
Commit
•
6012fb6
1
Parent(s):
53f2ad3
Update README.md
Browse files
README.md
CHANGED
|
@@ -20,19 +20,20 @@ We evaluated model_51 on a wide range of tasks using [Language Model Evaluation
|
|
| 20 |
|
| 21 |
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 22 |
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|**Task**|**
|
| 26 |
-
|*
|
| 27 |
-
|*
|
| 28 |
-
|*
|
| 29 |
-
|*
|
| 30 |
-
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
Here is the prompt format
|
| 36 |
|
| 37 |
```
|
| 38 |
### System:
|
|
@@ -45,17 +46,34 @@ Tell me about Orcas.
|
|
| 45 |
|
| 46 |
```
|
| 47 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
Below shows a code example on how to use this model
|
| 49 |
|
| 50 |
```python
|
| 51 |
import torch
|
| 52 |
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
|
| 53 |
|
| 54 |
-
tokenizer = AutoTokenizer.from_pretrained("
|
| 55 |
model = AutoModelForCausalLM.from_pretrained(
|
| 56 |
-
"
|
| 57 |
torch_dtype=torch.float16,
|
| 58 |
-
|
| 59 |
low_cpu_mem_usage=True,
|
| 60 |
device_map="auto"
|
| 61 |
)
|
|
|
|
| 20 |
|
| 21 |
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 22 |
|
| 23 |
+
|||
|
| 24 |
+
|:------:|:--------:|
|
| 25 |
+
|**Task**|**Value**|
|
| 26 |
+
|*ARC*|0.6843|
|
| 27 |
+
|*HellaSwag*|0.8671|
|
| 28 |
+
|*MMLU*|0.6931|
|
| 29 |
+
|*TruthfulQA*|0.5718|
|
| 30 |
+
|*Winogrande*|0.8177|
|
| 31 |
+
|*GSM8K*|0.3237|
|
| 32 |
+
|*DROP*|0.5843|
|
| 33 |
+
|**Total Average**|**0.6488**|
|
| 34 |
|
| 35 |
|
| 36 |
+
### Prompt Foramt
|
|
|
|
|
|
|
| 37 |
|
| 38 |
```
|
| 39 |
### System:
|
|
|
|
| 46 |
|
| 47 |
```
|
| 48 |
|
| 49 |
+
#### OobaBooga Instructions:
|
| 50 |
+
|
| 51 |
+
This model required upto 45GB GPU VRAM in 4bit so it can be loaded directly on Single RTX 6000/L40/A40/A100/H100 GPU or Double RTX 4090/L4/A10/RTX 3090/RTX A5000
|
| 52 |
+
So, if you have access to Machine with 45GB GPU VRAM and have installed [OobaBooga Web UI](https://github.com/oobabooga/text-generation-webui) on it.
|
| 53 |
+
You can just download this model by using HF repo link directly on OobaBooga Web UI "Model" Tab/Page & Just use **load-in-4bit** option in it.
|
| 54 |
+
|
| 55 |
+
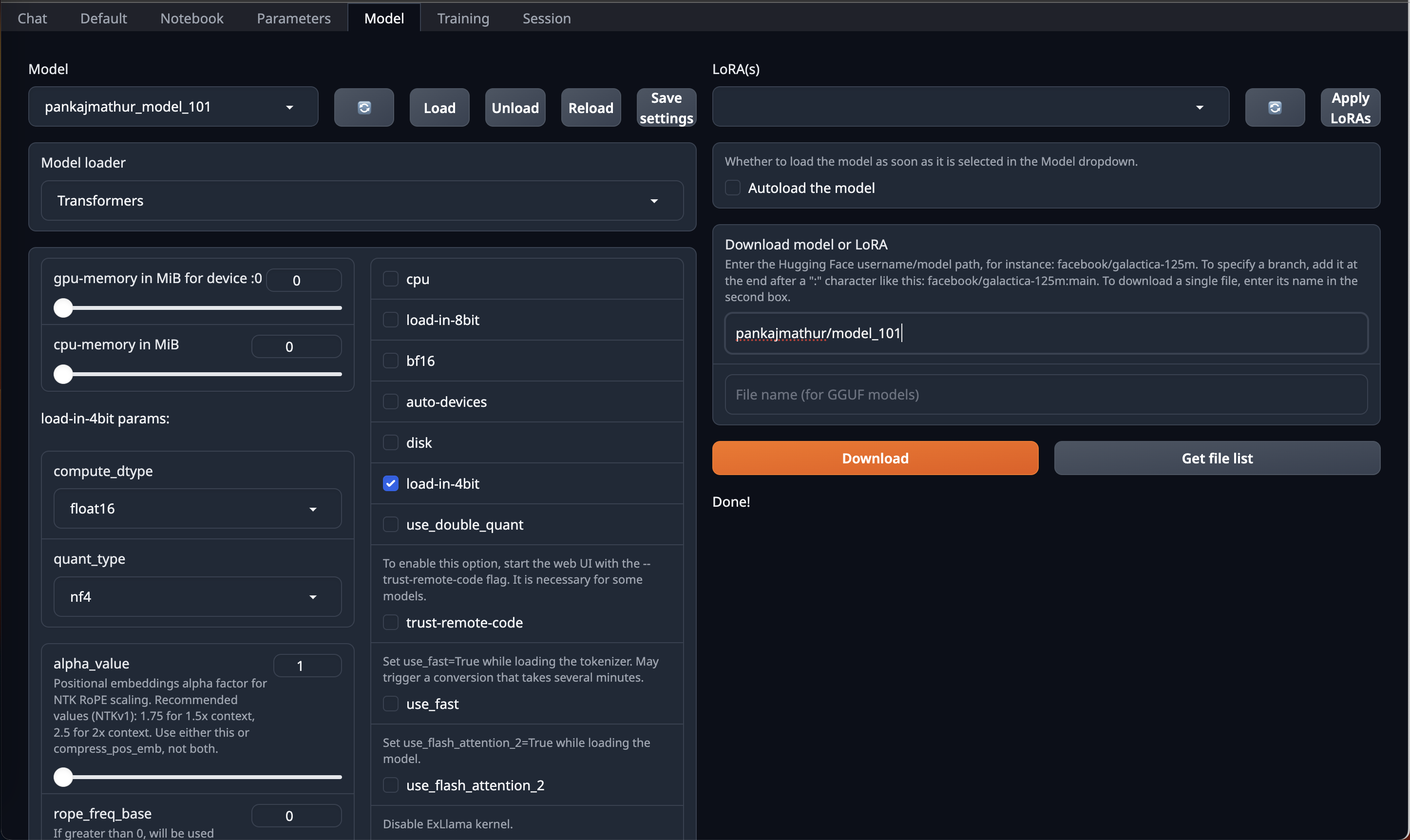
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
After that go to Default Tab/Page on OobaBooga Web UI and **copy paste above prompt format into Input** and Enjoy!
|
| 59 |
+
|
| 60 |
+
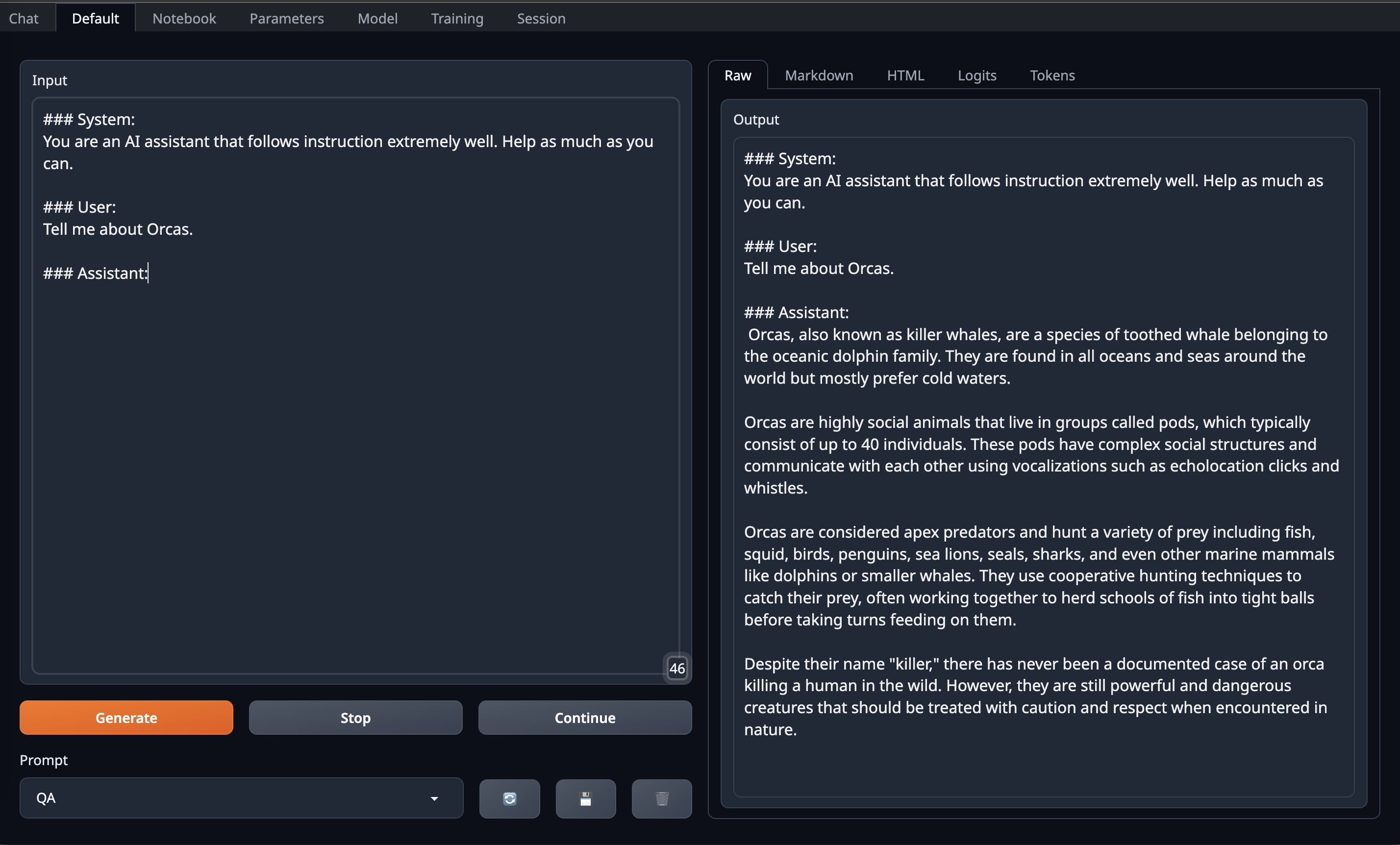
|
| 61 |
+
|
| 62 |
+
<br>
|
| 63 |
+
|
| 64 |
+
#### Code Instructions:
|
| 65 |
+
|
| 66 |
Below shows a code example on how to use this model
|
| 67 |
|
| 68 |
```python
|
| 69 |
import torch
|
| 70 |
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
|
| 71 |
|
| 72 |
+
tokenizer = AutoTokenizer.from_pretrained("pankajmathur/model_51")
|
| 73 |
model = AutoModelForCausalLM.from_pretrained(
|
| 74 |
+
"pankajmathur/model_51",
|
| 75 |
torch_dtype=torch.float16,
|
| 76 |
+
load_in_4bit=True,
|
| 77 |
low_cpu_mem_usage=True,
|
| 78 |
device_map="auto"
|
| 79 |
)
|