
Paper: Coming soon
Model: URM-LLaMa-3.1-8B
- Fine-tuned from Skywork-Reward-Llama-3.1-8B
Architecture
Brief
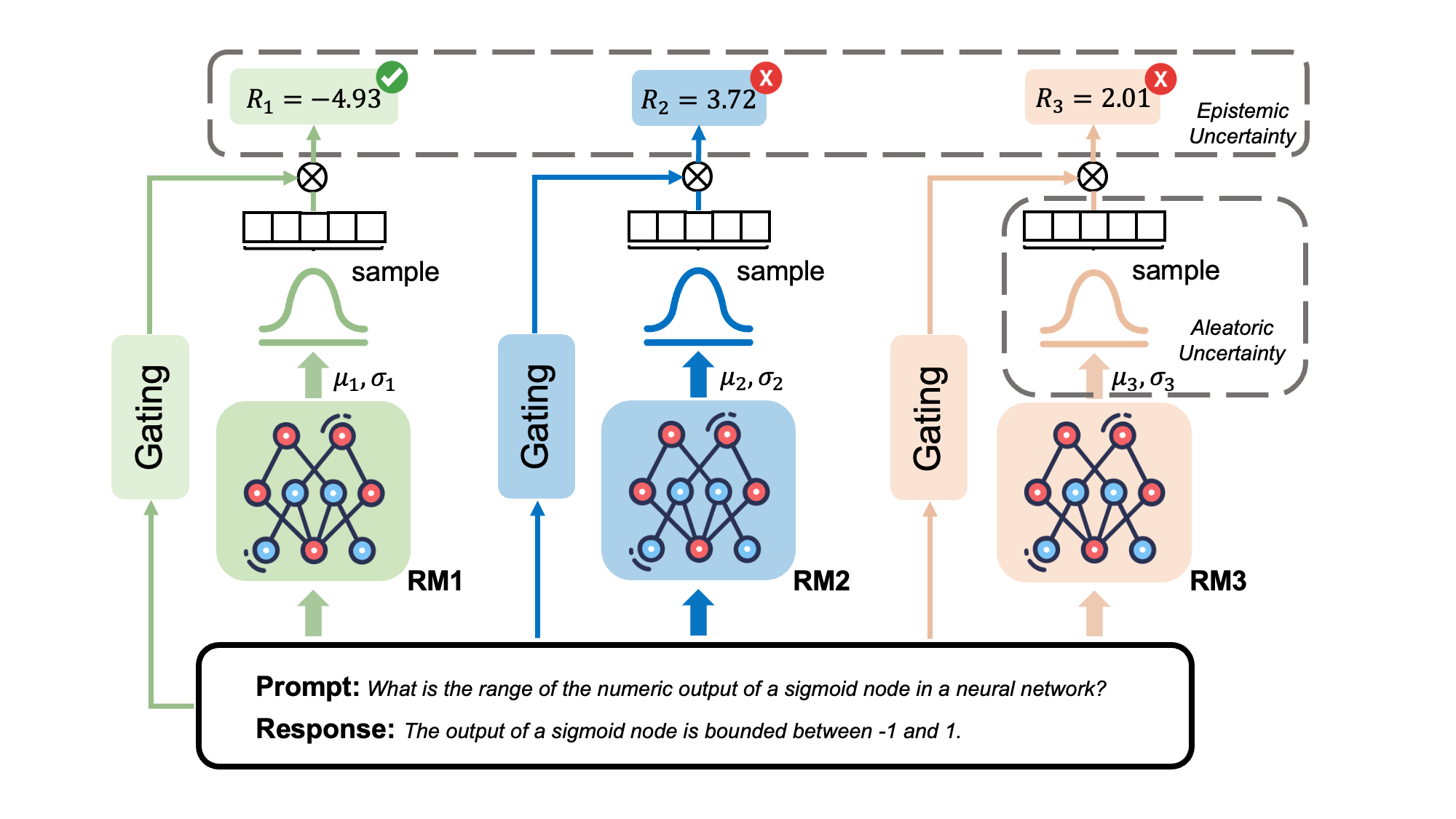
URM-LLaMa-3.1-8B is an uncertain-aware reward model. This RM consists of a base model and an uncertainty-aware and attribute-specific value head. The base model of this RM is from Skywork-Reward-Llama-3.1-8B.
URM involves two-stage training: 1. attributes regression and 2. gating layer learning.
Attribute Regression
Dataset: HelpSteer2
During training, instead of multi-attributes scores, outputs of the uncertainty-aware value head are parameters of a normal distribution, from which scores are sampled. Then we run regression on the outputs with the labels to train the value head. To enable gradient back-propagation, reparameterization technique is used.
Gating Layer Learning
Dataset: Skywork-Reward-Preference-80K-v0.1
Inspired by ArmoRM, we learn a gating layer to combine the multi-attribute scores instead of the fixed weights in SteerLM-RM. Learning objective of the gating layer is to prioritize chosen responses over rejected responses through the BT loss. We only use the five attributes from HelpSteer2: Helpfulness, Correctness, Coherence, Complexity and Verbosity. During this process, the value head and base model are kept frozen.
Usage
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "LxzGordon/URM-LLaMa-3.1-8B"
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
device_map='auto',
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "What is the range of the numeric output of a sigmoid node in a neural network?"
response1 = "The output of a sigmoid node is bounded between -1 and 1."
response2 = "The output of a sigmoid node is bounded between 0 and 1."
resp1 = [{"role": "user", "content": prompt}, {"role": "assistant", "content": response1}]
resp2 = [{"role": "user", "content": prompt}, {"role": "assistant", "content": response2}]
# Format and tokenize the conversations
resp1 = tokenizer.apply_chat_template(resp1, tokenize=False)
resp2 = tokenizer.apply_chat_template(resp2, tokenize=False)
resp1 = tokenizer(resp1, return_tensors="pt").to(model.device)
resp2 = tokenizer(resp2, return_tensors="pt").to(model.device)
with torch.no_grad():
score1 = model(resp1['input_ids'],attention_mask=resp1['attention_mask']).logits[0][0].item()
score2 = model(resp2['input_ids'],attention_mask=resp2['attention_mask']).logits[0][0].item()
print(score1,score2)
# Response 1 score: 2.3285412788391113, Response 2 score: 12.438033103942871
Reference
Coming soon
- Downloads last month
- 260