
Qwen-VL 🤖 | 🤗 | Qwen-VL-Chat 🤖 | 🤗 | Demo | Report | Discord
中文 | English
**Qwen-VL** 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型的特点包括:
- **强大的性能**:在四大类多模态任务的标准英文测评中(Zero-shot Captioning/VQA/DocVQA/Grounding)上,均取得同等通用模型大小下最好效果;
- **多语言对话模型**:天然支持英文、中文等多语言对话,端到端支持图片里中英双语的长文本识别;
- **多图交错对话**:支持多图输入和比较,指定图片问答,多图文学创作等;
- **首个支持中文开放域定位的通用模型**:通过中文开放域语言表达进行检测框标注;
- **细粒度识别和理解**:相比于目前其它开源LVLM使用的224分辨率,Qwen-VL是首个开源的448分辨率的LVLM模型。更高分辨率可以提升细粒度的文字识别、文档问答和检测框标注。

目前,我们提供了 Qwen-VL 系列的两个模型:
- Qwen-VL: Qwen-VL 以 Qwen-7B 的预训练模型作为语言模型的初始化,并以 [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip) 作为视觉编码器的初始化,中间加入单层随机初始化的 cross-attention,经过约1.5B的图文数据训练得到。最终图像输入分辨率为448。
- Qwen-VL-Chat: 在 Qwen-VL 的基础上,我们使用对齐机制打造了基于大语言模型的视觉AI助手Qwen-VL-Chat,它支持更灵活的交互方式,包括多图、多轮问答、创作等能力。
## 评测
我们从两个角度评测了两个模型的能力:
1. 在**英文标准 Benchmark** 上评测模型的基础任务能力。目前评测了四大类多模态任务:
- Zero-shot Captioning: 评测模型在未见过数据集上的零样本图片描述能力;
- General VQA: 评测模型的通用问答能力,例如判断题、颜色、个数、类目等问答能力;
- Text-based VQA:评测模型对于图片中文字相关的识别/问答能力,例如文档问答、图表问答、文字问答等;
- Referring Expression Compression:评测模型给定物体描述画检测框的能力;
2. **试金石 (TouchStone)**:为了评测模型整体的图文对话能力和人类对齐水平。我们为此构建了一个基于 GPT4 打分来评测 LVLM 模型的 Benchmark:TouchStone。在 TouchStone-v0.1 中:
- 评测基准总计涵盖 300+张图片、800+道题目、27个类别。包括基础属性问答、人物地标问答、影视作品问答、视觉推理、反事实推理、诗歌创作、故事写作,商品比较、图片解题等**尽可能广泛的类别**。
- 为了弥补目前 GPT4 无法直接读取图片的缺陷,我们给所有的带评测图片提供了**人工标注的充分详细描述**,并且将图片的详细描述、问题和模型的输出结果一起交给 GPT4 打分。
- 评测同时包含英文版本和中文版本。
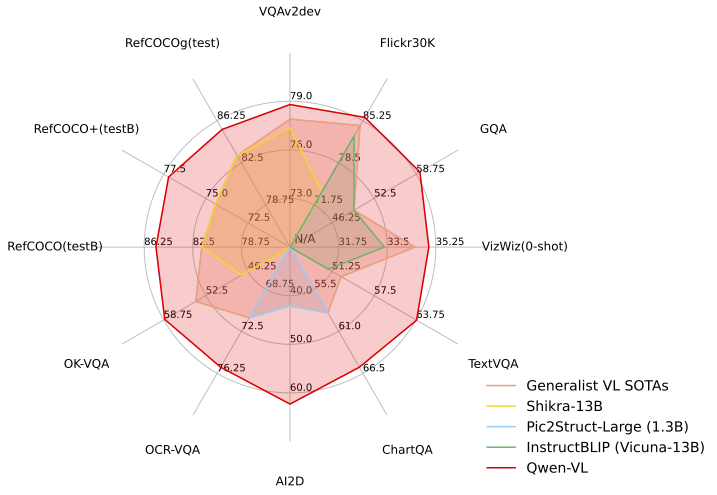
评测结果如下:
Qwen-VL在多个VL任务上相比目前SOTA的Generalist Models都有明显优势,并且在能力范围也覆盖更加全面。
### 零样本图像描述生成(Zero-shot Image Caption) 及 通用视觉问答(General VQA)
| Model type |
Model |
Zero-shot Captioning |
General VQA |
| NoCaps |
Flickr30K |
VQAv2dev |
OK-VQA |
GQA |
SciQA-Img
(0-shot) |
VizWiz
(0-shot) |
Generalist
Models |
Flamingo-9B |
- |
61.5 |
51.8 |
44.7 |
- |
- |
28.8 |
| Flamingo-80B |
- |
67.2 |
56.3 |
50.6 |
- |
- |
31.6 |
| Unified-IO-XL |
100.0 |
- |
77.9 |
54.0 |
- |
- |
- |
| Kosmos-1 |
- |
67.1 |
51.0 |
- |
- |
- |
29.2 |
| Kosmos-2 |
- |
66.7 |
45.6 |
- |
- |
- |
- |
| BLIP-2 (Vicuna-13B) |
103.9 |
71.6 |
65.0 |
45.9 |
32.3 |
61.0 |
19.6 |
| InstructBLIP (Vicuna-13B) |
121.9 |
82.8 |
- |
- |
49.5 |
63.1 |
33.4 |
| Shikra (Vicuna-13B) |
- |
73.9 |
77.36 |
47.16 |
- |
- |
- |
| Qwen-VL (Qwen-7B) |
121.4 |
85.8 |
78.8 |
58.6 |
59.3 |
67.1 |
35.2 |
| Qwen-VL-Chat |
120.2 |
81.0 |
78.2 |
56.6 |
57.5 |
68.2 |
38.9 |
Previous SOTA
(Per Task Fine-tuning) |
- |
127.0
(PALI-17B) |
84.5
(InstructBLIP
-FlanT5-XL) |
86.1
(PALI-X
-55B) |
66.1
(PALI-X
-55B) |
72.1
(CFR) |
92.53
(LLaVa+
GPT-4) |
70.9
(PALI-X
-55B) |
- 在 Zero-shot Captioning 中,Qwen-VL 在 Flickr30K 数据集上取得了 **SOTA** 的结果,并在 Nocaps 数据集上取得了和 InstructBlip 可竞争的结果。
- 在 General VQA 中,Qwen-VL 取得了 LVLM 模型同等量级和设定下 **SOTA** 的结果。
### 文本导向的视觉问答(Text-oriented VQA)
| Model type |
Model |
TextVQA |
DocVQA |
ChartQA |
AI2D |
OCR-VQA |
| Generalist Models |
BLIP-2 (Vicuna-13B) |
42.4 |
- |
- |
- |
- |
| InstructBLIP (Vicuna-13B) |
50.7 |
- |
- |
- |
- |
| mPLUG-DocOwl (LLaMA-7B) |
52.6 |
62.2 |
57.4 |
- |
- |
| Pic2Struct-Large (1.3B) |
- |
76.6 |
58.6 |
42.1 |
71.3 |
| Qwen-VL (Qwen-7B) |
63.8 |
65.1 |
65.7 |
62.3 |
75.7 |
Specialist SOTAs
(Specialist/Finetuned) |
PALI-X-55B (Single-task FT)
(Without OCR Pipeline) |
71.44 |
80.0 |
70.0 |
81.2 |
75.0 |
- 在文字相关的识别/问答评测上,取得了当前规模下通用 LVLM 达到的最好结果。
- 分辨率对上述某几个评测非常重要,大部分 224 分辨率的开源 LVLM 模型无法完成以上评测,或只能通过切图的方式解决。Qwen-VL 将分辨率提升到 448,可以直接以端到端的方式进行以上评测。Qwen-VL 在很多任务上甚至超过了 1024 分辨率的 Pic2Struct-Large 模型。
### 细粒度视觉定位(Referring Expression Comprehension)
| Model type |
Model |
RefCOCO |
RefCOCO+ |
RefCOCOg |
GRIT |
| val |
test-A |
test-B |
val |
test-A |
test-B |
val-u |
test-u |
refexp |
| Generalist Models |
GPV-2 |
- |
- |
- |
- |
- |
- |
- |
- |
51.50 |
| OFA-L* |
79.96 |
83.67 |
76.39 |
68.29 |
76.00 |
61.75 |
67.57 |
67.58 |
61.70 |
| Unified-IO |
- |
- |
- |
- |
- |
- |
- |
- |
78.61 |
| VisionLLM-H |
|
86.70 |
- |
- |
- |
- |
- |
- |
- |
| Shikra-7B |
87.01 |
90.61 |
80.24 |
81.60 |
87.36 |
72.12 |
82.27 |
82.19 |
69.34 |
| Shikra-13B |
87.83 |
91.11 |
81.81 |
82.89 |
87.79 |
74.41 |
82.64 |
83.16 |
69.03 |
| Qwen-VL-7B |
89.36 |
92.26 |
85.34 |
83.12 |
88.25 |
77.21 |
85.58 |
85.48 |
78.22 |
| Qwen-VL-7B-Chat |
88.55 |
92.27 |
84.51 |
82.82 |
88.59 |
76.79 |
85.96 |
86.32 |
- |
Specialist SOTAs
(Specialist/Finetuned) |
G-DINO-L |
90.56 |
93.19 |
88.24 |
82.75 |
88.95 |
75.92 |
86.13 |
87.02 |
- |
| UNINEXT-H |
92.64 |
94.33 |
91.46 |
85.24 |
89.63 |
79.79 |
88.73 |
89.37 |
- |
| ONE-PEACE |
92.58 |
94.18 |
89.26 |
88.77 |
92.21 |
83.23 |
89.22 |
89.27 |
- |
- 在定位任务上,Qwen-VL 全面超过 Shikra-13B,取得了目前 Generalist LVLM 模型上在 Refcoco 上的 **SOTA**。
- Qwen-VL 并没有在任何中文定位数据上训练过,但通过中文 Caption 数据和 英文 Grounding 数据的训练,可以 Zero-shot 泛化出中文 Grounding 能力。
我们提供了以上**所有**评测脚本以供复现我们的实验结果。请阅读 [eval_mm/EVALUATION.md](eval_mm/EVALUATION.md) 了解更多信息。
### Chat 能力测评
TouchStone 是一个基于 GPT4 打分来评测 LVLM 模型的图文对话能力和人类对齐水平的基准。它涵盖了 300+张图片、800+道题目、27个类别,包括基础属性、人物地标、视觉推理、诗歌创作、故事写作、商品比较、图片解题等**尽可能广泛的类别**。关于 TouchStone 的详细介绍,请参考[touchstone/README_CN.md](touchstone/README_CN.md)了解更多信息。
#### 英文版本测评
| Model | Score |
|---------------|-------|
| PandaGPT | 488.5 |
| MiniGPT4 | 531.7 |
| InstructBLIP | 552.4 |
| LLaMA-AdapterV2 | 590.1 |
| mPLUG-Owl | 605.4 |
| LLaVA | 602.7 |
| Qwen-VL-Chat | 645.2 |
#### 中文版本测评
| Model | Score |
|---------------|-------|
| VisualGLM | 247.1 |
| Qwen-VL-Chat | 401.2 |
Qwen-VL-Chat 模型在中英文的对齐评测中均取得当前 LVLM 模型下的最好结果。
## 部署要求
* python 3.8及以上版本
* pytorch 1.12及以上版本,推荐2.0及以上版本
* 建议使用CUDA 11.4及以上(GPU用户需考虑此选项)
## 快速使用
我们提供简单的示例来说明如何利用 🤖 ModelScope 和 🤗 Transformers 快速使用 Qwen-VL 和 Qwen-VL-Chat。
在开始前,请确保你已经配置好环境并安装好相关的代码包。最重要的是,确保你满足上述要求,然后安装相关的依赖库。
```bash
pip install -r requirements.txt
```
接下来你可以开始使用Transformers或者ModelScope来使用我们的模型。关于视觉模块的更多用法,请参考[教程](TUTORIAL_zh.md)。
#### 🤗 Transformers
如希望使用 Qwen-VL-chat 进行推理,所需要写的只是如下所示的数行代码。**请确保你使用的是最新代码。**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# 请注意:分词器默认行为已更改为默认关闭特殊token攻击防护。
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认gpu进行推理,需要约24GB显存
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 第一轮对话 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
# 第二轮对话 2st dialogue turn
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# [击掌](536,509),(588,602)
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('1.jpg')
else:
print("no box")
```

运行Qwen-VL同样非常简单。
运行Qwen-VL
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
# 默认gpu进行推理,需要约24GB显存
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': 'Generate the caption in English with grounding:'},
])
inputs = tokenizer(query, return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
print(response)
# ![]() https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpegGenerate the caption in English with grounding:
https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpegGenerate the caption in English with grounding:[ Woman](451,379),(731,806) and[ her dog](219,424),(576,896) playing on the beach<|endoftext|>
image = tokenizer.draw_bbox_on_latest_picture(response)
if image:
image.save('2.jpg')
else:
print("no box")
```

#### 🤖 ModelScope
魔搭(ModelScope)是开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品。使用ModelScope同样非常简单,代码如下所示:
```python
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
if not hasattr(tokenizer, 'model_dir'):
tokenizer.model_dir = model_dir
# use bf16
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# use auto
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 1st dialogue turn
# Either a local path or an url between ![]() tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'![]() {image_path}这是什么', history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
# 2st dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
#
{image_path}这是什么', history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
# 2st dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# ["击掌"](211,412),(577,891)
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('output_chat.jpg')
else:
print("no box")
```
## Demo
### Web UI
我们提供了Web UI的demo供用户使用。在开始前,确保已经安装如下代码库:
```
pip install -r requirements_web_demo.txt
```
随后运行如下命令,并点击生成链接:
```
python web_demo_mm.py
```
## FAQ
如遇到问题,敬请查阅 [FAQ](FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
## 使用协议
研究人员与开发者可使用Qwen-VL和Qwen-VL-Chat或进行二次开发。我们同样允许商业使用,具体细节请查看[LICENSE](LICENSE)。如需商用,请填写[问卷](https://dashscope.console.aliyun.com/openModelApply/qianwen)申请。
## 联系我们
如果你想给我们的研发团队和产品团队留言,请通过邮件(qianwen_opensource@alibabacloud.com)联系我们。