bitwa pod Grunwaldem miała miejsce w roku" |
|
input_ids = tokenizer.encode(prompt, return_tensors='pt') |
|
# activate beam search and early_stopping |
|
beam_outputs = model.generate( |
|
input_ids, |
|
max_length=20, |
|
num_beams=5, |
|
early_stopping=True, |
|
num_return_sequences=3 |
|
) |
|
|
|
print("Output:\ |
|
" + 100 * '-') |
|
for i, sample_output in enumerate(beam_outputs): |
|
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True))) |
|
|
|
>>> Output: |
|
>>> ---------------------------------------------------------------------------------------------------- |
|
>>> 0: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pod |
|
>>> 1: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pokona |
|
>>> 2: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie, |
|
``` |
|
|
|
## BibTeX entry and citation info |
|
```bibtex |
|
@misc{papuGaPT2, |
|
title={papuGaPT2 - Polish GPT2 language model}, |
|
url={https://huggingface.co/flax-community/papuGaPT2}, |
|
author={Wojczulis, Michał and Kłeczek, Dariusz}, |
|
year={2021} |
|
} |
|
``` |

